Jekyll2024-08-30T23:17:22+00:00http://greydanus.github.io/feed.xmlNatural IntelligenceA blog by Sam GreydanusSix Experiments in Action Minimization2023-03-12T06:50:00+00:002023-03-12T06:50:00+00:00http://greydanus.github.io/2023/03/12/ncf-six-experiments
.wrap {
max-width: 900px;
}
p {
font-family: sans-serif;
font-size: 16.75px;
font-weight: 300;
overflow-wrap: break-word; /* allow wrapping of very very long strings, like txids */
}
.post pre,
.post code {
background-color: #fafafa;
font-size: 14px; /* make code smaller for this post... */
}
pre {
white-space: pre-wrap; /* css-3 */
white-space: -moz-pre-wrap; /* Mozilla, since 1999 */
white-space: -pre-wrap; /* Opera 4-6 */
white-space: -o-pre-wrap; /* Opera 7 */
word-wrap: break-word; /* Internet Explorer 5.5+ */
}
The initial, highly-perturbed path for the three body problem.
Dynamics of the three bodies after action minimization.
In a recent post, we used gradient descent to find the path of least action for a free body. That this worked at all was interesting – but some important questions remain. For example: how well does this approach transfer to larger, more nonlinear, and more chaotic systems? That is the question we will tackle in this post.
In order to determine how action minimization works on more complex systems, we studied six systems of increasing complexity. The first of these was the free body, which served as a minimal working example, useful for debugging. The next system was a simple pendulum – another minimal working example, but this time with periodic nonlinearities and radial coordinates.
Once we had tuned our approach on these two simple systems, we turned our attention to four more complex systems: a double pendulum, the three body problem, a simple gas, and a real ephemeris dataset of planetary motion (the orbits were projected onto a 2D plane). These systems presented an interesting challenge because they were all nonlinear, chaotic, and high-dimensional.1 In each case, we compared our results to a baseline path obtained with a simple ODE solver using Euler integration.
The unconstrained energy effect
Early in our experiments we encountered the unconstrained energy effect. This happens when the optimizer converges on a valid physical path with a different total energy from the baseline. The figure below shows an example. The reason this happens is that, although we fix the initial and final states, we do not constrain the path’s total energy \(T+V\). Even though paths like the one shown below are not necessarily invalid, they make it difficult for us to recover baseline paths.
For this reason, we used the baseline ODE paths to initialize our paths, perturbed them with Gaussian noise, and then used early stopping to select for paths which were similar (often, identical) to the ODE baselines. This approach matched the mathematical ansatz of the “calculus of variations” where one studies perturbed paths in the vicinity of the true path. We note that there are other ways to mitigate this effect which don’t require an ODE-generated initial path.2
Results
On all six physical systems we obtained paths of least action which were nearly identical to the baseline paths. In the figure below you can also see the optimization dynamics. Our results suggest that action minimization can generate physically-valid dynamics even for chaotic and strongly-coupled systems like the double pendulum and three body problem. One interesting pattern we noticed was that optimization dynamics were dominated by the kinetic energy term \(T\). This occured because \(S\) tended to be more sensitive to \(T\) (which grew as \({\bf \dot{x}}^2\)) than \(V\).
Applications
The goal of this post was just to demonstrate that action minimization scales to larger problems. Nevertheless, we can’t help but take a moment to speculate on potential applications of this method:
ODE super-resolution. If one were to obtain a low-resolution trajectory via a traditional integration method such as Euler integration, one could then upsample the path by a factor of 10 to 100 (using, eg, linear interpolation) and then run action minimization to make it physically-valid. This procedure would take less time than using the ODE integrator alone.
Infilling missing data. Many real-world datasets have periods of missing data. These might occur due to a sensor malfunction, or they might be built into the experimental setup – for example, a satellite can’t image clouds and weather patterns as well at night – either way, action minimization is well-suited for inferring the sequence of states that connect a fixed start and end state. Doing this with an ODE integrator, meanwhile, is not as natural because there’s no easy way to incorporate the known end state into the problem definition.
When the final state is irrelevant. There are many simulation scenarios where the final state is not important at all. What really matters is that the dynamics look realistic in between times \(t_1\) and \(t_2\). This is the case for simulated smoke in a video game: the smoke just needs to look realistic. With that in mind, we could choose a random final state and then minimize the action of the intervening states. This could allow us to obtain realistic graphics more quickly than numerical methods that don’t fix the final state.
Discussion
Action minimization shows how the action really does act like a cost function. This isn’t something you’ll hear in your physics courses, even most high-level ones. And yet, it’s an elegant and accurate way to view physics. In a future post, we’ll see how this notion extends even into quantum mechanics.
Footnotes
The double pendulum and Lennard-Jones potentials were too long to fit into the table above. Here they are:
The state of the simple gas, for example, has a hundred degrees of freedom. ↩
]]>Sam Greydanus, Tim Strang, and Isabella CarusoFinding Paths of Least Action with Gradient Descent2023-03-05T12:00:00+00:002023-03-05T12:00:00+00:00http://greydanus.github.io/2023/03/05/ncf-tutorial
.wrap {
max-width: 900px;
}
p {
font-family: sans-serif;
font-size: 16.75px;
font-weight: 300;
overflow-wrap: break-word; /* allow wrapping of very very long strings, like txids */
}
.post pre,
.post code {
background-color: #fafafa;
font-size: 14px; /* make code smaller for this post... */
}
pre {
white-space: pre-wrap; /* css-3 */
white-space: -moz-pre-wrap; /* Mozilla, since 1999 */
white-space: -pre-wrap; /* Opera 4-6 */
white-space: -o-pre-wrap; /* Opera 7 */
word-wrap: break-word; /* Internet Explorer 5.5+ */
}
The purpose of this simple post is to bring to attention a view of physics which isn’t often communicated in introductory courses: the view of physics as optimization.
This approach begins with a quantity called the action. If you minimize the action, you can obtain a path of least action which represents the path a physical system will take through space and time. Generally speaking, physicists use analytic tools to do this minimization. In this post, we are going to attempt something different and slightly crazy: minimizing the action with gradient descent.
In this post. In order to communicate this technique as clearly and concretely as possible, we’re going to apply it to a simple toy problem: a free body in a gravitational field. Keep in mind, though, that it works just as well on larger and more complex systems such as an ideal gas – we will treat these sorts of systems in the paper and in future blog posts.
Now, to put our approach in the proper context, we’re going to quickly review the standard approaches to this kind of problem.
Standard approaches
The analytical approach. Here you use algebra, calculus, and other mathematical tools to find a closed-form equation of motion for the system. It gives the state of the system as a function of time. For an object in free fall, the equation of motion would be:
\[y(t)=-\frac{1}{2}gt^2+v_0t+y_0.\]
deffalling_object_analytical(x0,x1,dt,g=1,steps=100):v0=(x1-x0)/dtt=np.linspace(0,steps,steps+1)*dtx=-.5*g*t**2+v0*t+x0# the equation of motion
returnt,xx0,x1=[0,2]dt=0.19t_ana,x_ana=falling_object_analytical(x0,x1,dt)
The numerical approach. Not all physics problems have an analytical solution. Some, like the double pendulum or the three-body problem, are deterministic but chaotic. In other words, their dynamics are predictable but we can’t know their state at some time in the future without simulating all the intervening states. These we can solve with numerical integration. For the body in a gravitational field, here’s what the numerical approach would look like:
The Lagrangian method. The approaches we just covered make intuitive sense. That’s why we teach them in introductory physics classes. But there is an entirely different way of looking at dynamics called the Lagrangian method. The Lagrangian method does a better job of describing reality because it can produce equations of motion for any physical system.1 Lagrangians figure prominently in all four branches of physics: classical mechanics, electricity and magnetism, thermodynamics, and quantum mechanics. Without the Lagrangian method, physicists would have a hard time unifying these disparate fields. But with the Standard Model Lagrangian they can do precisely that.
How it works. The Lagrangian method begins by considering all the paths a physical system could take from an initial state \(\bf{x}\)\((t_0)\) to a final state \(\bf{x}\)\((t_1)\). Then it provides a simple rule for selecting the path \(\hat{\bf x}\) that nature will actually take: the action \(S\), defined in the equation below, must have a stationary value over this path. Here \(T\) and \(V\) are the kinetic and potential energy functions for the system at any given time \(t\) in \([t_0,t_1]\).
\[\begin{aligned}
S &:= \int_{t_0}^{t_1} L({\bf x}, ~ \dot{\bf x}, ~ t) ~ dt\\
&\quad \textrm{where}\quad L = T - V \\
\quad \hat{\bf x} &~~ \textrm{has property}~ \frac{d}{dt} \left( \frac{\partial L}{\partial \dot{\hat{x}}(t)} \right) = \frac{\partial L}{\partial \hat{x}(t)} \\
&\textrm{for} \quad t \in [t_0,t_1]
\end{aligned}\]
Finding \(\hat{\bf x}\) with Euler-Lagrange (what people usually do). When \(S\) is stationary, we can show that the Euler-Lagrange equation (third line in the equation above) holds true over the interval \([t_0,t_1]\) (Morin, 2008). This observation is valuable because it allows us to solve for \(\hat{\bf x}\): first we apply the Euler-Lagrange equation to the Lagrangian \(L\) and derive a system of partial differential equations.2 Then we integrate those equations to obtain \(\hat{\bf x}\). Importantly, this approach works for all problems spanning classical mechanics, electrodynamics, thermodynamics, and relativity. It provides a coherent theoretical framework for studying classical physics as a whole.
Finding \(\hat{\bf x}\) with action minimization (what we are going to do). A more direct approach to finding \(\hat{\bf x}\) begins with the insight that paths of stationary action are almost always also paths of least action (Morin 2008). Thus, without much loss of generality, we can exchange the Euler-Lagrange equation for the simple minimization objective shown in the third line of the equation below. Meanwhile, as shown in the first line, we can redefine \(S\) as a discrete sum over \(N\) evenly-spaced time slices:
One problem remains: having discretized \( \hat{\bf{x}} \) we can no longer take its derivative to obtain an exact value for \( \dot{\bf{x}}(t_i) \). Instead, we must use the finite-differences approximation shown in the second line. Of course, this approximation will not be possible for the very last \( \dot{\bf{x}} \) in the sum because \(\dot{\bf{x}}_{N+1}\) does not exist. For this value we will assume that, for large \(N\), the change in velocity over the interval \( \Delta t \) is small and thus let \(\dot{\bf{x}}_N = \dot{\bf{x}}_{N-1}\). Having made this last approximation, we can now compute the gradient \(\frac{\partial S}{\partial \bf{x}}\) numerically and use it to minimize \(S\). This can be done with PyTorch (Paszke et al, 2019) or any other package that supports automatic differentiation.
A simple implementation
Let’s begin with a list of coordinates, x, which contains all the position coordinates of the system between t\(_1\) and t\(_2\). We can write the Lagrangian and the action of the system in terms of these coordinates.
Now let’s look for a point of stationary action. Technically, this could be a minimum OR an inflection point.3 Here, we’re just going to look for a minimum:
defget_path_between(x,steps=1000,step_size=1e-1,dt=1,num_prints=15,num_stashes=80):t=np.linspace(0,len(x)-1,len(x))*dtprint_on=np.linspace(0,int(np.sqrt(steps)),num_prints).astype(np.int32)**2# print more early on
stash_on=np.linspace(0,int(np.sqrt(steps)),num_stashes).astype(np.int32)**2xs=[]foriinrange(steps):grad_x=torch.autograd.grad(action(x,dt),x)[0]grad_x[[0,-1]]*=0# fix first and last coordinates by zeroing their gradients
x.data-=grad_x*step_sizeifiinprint_on:print('step={:04d}, S={:.4e}'.format(i,action(x,dt).item()))ifiinstash_on:xs.append(x.clone().data.numpy())returnt,x,np.stack(xs)
Now let’s put it all together. We can initialize our falling particle’s path to be any random path through space. In the code below, we choose a path where the particle bounces around x=0 at random until time t=19 seconds, at which point it leaps up to its final state of x = x_num[-1] = 21.3 meters. This path has a high action of S = 5425 J·s. As we run the optimization, this value decreases smoothly until we converge on a parabolic arc with an action of S = -2500 J·s.
dt=0.19x0=1.5*torch.randn(len(x_num),requires_grad=True)# a random path through space
x0[0].data*=0.0;x0[-1].data*=0.0# set first and last points to zero
x0[-1].data+=x_num[-1]# set last point to be the end height of the numerical solution
t,x,xs=get_path_between(x0.clone(),steps=20000,step_size=1e-2,dt=dt)
Direct comparison between the numerical (ODE) solution and our approach
On the left side of the figure below, we compare the normal approach of ODE integration to our approach of action minimization. As a reminder, the action is the sum, over every point in the path, of kinetic energy \(T\) minus potential energy \(V\). We compute the gradients of this quantity with respect to the path coordinates and then deform the initial path (yellow) into the path of least action (green). This path resolves to a parabola, matching the path obtained via ODE integration. On the right side of the figure, we plot the path’s action \(S\), kinetic energy \(T\), and potential energy \(V\) over the course of optimization. All three quantities asymptote at the respective values of the ODE trajectory.
Closing thoughts
As if by snake-charming magic, we have coaxed a path of random coordinates to make a serpentine transition into a structured and orderly parabolic shape – the shape of the one trajectory that a free body will take under the influence of a constant gravitational field. This is a simple example, but we have investigated it in detail because it is illustrative of the broader “principle of least action” which defies natural human intuition and sculpts the very structure of our physical universe.
By the vagueness of its name alone, “the action,” you may sense that it is not a well-understood phenomenon. In subsequent posts, we will explore how it works in more complex classical simulations and then, later, in the realm of quantum mechanics. And after that, we will talk about its history: how it was discovered and what its discoverers thought when they found it. And most importantly, we will address the lingering speculations as to what, exactly, it means.
Footnotes
Tim informs me that there are some string theories that can’t be lagranged. So in the interest of precision, I will narrow this claim to cover all physical systems that have been observed experimentally. ↩
That’s why the whole method is often called The Principle of Least Action, a misnomer which I (and others) have picked up by reading the Feynman lectures. ↩
]]>Sam Greydanus, Tim Strang, and Isabella CarusoStudying Growth with Neural Cellular Automata2022-05-24T06:50:00+00:002022-05-24T06:50:00+00:00http://greydanus.github.io/2022/05/24/studying-growth
Growing flowers. The pixels in the images above represent cells. By exchanging signals with their neighbors, these cells coordinate their behavior and assemble themselves in the shapes of the three flowers shown.
How does a single fertilized egg grow into a population of seventy trillion cells: a population that can walk, talk, and write sonnets? This is one of the great unanswered questions of biology. We may never finish answering it, but it is a productive question nonetheless. In asking it, scientists have discovered the structure of DNA, sequenced the human genome, and made essential contributions to modern medicine.
In this post, we will explore this question with a new tool called Neural Cellular Automata (NCA).
Motivation
The purpose of cellular automata (CA) writ large is to mimic biological growth at the cellular level. Most CAs begin with a grid of pixels where each pixel represents a different cell. Then a set of growth rules, controlling how cells respond to their neighbors, are applied to the population in an iterative manner. Although these growth rules are simple to write down, they are choosen so as to produce complex self-organizing behaviors. For example, Conway’s Game of Life has just three simple growth rules that give rise to a diverse range of structures.1
Classic versions of cellular automata like Conway’s Game of Life are interesting because they produce emergent behavior starting from simple rules. But in a way, these versions of CA are too simple. Their cells only get to have two states, dead or alive, whereas biological cells get to have a near-infinite number of states, states which are determined by a wide variety of signaling molecules. We refer to these molecules as morphogens because they work together to control growth and guide organisms towards specific final shapes or morphologies.
Neural CA. Based on this observation, we should move away from CA with cells that are only dead or alive. Instead, we should permit their cells to exist in a variety of states with each state defined by a list of continuous variables. Growth rules should operate on combinations of these variables in the same way that biological growth rules operate on combinations of different morphogens. And unlike Conway’s Game of Life, the self-organizing behaviors that arise should not be arbitrary or chaotic. Rather, they should involve stable convergence to specific large-scale morphologies like those that occur in biology. Much more complex growth rules are needed for this to occur.
The diagram above shows how NCA take a step in the right direction. Unlike regular cellular automata, they represent each cell state with a real-valued \(n\)-dimensional vector and then allow arbitrary growth rules to operate on that domain. They do this by parameterizing growth rules with a neural network and then optimizing the neural network to obtain the desired pattern of growth. To showcase the model’s expressivity, the authors trained it to arrange a population of a 1600 cells in the shape of a lizard starting from local-only interactions between initially identical cells.
NCA diagram. The diagram above how a neural network can be used to parameterize the growth rules of a cellular autiomata. The original NCA article uses this diagram to introduce the model and its training procedure.
Getting started
The authors of the original paper released a Colab notebook that showed how to implement NCA in TensorFlow. Starting from this notebook, we reimplemented everything in PyTorch and boiled it down to a minimalist, 150-line implementation. Our goal was to make the NCA model as simple as possible so that we could hack and modify it without getting overwhelmed by implementation details.
Having implemented our own NCA model, the next step was to scale it to determine the maximum size and complexity of the “organisms” it could produce. We found that the population size was going to be limited by the amount of RAM available on Google Colab GPUs. We maxed things out with a population of about 7500 cells running for about 100 updates. For context, the original paper used a population of 1600 cells running for 86 updates.
Working in this scaled-up regime, we trained our NCA to grow a number of different flowers. Some of the early results were a bit mangled and blurry. Many were biased towards radial symmetry and required extra training in order to reveal symmetric features such as individual petals. But soon, after a few hyperparameter fixes, our NCA was able to grow some “HD” 64x64 flowers:
Having implemented the NCA model and gained some intuition for how it trained, we were ready to use it to investigate patterns of biological growth.
Patterns of biological growth
Biological growth is wonderfully diverse. Consider this passage from the first chapter of Growth by Life Science Library:
A eucalyptus native to Uganda has been known to grow 45 feet in two years, whereas dwarf ivy generally grows one inch a year. The majestic sequoia of California, which starts out as a seed weighing only one three-thousandth of an ounce, may end up… [with a] weight estimated at 6,200 tons. It takes more than 1,000 years for the sequoia to achieve the feat of multiplying 600 billion times in mass.
The animal kingdom, too, has its champions of growth. The blue whale, which cruises the oceans from the North to the South Pole, begins life as a barely visible egg weighing only a fraction of an ounce. At birth, it weighs from two to three tons. When it is weaned, at about seven months, it is 52 feet long and weighs 23 tons, having gained an average of 200 pounds a day.
Given the diversity of life forms on our planet, maybe one of the biggest surprises is how much they have in common. For the most part they share the same genetic materials, signaling mechanisms, and metabolic pathways. Their cells have the same life cycles. Indeed, the cellular mechanics in a gnat look pretty similar to those in a blue whale…even though the creatures themselves could not be more different.
One shared pattern of growth is called gnomonic growth. This pattern tends to occur when an organism needs to increase in size and part of its body is defined by a rigid structure. You can see this in clams, for example. Their shells are rigid and cannot be deformed. And yet they need to grow their shells as the rest of them grows. Clams solve this problem by incrementally adding long crescent-shaped lips to the edges of their shells. Each new lip is just a little larger than the one that came before it. These lips, or gnomons as they are called, permit organisms to increase in size without changing form. Gnomons also appear in horns, tusks, and tree trunks.
One of the most famous products of gnomonic growth is the nautilus shell. In this shell, the gnomons grow with such regularity that the overall shape can be modeled with a simple Fibonacci sequence. The elegance and simplicity of the pattern makes it an interesting testbed for NCA.
To set up this problem, we split the shell into three regions: frozen, mature, and growing. These regions are shown in cyan, black and magenta respectively:
The cells in the frozen region are, as the name would suggest, frozen. Both their RGBA and hidden channels are fixed throughout training. The cells in the mature region are similar; the only difference is that their hidden channels are allowed to change. The growing region, meanwhile, begins the simulation without any living cells. Cells from the mature region need to grow outwards into this area and arrange themselves properly before the simulation ends.
Scale and rotation invariance. Part of the objective in this “gnomonic growth” problem is to learn a growth rule that is scale and rotation invariant. We can accomplish this by rotating and scaling the nautilus template as shown in the six examples above. By training on all of these examples at once, we are able to obtain a model that grows properly at any scale or orientation. Once it learns to do this, it can grow multiple gnomons, one after the other, without much interference. Below, for example, we add eight new compartments and quadruple the shell’s size by letting the NCA run for eight growth cycles.2
One of the things that makes this growth pattern interesting is that the NCA cells have to reach a global consensus as to what the scale and rotation of the mature region is. Only by agreeing on this are they able to construct a properly-sized addition. And yet in practice, we see that expansion into the growth region begins from the first simulation step. This suggests that cells in the mature region try to come to a distributed consensus as to the target shape even as new cells are already beginning to grow that shape. Once cells in the mature region know the proper scale and rotation of the gnomon, they transmit this information to the growing region so that it can make small adjustments to its borders. If you look closely, you can see these adjustments happening in the video below.
This process of reaching a consensus in a decentralized and asynchronous manner is a common problem for biological cells. In fact, we already touched on it in our Self-classifying MNIST Digits post. It’s also important in human organizations: from new cities agreeing on development codes, to democratic institutions agreeing on legislation, to the stock market agreeing on how to value companies. It is not always a low-entropy process.
Indeed, sometimes groups of cells have to resort to other means of reaching consensus…
The alternative to a fully decentralized consensus mechanism is cellular induction. This happens when one small group of cells (usually in an embryo) tells the rest how to grow. The first group of cells is called the inducing tissue and the second is called the responding tissue. Induction controls the growth of many tissues and organs including the eye and the heart.
In this section, we will grow an image of a newt and then graft part of its eye tissue onto its belly. After doing this, we will watch to see whether those cells are able to induce growth in the rest of the eye in that region. We’ve chosen this particular experiment as an homage to Hans Spemann,3 who won the Nobel Prize for Medicine in 1935 for using similar experiments on real newts to discover “the organizer effect in embryonic development.”4 Spemann’s major insight was that “at every stage of embryonic development, structures already present act as organizers, inducing the emergence of whatever structures are next on the timetable.”5
To reproduce this effect, we first trained an NCA to grow a picture of a newt. Once the growth phase was complete, we grafted a patch of cells from its head onto its stomach. This patch of cells included the upper, light-colored portion of the newt’s eye but not the dark-colored, lower portion. Then we froze their states and allowed the rest of the cells to undergo updates as usual. Within 25 steps, the stomach cells below the grafted patch had regrown into a dark-colored strip to complete the lower half of the new eye.
Cellular induction offers a simple explanation for how many growth rules are implemented: by and large, they are implemented as if-then statements. For example, “If I am growing below some light-colored eye tissue, then I should be black-colored eye tissue.” Early in embryonic development, these if-then statements are very general: “If I am on the outside layer of the embryo, then I am going to be an ectoderm cell. Else, if I am on the inside layer of the embryo, then I am going to be a mesoderm cell. Else, if I am in the center of the embryo, then I am going to be an endoderm cell.”
As development progresses, these branching milestones occur dozens of times, each time causing a group of cells to become more specialized. Towards the end of development, the branching rules might read, “If I am an ectoderm cell and if I am a nervous system cell and if I am an eye cell and if I am distal to the optic nerve then I am going to be part of the corneal epithelium.”
Attractor theory of development. While this sounds complex, it’s actually the simplest and most robust way to construct a multicellular organism. Each of these branching statements determines how morphogenesis unfolds at a different hierarchy of complexity. Unlike a printer, which has to place every dot of ink on a page with perfect precision, a growing embryo doesn’t need to know the final coordinates of every mature adult cell. Moreover, it can withstand plenty of noise and perturbations at each stage of development and still produce an intricate, well-formed organism in the end.6 Intuitively, this is possible because during each stage of growth, clusters of cells naturally converge to target “attractor” states in spite of perturbations. Errors get corrected before the next stage of growth begins. And in the next stage, new attractor states perform error-correction as well. In this way, embryonic induction allows nature to construct multicellular organisms with great reliability, even in a world full of noise and change.
Death to form the living. One of the most dramatic if-then statements is “If I am in state x, then I must die.” This gives rise to what biologists call apoptosis, or programmed cell death. Apoptosis is most common when an organism needs to undergo a major change in form: for example, a tadpole losing its tail as it grows into a frog, or a stubby projection in a chick embryo being sculpted into a leg.
Left. The metamorphosis of a tadpole into a frog is a spectacular example of apoptosis. Soon after the tadpole's tail reaches full size, the frog's back legs begin to grow and the tail rapidly shrinks. In the span of a few months it vanishes entirely. Right. A blue dye that stains only dead cells is applied to a four-year-old chick embryo, revealing apoptosis in the wing and foot buds. These cells are programmed to die at an appointed time in order to shape the wings and feet of the newborn chick (see white circles). Even if these cells are moved to another part of the embryo, they still die at the appointed time. Photo credit: Growth from the LIFE Science Library.
One of the best examples of apoptosis in the human body is bone remodeling. This is the process by which bones grow, change shape, and even regrow after a fracture. It’s also a process by which the body manages the supply of important minerals and nutrients such as calcium. In the first year of life, bone resorption proceeds at an especially rapid pace. By the end of that year, almost 100% of the skeleton has been absorbed and replaced.
Even in adults, about 10% of the skeleton is replaced every year.
In this experiment, we trained an NCA model to grow into the shape of a slice of human bone. Since the bone starts its growth in the center of the image, but the center of the target image is empty, the NCA naturally learns a growth pattern that resembles apoptosis. Early in development, a small tan circle forms. The outside edge of this circle expands rapidly outward in a pattern of “bone growth” that would be carried out by osteoblasts in nature. Meanwhile, the inside edge of the circle deteriorates at the same rate in a pattern of “bone resorption” associated with osteoclasts in nature.
We have remarked that gnats and blue whales have more in common, at least in terms of cellular mechanics, than one would guess. They share many of the same cell structures, protiens, and even stages of development like gastrulation. This points to the fact that many different organisms share the same cellular infrastructure. In more closely-related species, this observation is even more apt. For example, the three flowers we grew at the beginning of the article – the rose, the marigold, and the crocus – are all angiosperms and thus share structures like the xylem and phloem.
Indeed, one of the biggest differences between these flowers is their genetic code. Making an analogy to computers, you might say that they have the same hardware (cell mechanics), but different software (DNA).
Our final experiment uses NCA to explore this idea. We run the same cellular dynamics (NCA neural network weights) across several flowers while varying the genetic information (initial state of the seed cell). Our training objective involved three separate targets: the rose, the marigold, and the crocus, each with its own trainable “seed state.” Early in training, our model produced blurry flower-like images with various mixtures of red, yellow, and purple. As training progressed, these images diverged from one another and began to resemble the three target images.
Even though the final shapes diverge, you can still see shared features in the “embryonic” versions of the flowers. If you watch the video below, you can see that the three “embryos” all start out with red, yellow, and purple coloration. The developing crocus, in particular, has both red and purple petals during growth steps 10-20.
From a dynamical systems perspective, this NCA model has three different basins of attraction, one for each flower. The initial seed determines which basin the system ultimately converges to. In the future, it would be interesting to train a model that produces a wider variety of final organisms. Then we could use its “DNA” vectors to construct a “tree of life,” showing how closely-related various organisms are7 and at what point in training they split from a common ancestor.
Final remarks
There are a number of ways that NCA can contribute to civilization. The prospect of isolating the top one hundred signaling molecules used in natural morphogenesis, tracking their concentrations during growth in various tissues, and then training an NCA to reproduce the same growth patterns with the same morphogens is particularly exciting. This would allow us to obtain a complex model of biological morphogenesis with some degree of predictive power. Such a model could allow us to solve for the optimal cocktail of signaling molecules needed to speed up, slow down, or otherwise modify cell growth. It could even be used to adversarially slow down the growth of cancerous cells in a patient with cancer or artificially accelerate the growth of bone cells in a patient with osteoporosis.
One of the themes of this post is that patterns of growth are surprisingly similar across organisms. This hints at the fact that there are principles of growth that transcend biology. These principles can be studied in a computational substrate in a way that gives useful insights about the original biological systems. These insights, we believe, shine a new light on the everyday miracle of growth.
Footnotes
In fact, Conway’s Game of Life is Turing Complete; it can be used to simulate computations of arbitrary complexity. It can even be used to simulate itself. ↩
Out only interference is to convert growin regions to mature regions and mature regions to frozen regions every 160 steps. This causes the system to move on to the next unit of growth. ↩
There’s probably an analogy to be made to fourier analysis where the spatial modes are reconstructed in order of their principal components. Like decompressing a .JPEG file. ↩
These “organisms” are actually images of organisms in this context. ↩
]]>Sam GreydanusA Structural Optimization Tutorial2022-05-08T11:00:00+00:002022-05-08T11:00:00+00:00http://greydanus.github.io/2022/05/08/structural-optimization
.wrap {
max-width: 900px;
}
p {
font-family: sans-serif;
font-size: 16.75px;
font-weight: 300;
overflow-wrap: break-word; /* allow wrapping of very very long strings, like txids */
}
.post pre,
.post code {
background-color: #fafafa;
font-size: 14px; /* make code smaller for this post... */
}
pre {
white-space: pre-wrap; /* css-3 */
white-space: -moz-pre-wrap; /* Mozilla, since 1999 */
white-space: -pre-wrap; /* Opera 4-6 */
white-space: -o-pre-wrap; /* Opera 7 */
word-wrap: break-word; /* Internet Explorer 5.5+ */
}
Causeway bridge. When you play the video, you'll notice that initially the matter is evenly distributed over the design space. From there, we iteratively move it around so as to create a structure that optimally supports a set of forces and fixed points (not shown). The result is a causeway bridge design.
Structural optimization is a useful and interesting tool. Unfortunately, it can be hard to get started on the topic because existing tutorials assume the reader has substantial domain knowledge. They obscure the fact that structural optimization is really quite simple, elegant, and easy to implement.
With that in mind, let’s write our own structural optimization code, from scratch, in 180 lines.
Problem setup
The goal of structural optimization is to place material in a design space so that it rests on some fixed points or “normals” and resists a set of applied forces or loads as efficiently as possible. To see how we might set this up, let’s start with a beam design problem from Andreassen et al (2010):
The large gray rectangle here represents the design space. We are going to enforce symmetry by optimizing half of the beam and then mirroring the result around the left wall. This means that the center of the beam is actually on the left side of the diagram. This is where the load force, denoted by the downwards-pointing arrow, is being applied. There are horizontally fixed points here as well. They represent forces transmitted to this half of the beam from its other half. Meanwhile, the vertically fixed point at the bottom right corner of the design space corresponds to a normal force from some external support, perhaps the top of a wall.
Finite elements. Although the physics of elastic materials is continuous, our computer can only work with discrete approximations. This means that we have to cut the design space up into a discrete number of regions or finite elements which, when allowed to interact, reproduce the behavior of an elastic solid as realistically as possible. We can link their boundaries together with a set of nodes and allow these nodes to interact with one another as though connected by springs. This way, whenever a force is applied to one node, it transmits a fraction of that force on to all the other nodes in the structure, causing each to move a small amount and, in doing so, deform the finite elements. As this happens, the entire structure deforms as though it were an elastic solid.
There are many ways to choose the arrangement of these finite elements. The simplest one is to make them square and organize them on a rectangular grid.
In the diagram above, there are 12 elements with four nodes per element and two degrees of freedom (DOFs) per node. The first is horizontal and the second is vertical. The numbering scheme proceeds columnwise from left to right so that the horizontal and vertical displacements of node \(n\) are given by DOFs \(2n-1\) and \(2n\) respectively. As the authors point out, this grid structure is useful because it can be exploited “…in order to reduce the computational effort in the optimization loop…” It also simplifies the code.
Python representations. Given this problem setup, every DOF in our design space can either have a force applied to it or be fixed by a normal force. For a design space that is \(y\) units high and \(x\) units wide, we can represent these parts of the problem setup with NumPy arrays called forces and normals, each of shape \((y+1,x+1,2)\). Here the first two axes index over all the nodes in the design space and the third axis indexes over the two DOFs available to each node. Starting with the code below – and continuing throughout the rest of this tutorial – we are going to flatten these arrays to one dimension.
There are a few other important details. The mask variable can be either a scalar of value 1 (no mask) or an array of shape \((x,y)\). As a default, we will use no mask. Then there are all the material constants, constraints, filter widths, and so forth to consider. For these, we use the values reported by Andreassen et al. (2010). Finally, we have the mbb_beam function which sets up the forces and normals particular to the MBB beam design constraints. This function can easily be swapped out if we wish to design a structure with different constraints.
classObjectView(object):def__init__(self,d):self.__dict__=ddefget_args(normals,forces,density=0.4):# Manage the problem setup parameters
width=normals.shape[0]-1height=normals.shape[1]-1fixdofs=np.flatnonzero(normals.ravel())alldofs=np.arange(2*(width+1)*(height+1))freedofs=np.sort(list(set(alldofs)-set(fixdofs)))params={# material properties
'young':1,'young_min':1e-9,'poisson':0.3,'g':0,# constraints
'density':density,'xmin':0.001,'xmax':1.0,# input parameters
'nelx':width,'nely':height,'mask':1,'penal':3.0,'filter_width':1,'freedofs':freedofs,'fixdofs':fixdofs,'forces':forces.ravel(),# optimization parameters
'opt_steps':80,'print_every':10}returnObjectView(params)defmbb_beam(width=80,height=25,density=0.4,y=1,x=0):# textbook beam example
normals=np.zeros((width+1,height+1,2))normals[-1,-1,y]=1normals[0,:,x]=1forces=np.zeros((width+1,height+1,2))forces[0,0,y]=-1returnnormals,forces,density
Visualizing the normals and forces in the MBB beam setup. Here the rectangle represents the design area and the colored pixels represent matrix entries (blue = -1, green = 0, and yellow = 1).
The density method. Now that we have parameterized the design space, it is time to parameterize the material that moves around on it. At a high level, each finite element is going to have a certain density of material, given by some number between 0 and 1. We will use this density to determine the element stiffness coefficient \(E_e\), also called Young’s modulus. In the nodes-connected-by-springs analogy, this coefficient would control all the spring constants.
Let’s discuss how to choose the mapping between finite element density \(x_e\) and Young’s modulus in more detail. First of all, we’d like to avoid having any elements with zero stiffness. When this happens, they stop transmitting forces to their neighbors before optimization is complete and we are liable to end up with suboptimal solutions. We can prevent this by giving each finite element a baseline stiffness, \(E_{min}\), regardless of whether it has any material density.
We’d also like black-and-white final solutions. In other words, although our design space may start out with material densities of 0.5, by the end of optimization we’d like all of the grid cells to have densities very close to either 0 or 1. We can ensure this happens by raising our densities to a power \(p\) greater than one (typically \(p=3\)) so as to make our structure’s stiffness more sensitive to small changes in density.
Putting these ideas together, we obtain the “modified SIMP” equation from Andreasson et al. (2010):
Here \(E_0\) is the stiffness of the material. For a comparison between modified SIMP and other approaches, see Sigmund (2007).
Filtering. Finally, in order to avoid grid-level pathologies (especially scenarios where a grid element with full density ends up next to a grid element with zero density and a discontinuity occurs), we are going to use a 2D Gaussian filter1 to smooth the grid densities. This technique, called “filtering,” shows up in almost all physics simulations where continuous fields have to be discretized.
defyoung_modulus(x,e_0,e_min,p=3):returne_min+x**p*(e_0-e_min)defphysical_density(x,args,volume_contraint=False,use_filter=True):x=args.mask*x.reshape(args.nely,args.nelx)# reshape from 1D to 2D
returngaussian_filter(x,args.filter_width)ifuse_filterelsex# maybe filter
defmean_density(x,args,volume_contraint=False,use_filter=True):returnanp.mean(physical_density(x,args,volume_contraint,use_filter))/anp.mean(args.mask)
At this point, we have constructed a finite element parameterization of an elastic solid. We are applying forces to this solid in some places and supporting it with fixed points in others. As it deforms, it stretches and compresses in proportion to the stiffness of its finite elements. Now the question we need to ask is: what does the best structure look like under these conditions?
The objective function
At a high level, the best structure is the one that minimizes the elastic potential energy or compliance of the 2D grid of springs. We can express this idea mathematically as follows:
\(\begin{align}
\scriptstyle \underset{\mathbf{x}}{\textrm{min}}: & \quad \scriptstyle c(\mathbf{x}) ~~=~~ \mathbf{U}^T\mathbf{K}\mathbf{U} ~~=~~ \sum_{e=1}^NE_e(x_e)\mathbf{u}_e^T\mathbf{k}_0\mathbf{u}_e \\
\scriptstyle \textrm{subject to}: & \quad \scriptstyle V(\mathbf{x})/V_0 = f \\
\scriptstyle & \quad \scriptstyle 0 \leq \mathbf{x} \leq 1 \\
\scriptstyle & \quad \scriptstyle \mathbf{KU=F} \\
\end{align}\)
\(\begin{align}
\scriptstyle \underset{\mathbf{x}}{\textrm{min}}: & \quad \scriptstyle c(\mathbf{x}) ~~=~~ \mathbf{U}^T\mathbf{K}\mathbf{U} ~~=~~ \sum_{e=1}^NE_e(x_e)\mathbf{u}_e^T\mathbf{k}_0\mathbf{u}_e \qquad \textrm{Potential energy (compliance) of a 2D grid of springs} \\
\scriptstyle \textrm{subject to}: & \quad \scriptstyle V(\mathbf{x})/V_0 = f \qquad \quad ~ \textrm{A fixed quantity of material} \\
\scriptstyle & \quad \scriptstyle 0 \leq \mathbf{x} \leq 1 \qquad \qquad \textrm{Densities that remain between 0 and 1} \\
\scriptstyle & \quad \scriptstyle \mathbf{KU=F} \qquad \qquad \textrm{Hooke's law for a 2D grid of springs} \\
\end{align}\)
Here \(c\) is the compliance, \(\mathbf{x}\) is a vector containing the material densities of the elements, \(\mathbf{K}\) is the global stiffness matrix, \(\mathbf{U}\) is a vector containing the displacements of the nodes, and \(E_e\) is Young’s modulus. The external forces or “loads” are given by the vector \(\mathbf{F}\).
We can write the core part of this objective, the part that says \(c(\mathbf{x})=\mathbf{U}^T\mathbf{K}\mathbf{U}\), as a high-level objective function that calls a series of subroutines.
The objective function gives us a single number, \(c(\mathbf{x})\), which we can use to rate the quality of our structure. But the question remains: how should we update \(\mathbf{x}\) so as to minimize this number? To answer this question, we need to compute the gradients or sensitivities of \(c\) with respect to \(\mathbf{x}\). These sensitivities will give us the direction to move \(\mathbf{x}\) in order to decrease \(c\) as much as possible. Ignoring filtering for a moment and applying the chain rule to the first line of the objective function, we obtain
If we want to add filtering back in, the notation becomes a bit more complicated. But we’re not going to do that here because, actually, we don’t need to calculate these sensitivities by hand. There is an elegant little library called Autograd which can do this for us using a process called automatic differentiation.
Custom gradients. There are a few cases where we need to operate on NumPy arrays with functions from other libraries. In these cases, we need to define a custom gradient function so that Autograd knows how to differentiate through them. For example, in the code we have already written, the gaussian_filter function comes from the scipy library. Here’s how we can wrap that function to make it work properly with Autograd:
@autograd.extend.primitivedefgaussian_filter(x,width):# 2D gaussian blur/filter
returnscipy.ndimage.gaussian_filter(x,width,mode='reflect')def_gaussian_filter_vjp(ans,x,width):# gives the gradient of orig. function w.r.t. x
delans,x# unused
returnlambdag:gaussian_filter(g,width)autograd.extend.defvjp(gaussian_filter,_gaussian_filter_vjp)
Implementing the physics
In between \(\mathbf{x}\) and \(c(\mathbf{x})\), there are a series of physics functions that we still need to implement.
Compliance. At a high level, the compliance is just \(\mathbf{U}^T\mathbf{K}\mathbf{U}\). But \(\mathbf{U}\) and \(\mathbf{K}\) are very sparse so it’s much more efficient to calculate \(\sum_{e=1}^NE_e(x_e)\mathbf{u}_e^T\mathbf{k}_0\mathbf{u}_e\). That’s what we will do in the code below. It’s a little hard to follow because everything is vectorized (hence the einsums) but this does speed things up considerably compared to a for loop.
The element stiffness matrix. The variable \(\mathbf{k}_0\) that appears in the compliance calculation is called the element stiffness matrix. An intuitive way to think about this matrix is as a 2D analogue of the spring constant \(k\) in a simple harmonic oscillator. The reason it is a matrix (instead of a scalar or a vector) is that we need to take into account all of the various interaction terms between the corner nodes in a square finite element.2 When we represent the displacement of all these nodes with a vector \(u=[u^a_1,u^a_2,u^b_1,u^b_2,u^c_1,u^c_2,u^d_1,u^d_2]\), then it becomes easy to calculate the potential energy of the system: we just write \(PE = \frac{1}{2}u^Tk_0u\) (this is the 2D analogue to the potential energy of a 1D harmonic oscillator, which is written as \(\frac{1}{2}kx^2\)).
From this you should be able to see why compliance is the potential energy of the entire structure: it’s just a sum over the potential energies of all the finite elements. You should note that each term in the sum is getting scaled by a factor of \(E_e(x_e)\). This is happening because the stiffness matrix varies with Young’s modulus, and we have made Young’s modulus dependent on the local material density.
Material constants. You’ll notice that two material constants appear in the element stiffness matrix. The first is Young’s modulus which measures the stiffness of a material. Intuitively, it is the distortion per unit of force (“How hard do you need to pull a rubber band to stretch it one inch?”). A more technical definition is the ratio of tensile stress to tensile strain. The Poisson coefficient, meanwhile, measures the amount of contraction in the direction perpendicular to a region of stretching, due to that stretching (“How much thinner does the rubber band get when you stretch it one inch?”). A technical definition is the ratio between the lateral contraction per unit length and the longitudinal extension also per unit length. Both of these coefficients come into play when we construct the element stiffness matrix.
defcompliance(x_phys,u,ke,*,penal=3,e_min=1e-9,e_0=1):nely,nelx=x_phys.shapeely,elx=anp.meshgrid(range(nely),range(nelx))# x, y coords for the index map
n1=(nely+1)*(elx+0)+(ely+0)# nodes
n2=(nely+1)*(elx+1)+(ely+0)n3=(nely+1)*(elx+1)+(ely+1)n4=(nely+1)*(elx+0)+(ely+1)all_ixs=anp.array([2*n1,2*n1+1,2*n2,2*n2+1,2*n3,2*n3+1,2*n4,2*n4+1])u_selected=u[all_ixs]# select from u matrix
ke_u=anp.einsum('ij,jkl->ikl',ke,u_selected)# compute x^penal * U.T @ ke @ U
ce=anp.einsum('ijk,ijk->jk',u_selected,ke_u)C=young_modulus(x_phys,e_0,e_min,p=penal)*ce.Treturnanp.sum(C)defget_stiffness_matrix(e,nu):# e=young's modulus, nu=poisson coefficient
k=anp.array([1/2-nu/6,1/8+nu/8,-1/4-nu/12,-1/8+3*nu/8,-1/4+nu/12,-1/8-nu/8,nu/6,1/8-3*nu/8])returne/(1-nu**2)*anp.array([[k[0],k[1],k[2],k[3],k[4],k[5],k[6],k[7]],[k[1],k[0],k[7],k[6],k[5],k[4],k[3],k[2]],[k[2],k[7],k[0],k[5],k[6],k[3],k[4],k[1]],[k[3],k[6],k[5],k[0],k[7],k[2],k[1],k[4]],[k[4],k[5],k[6],k[7],k[0],k[1],k[2],k[3]],[k[5],k[4],k[3],k[2],k[1],k[0],k[7],k[6]],[k[6],k[3],k[4],k[1],k[2],k[7],k[0],k[5]],[k[7],k[2],k[1],k[4],k[3],k[6],k[5],k[0]]])
Calculating displacements. Now we need to tackle one of the most important physics problems: calculating the displacements of the nodes. The way to do this with a 1D spring would be to solve the equation \(F=kx\) for \(x\). Here we can do the same thing, except by solving the matrix equation \(\mathbf{F=KU}\). For a system with \(N\) nodes with 2 degrees of freedom each, the matrix \(\mathbf{K}\) will have dimensions \(2N\) x \(2N\). This gives us a system of \(2N\) simultaneous linear equations for \(2N\) unknown node displacements.
A global stiffness matrix with \(N\) nodes. The number of nodes \(N\) grows as the product of the width and height of our design space. Thus it is not unusual to have over \(10^4\) nodes in a design space. Since the size of \(\mathbf{K}\) grows as \(N^2\), it quickly becomes too large to fit in memory. For example, using \(10^4\) nodes and the np.float32 data format, we get a \(\mathbf{K}\) matrix that consumes 1.6 GB of RAM. Increasing its width and height by 50% increases that number to 8 GB. This is not a sustainable rate of growth!
Luckily, since our nodes are locally-connected, most of the entries in \(\mathbf{K}\) are zero. We can save a vast amount of memory by representing it with a sparse “coordinate list” or COO format. The purpose of the get_k function below is to assemble just such a matrix. If you want to see all the details for how this matrix is constructed, read the “global stiffness matrices with \(N\) nodes” section of this textbook chapter.
The sparse matrix solve. Having constructed \(\mathbf{K}\), all we have left to do is solve the system of equations. This is the most important part of the displace function. It uses Scipy’s SuperLU function (which supports COO) to solve for nodal displacements without ever instantiating a \(2N\) x \(2N\) matrix.
defget_k(stiffness,ke):# Constructs sparse stiffness matrix k (used in the displace fn)
# First, get position of the nodes of each element in the stiffness matrix
nely,nelx=stiffness.shapeely,elx=anp.meshgrid(range(nely),range(nelx))# x, y coords
ely,elx=ely.reshape(-1,1),elx.reshape(-1,1)n1=(nely+1)*(elx+0)+(ely+0)n2=(nely+1)*(elx+1)+(ely+0)n3=(nely+1)*(elx+1)+(ely+1)n4=(nely+1)*(elx+0)+(ely+1)edof=anp.array([2*n1,2*n1+1,2*n2,2*n2+1,2*n3,2*n3+1,2*n4,2*n4+1])edof=edof.T[0]x_list=anp.repeat(edof,8)# flat list pointer of each node in an element
y_list=anp.tile(edof,8).flatten()# flat list pointer of each node in elem
# make the global stiffness matrix K
kd=stiffness.T.reshape(nelx*nely,1,1)value_list=(kd*anp.tile(ke,kd.shape)).flatten()returnvalue_list,y_list,x_listdefdisplace(x_phys,ke,forces,freedofs,fixdofs,*,penal=3,e_min=1e-9,e_0=1):# Displaces the load x using finite element techniques (solve_coo=most of runtime)
stiffness=young_modulus(x_phys,e_0,e_min,p=penal)k_entries,k_ylist,k_xlist=get_k(stiffness,ke)index_map,keep,indices=_get_dof_indices(freedofs,fixdofs,k_ylist,k_xlist)u_nonzero=solve_coo(k_entries[keep],indices,forces[freedofs],sym_pos=True)u_values=anp.concatenate([u_nonzero,anp.zeros(len(fixdofs))])returnu_values[index_map]
Sparse matrix helper functions
You may notice that the displace function uses a helper function, _get_dof_indices, to update \(\mathbf{K}\)’s indices. The point here is to keep only the degrees of freedom that were actually free in the problem setup (the freedofs). To do this, we need to remove the degrees of freedom where normal forces were introduced (the fixdofs).
The second function is the inverse_permutation function. It is a mathematical operation that gives us the indices needed to undo a permutation. For example, if ixs is a list of indices that permutes the list A, then this function gives us a second list of indices inv_ixs such that A[ixs][inv_ixs] = A.
def_get_dof_indices(freedofs,fixdofs,k_xlist,k_ylist):index_map=inverse_permutation(anp.concatenate([freedofs,fixdofs]))keep=anp.isin(k_xlist,freedofs)&anp.isin(k_ylist,freedofs)# Now we index an indexing array that is being indexed by the indices of k
i=index_map[k_ylist][keep]j=index_map[k_xlist][keep]returnindex_map,keep,anp.stack([i,j])definverse_permutation(indices):# reverses an index operation
inverse_perm=np.zeros(len(indices),dtype=anp.int64)inverse_perm[indices]=np.arange(len(indices),dtype=anp.int64)returninverse_perm
Custom gradients for a sparse matrix solve. Our sparse solve, like our 2D Gaussian filter, comes from the Scipy library and is not supported by Autograd. So we need to tell Autograd how to differentiate through it. To do this, we’ll copy a few lines of code from this Google Research repo.
def_get_solver(a_entries,a_indices,size,sym_pos):# a is (usu.) symmetric positive; could solve 2x faster w/sksparse.cholmod.cholesky(a).solve_A
a=scipy.sparse.coo_matrix((a_entries,a_indices),shape=(size,)*2).tocsc()returnscipy.sparse.linalg.splu(a).solve@autograd.primitivedefsolve_coo(a_entries,a_indices,b,sym_pos=False):solver=_get_solver(a_entries,a_indices,b.size,sym_pos)returnsolver(b)defgrad_solve_coo_entries(ans,a_entries,a_indices,b,sym_pos=False):defjvp(grad_ans):lambda_=solve_coo(a_entries,a_indicesifsym_poselsea_indices[::-1],grad_ans,sym_pos)i,j=a_indicesreturn-lambda_[i]*ans[j]returnjvpautograd.extend.defvjp(solve_coo,grad_solve_coo_entries,lambda:print('err: gradient undefined'),lambda:print('err: gradient not implemented'))
And with that, we are done with the physics! Now we are ready to set up the optimization itself.
Optimization
To do this, we’ll use the Method of Moving Asymptotes (MMA). Originally described by Svanberg (1987) and refined in Svanberg (2002), MMA is a good fit for structural optimization problems because it accepts nonlinear inequality constraints and scales to large parameter spaces. In the code below, we rewrite the mass conservation constraint as a mass threshold constraint so that it looks like an inequality. Then we set the density constraint by giving upper and lower bounds on the parameter space. Finally, we use Autograd to obtain gradients with respect to the objective and pass them to the solver. The NLopt package makes this process pretty straightforward. Also, its documentation gives some good practical advice on how to think about MMA.
Other optimization approaches we tried included the optimality criteria (by Andreasson et al. 2010), plain gradient descent, L-BFGS, and the Adam optimizer. Consistent with the findings of this paper, MMA outperformed all these approaches.
deffast_stopt(args,x=None,verbose=True):ifxisNone:x=anp.ones((args.nely,args.nelx))*args.density# init mass
reshape=lambdax:x.reshape(args.nely,args.nelx)objective_fn=lambdax:objective(reshape(x),args)# don't enforce mass constraint here
constraint=lambdaparams:mean_density(reshape(params),args)-args.densitydefwrap_autograd_func(func,losses=None,frames=None):defwrapper(x,grad):ifgrad.size>0:value,grad[:]=autograd.value_and_grad(func)(x)else:value=func(x)iflossesisnotNone:losses.append(value)ifframesisnotNone:frames.append(reshape(x).copy())ifverboseandlen(frames)%args.print_every==0:print('step {}, loss {:.2e}, t={:.2f}s'.format(len(frames),value,time.time()-dt))returnvaluereturnwrapperlosses,frames=[],[];dt=time.time()print('Optimizing a problem with {} nodes'.format(len(args.forces)))opt=nlopt.opt(nlopt.LD_MMA,x.size)opt.set_lower_bounds(0.0);opt.set_upper_bounds(1.0)opt.set_min_objective(wrap_autograd_func(objective_fn,losses,frames))opt.add_inequality_constraint(wrap_autograd_func(constraint),1e-8)opt.set_maxeval(args.opt_steps+1)opt.optimize(x.flatten())returnnp.array(losses),reshape(frames[-1]),np.array(frames)
We are finally ready to optimize our MBB beam
# run the simulation and visualize the result
args=get_args(*mbb_beam())losses,x,frames=fast_stopt(args=args,verbose=True)plt.figure(dpi=50);print('\nFinal design space:')plt.imshow(x);plt.show()plt.figure(dpi=100);print('\nFinal MBB beam design:')plt.imshow(np.concatenate([x[:,::-1],x],axis=1));plt.show()
Optimizing a problem with 4212 nodes
step 10, loss 1.28e+03, t=1.31s
step 20, loss 5.38e+02, t=2.51s
step 30, loss 4.17e+02, t=3.92s
step 40, loss 3.67e+02, t=5.36s
step 50, loss 3.61e+02, t=6.84s
step 60, loss 3.58e+02, t=8.30s
step 70, loss 3.55e+02, t=9.67s
step 80, loss 3.44e+02, t=10.79s
Final design space:
Final MBB beam design:
Optimizing the eves of a gazebo roof
Let’s turn to a slightly more challenging and interesting task. This is a design problem that came up recently at the engineering firm where I work. It consists of a gazebo roof that is 16’ wide and 4’ high (with a 2:1 pitch). The fixed points include the bottom region, where a large beam runs as well as a vertical center beam.
The dead load for the structure is 12-17 pounds per square foot (psf), the live load is 25 psf, snow load is 10 psf, wind load ranges from 10 psf downward to 4 psf upwards. Combining the vertical and horizontal forces with one another and estimating the worst-case net force on the roof, we obtain a vector with a magnitude that is 20 degrees (0.349 radians) off of the vertical. Putting all this together, we have a structural optimization problem which can be solved to obtain a support strucure for the roof.
defeves(width=200,height=100,density=0.15,theta=-0.349):# theta is the angle (rad) between vertical and the net force on the roof
x_ix,y_ix=0,1normals=np.zeros((width+1,height+1,2))normals[:,-1,:]=1forces=np.zeros((width+1,height+1,2))start_coords,stop_coords=(0,0),(width,height)importskimage.drawi,j,value=skimage.draw.line_aa(*start_coords,*stop_coords)forces[i,j,x_ix]=np.sin(theta)*np.minimum(forces[i,j,y_ix],-value/width)forces[i,j,y_ix]=np.cos(theta)*np.minimum(forces[i,j,y_ix],-value/width)returnnormals,forces,density# run the simulation and visualize the result
args=get_args(*eves())losses,x,frames=fast_stopt(args=args,verbose=True)
Optimizing a problem with 66306 nodes
step 10, loss 1.01e+02, t=34.68s
step 20, loss 7.87e+00, t=69.54s
step 30, loss 3.05e+00, t=104.69s
step 40, loss 2.68e+00, t=138.80s
step 50, loss 2.53e+00, t=173.08s
step 60, loss 2.48e+00, t=206.53s
step 70, loss 2.47e+00, t=240.59s
step 80, loss 2.47e+00, t=278.73s
step 90, loss 2.46e+00, t=312.37s
step 100, loss 2.46e+00, t=347.35s
A few other designs
defcauseway_bridge(width=128,height=128,density=0.08,deck_level=0.2):"""A bridge supported by columns at a regular interval."""x_ix,y_ix=0,1normals=np.zeros((width+1,height+1,2))normals[-1,-1,y_ix]=1normals[-1,:,x_ix]=1normals[0,:,x_ix]=1forces=np.zeros((width+1,height+1,2))forces[:,round(height*(1-deck_level)),y_ix]=-1/widthreturnnormals,forces,density# run the simulation and visualize the result
args=get_args(*causeway_bridge())args.opt_steps=160;args.print_every=20losses,x,frames=fast_stopt(args=args,verbose=True)
Optimizing a problem with 33282 nodes
step 20, loss 6.45e+02, t=32.45s
step 40, loss 6.99e+01, t=66.31s
step 60, loss 6.22e+01, t=96.67s
step 80, loss 6.08e+01, t=127.47s
step 100, loss 6.01e+01, t=158.28s
step 120, loss 5.97e+01, t=188.59s
step 140, loss 5.90e+01, t=222.50s
step 160, loss 5.84e+01, t=253.61s
defstaggered_points(width=64,height=256,density=0.3,interval=16,break_symmetry=False):"""A staggered grid of points with downward forces, supported from below."""x_ix,y_ix=0,1normals=np.zeros((width+1,height+1,2))normals[:,-1,y_ix]=1normals[0,:,x_ix]=1normals[-1,:,x_ix]=1forces=np.zeros((width+1,height+1,2))f=interval**2/(width*height)# intentionally break horizontal symmetry?
forces[interval//2+int(break_symmetry)::interval,::interval,y_ix]=-fforces[int(break_symmetry)::interval,interval//2::interval,y_ix]=-freturnnormals,forces,density# run the simulation and visualize the result
args=get_args(*staggered_points())losses,x,frames=fast_stopt(args=args,verbose=True)
Optimizing a problem with 33410 nodes
step 10, loss 1.91e+02, t=13.35s
step 20, loss 1.43e+02, t=26.34s
step 30, loss 6.96e+01, t=39.41s
step 40, loss 6.46e+01, t=52.50s
step 50, loss 4.44e+01, t=65.47s
step 60, loss 3.97e+01, t=78.36s
step 70, loss 3.76e+01, t=91.24s
step 80, loss 3.58e+01, t=104.05s
defstaircase(width=256,height=256,density=0.15,num_stories=3):"""A ramp that zig-zags upward, supported from the ground."""x_ix,y_ix=0,1normals=np.zeros((width+1,height+1,2))normals[:,-1,:]=1importskimage.drawforces=np.zeros((width+1,height+1,2))forstoryinrange(num_stories):parity=story%2start_coordinates=(0,(story+parity)*height//num_stories)stop_coordiates=(width,(story+1-parity)*height//num_stories)i,j,value=skimage.draw.line_aa(*start_coordinates,*stop_coordiates)forces[i,j,y_ix]=np.minimum(forces[i,j,y_ix],-value/(width*num_stories))returnnormals,forces,density# run the simulation and visualize the result
args=get_args(*staircase())args.opt_steps=100losses,x,frames=fast_stopt(args=args,verbose=True)
Optimizing a problem with 132098 nodes
step 10, loss 9.65e+01, t=98.39s
step 20, loss 3.04e+01, t=197.26s
step 30, loss 7.37e+00, t=294.96s
step 40, loss 4.38e+00, t=390.48s
step 50, loss 3.98e+00, t=483.45s
step 60, loss 3.88e+00, t=575.68s
step 70, loss 3.86e+00, t=668.17s
step 80, loss 3.83e+00, t=758.19s
step 90, loss 3.82e+00, t=847.92s
step 100, loss 3.81e+00, t=939.67s
defmultistory_building(width=128,height=512,density=0.2,interval=64):x_ix,y_ix=0,1normals=np.zeros((width+1,height+1,2))normals[:,-1,y_ix]=1normals[-1,:,x_ix]=1forces=np.zeros((width+1,height+1,2))forces[:,::interval,y_ix]=-1/widthreturnnormals,forces,density# run the simulation and visualize the result
args=get_args(*multistory_building())args.opt_steps=160;args.print_every=10losses,x,frames=fast_stopt(args=args,verbose=True)
Optimizing a problem with 132354 nodes
step 10, loss 1.28e+04, t=72.03s
step 20, loss 8.77e+03, t=144.31s
step 30, loss 7.23e+03, t=215.94s
step 40, loss 1.74e+03, t=289.13s
step 50, loss 9.65e+02, t=362.98s
step 60, loss 8.40e+02, t=434.95s
step 70, loss 8.06e+02, t=506.56s
step 80, loss 7.97e+02, t=577.98s
step 90, loss 7.89e+02, t=648.11s
step 100, loss 7.87e+02, t=718.23s
step 110, loss 7.85e+02, t=787.93s
step 120, loss 7.83e+02, t=857.21s
step 130, loss 7.82e+02, t=927.52s
step 140, loss 7.81e+02, t=996.80s
step 150, loss 7.79e+02, t=1066.46s
step 160, loss 7.77e+02, t=1135.57s
In sci-fi representations of the healthy cities of the future, we often find manmade structures that are well integrated with their natural surroundings. Sometimes we even see a convergence where nature has adapted to the city and the city has adapted to nature. The more decadent cities, on the other hand, tend to define themselves in opposition to the patterns of nature. Their architecture is more blocky and inorganic. Perhaps tools like structural optimization can help us build the healthy cities of the future – and steer clear of the decadent ones.
The city of Asgard from Thor
Footnotes
Andreassen et al (2010) use a cone filter; we found that a Gaussian filter gave similar results and was easier to implement. ↩
Deriving the specific entries of the element stiffness matrix takes quite a few steps. We won’t go through all of them here, but you can walk yourself through them using this textbook chapter. ↩
]]>Sam GreydanusHow Simulating the Universe Could Yield Quantum Mechanics2022-03-27T11:00:00+00:002022-03-27T11:00:00+00:00http://greydanus.github.io/2022/03/27/how-simulating
Let’s imagine the universe is being simulated. Based on what we know about physics, what can we say about how the simulation would be implemented? Well, it would probably have:
Massive parallelism. Taking advantage of the fact that, in physics, all interactions are local and limited by the speed of light, one could parallelize the simulation. Spatially adjacent regions would run on the same CPUs whereas spatially distant regions would run on separate CPUs.1
Conservation laws enforced. Physics is built on the idea that certain quantities are strictly conserved. Scalar quantities like mass-energy are conserved, as are vector quantities like angular momentum.2
Binary logic. Our computers use discrete, binary logic to represent and manipulate information. Non-discrete numbers are represented with sequences of discrete symbols (see float32). Let’s assume our simulation does the same thing.
Adaptive computation. To simulate the universe efficiently, we would want to spend most of our compute time on regions where a lot of matter and energy are concentrated: that’s where the dynamics would be most complex. So we’d probably want to use a particle-based (Lagrangian) simulation of some sort.
We can determine whether these are reasonable assumptions by checking that they hold true for existing state-of-the-art physics simulations. It turns out that they hold true for the best oceanography, meteorology, plasma, cosmology, and computational fluid dynamics models. So, having laid out some basic assumptions about how our simulation would be implemented, let’s look at their implications.
Enforcing conservation laws in parallel
The first thing to see is that assumptions 1 and 2 are in tension with one another. In order to ensure that a quantity (eg mass-energy) is conserved, you need to sum that quantity across the entire simulation, determine whether a correction is needed, and then apply that correction to the system as a whole. Computationally, this requires a synchronous reduction operation and an element-wise divide at virtually every timestep.
A conceptual outline of a large-scale physics simulation where different regions of space are being simulated in parallel. This parallelization is possible because nothing can travel faster than the speed of light; thus the separate regions can be simulated independently over short timescales.
When you write a single-threaded physics simulation, this can account for about half of the computational cost (these fluid and topology simulations are good examples). As you parallelize your simulation more and more, you can expect the cost of enforcing conservation laws to grow higher in proportion. This is because simulating dynamics is pretty easy to do in parallel. But enforcing system-wide conservation laws requires transferring data between distant CPU cores and keeping them more or less in sync. As a result, enforcing conservation laws in this manner quickly grows to be a limiting factor on runtime. We find ourselves asking: is there a more parallelizable approach to enforcing global conservation laws?
One option is to use a finite volume method to keep track of quantities moving between grid cells rather than absolute values. If we don’t care about exactly enforcing a conservation law, then this may be sufficient. We should note, though, that under a finite volume scheme small rounding and integration errors will occur and over time they will cause the globally-conserved quantity to change slightly. (More speculatively, this may be a particularly serious problem if people in the simulation are liable to stumble upon this phenomenon and exploit it adversarially to create or destroy energy.)
If we want to strictly enforce a globally-conserved quantity in a fully parallel manner, there is a third option that we could try: we could quantize it. We could quantize energy, for example, and then only transfer it in the form of discrete packets.
To see why this would be a good idea, let’s use financial markets as an analogy. Financial markets are massively parallel and keeping a proper accounting of the total amount of currency in circulation is very important. So they allow currency to function as a continuous quantity on a practical level, but they quantize it at a certain scale by making small measures of value (pennies) indivisible. We could enforce conservation of energy in the same way, for the same reasons.
Conserving vector quantities
Quantization may work well for conserving scalar values like energy. But what about conserving vector quantities like angular momentum? In these cases, isotropy/rotational symmetry (assumption 5) makes things difficult. Isotropy says that our simulation will be invariant under rotation, but if we quantized the directions of our angular momentum vectors, we would be unable to represent all spatial directions equally. We’d get rounding errors which would compound over time.
So how are we to implement exact conservation of vector quantities? One option is to require that one particle’s vector quantities always be defined in reference to some other particle’s vector quantities. This could be implemented by creating multiple pointer references to a single variable and then giving each of those pointers to a different particle. As a concrete example, we might imagine an atom releasing energy in the form of two photons. The polarization angle of the first photon could be expressed as a 90\(^\circ\) clockwise rotation of a pointer to variable x. Meanwhile, the polarization angle of the second photon could be expressed as a 90\(^\circ\) counterclockwise rotation of a pointer to the same variable x. As we advance our simulation through time, the polarization angles of the two photons would change. Perhaps some small integration and rounding errors would accumulate. But even if that happens, we can say with confidence that the relative difference in polarization angle will be a constant 180\(^\circ\). In this way, we could enforce conservation of angular momentum in parallel across the entire simulation.
We should recognize that this approach comes at a price. It demands that we sacrifice locality, the principle that an object is influenced directly only by its immediate surroundings. It’s one of the most sacred principles in physics. This gets violated in the example of the two photons because a change in the polarization of the first photon will update the value of x, implicitly changing the polarization of the second photon.
This figure is inspired by the experimental setup of Clauser and Horne (1974) used to test the Bell inequality. Here we are hypothesizing the existence of a shared hidden variable x which, when updated due to the left photon's interaction with a polarizer, also affects the right photon's polarization.
Interestingly, the mechanics of this nonlocal relationship would predict a violation of Bell’s inequality which would match experimental results. Physicists agree that violation of Bell’s inequality implies that nature violates either realism, the principle that reality exists with definite properties even when not being observed, or locality. Since locality is seen as a more fundamental principle than realism, the modern consensus is that quantum mechanics violates realism. In this line of thinking, entangled particles cannot be said to have deterministic states and instead exist in a state of superposition until they are measured. But in our simulated universe, realism would be preserved and locality would be sacrificed. Entangled particles would have definite states but sometimes those states would change due to shared references to spatially distant “twins.”3 To see how this would work in practice, try simulating it yourself at the link below.
Our findings thusfar may lead us to ask whether other quantum mechanical phenomena can be derived from the simulation ansatz. For example, what could be causing the wave-particle duality of light as seen in the double slit experiment?
The important idea here is filtering. Filtering is a common technique where a Gaussian or cone filter is convolved with a grid in order to smooth out the physics and eliminate grid-level pathologies. This step is essential – for example, these fluid and topology simulations would not work without it.
How would one implement filtering in a large-scale, particle-based simulation of the universe? Well, if the simulation were particle-based instead of grid-based, we couldn’t apply a Gaussian or cone filter. An alternative would be to simulate the dynamics of each particle using ensembles of virtual particles. One could initialize a group of these virtual particles with slightly different initial conditions and then simulate all of them through time. If you allowed these virtual particles to interact with other virtual particles in the ensemble, the entire ensemble would collectively behave as though it were a wave.
Wave-particle behavior of a photon as a consequence of using an ensemble of virtual particles and selecting just one to transfer a quanta of energy to the photoreceptor.
You might notice that there is a tension between this spatially delocalized, wave-like behavior (a consequence of filtering, which is related to assumption 3) and the conservation/quantization of quantities like energy (assumption 2). The tension is this: when a wave interacts with an object, it transfers energy in a manner that is delocalized and proportionate to its amplitude at a given location. But we have decided to quantize energy in order to keep an exact accounting of it across our simulation. So when our ensemble of particles interacts with some matter, it must transfer exactly one quanta of energy and it must do so at one particular location.
The simplest way to implement this would be to choose one particle out of the ensemble and allow it to interact with other matter and transfer energy. The rest of the particles in the ensemble would be removed from the simulation upon coming into contact with other matter. The interesting thing about this approach is that it could help explain the wave-particle duality of subatomic particles such as photons. For example, it could be used to reproduce the empirical results of the double slit experiment in a fully deterministic manner.4
It is generally accepted that the cost of simulating \(N\) entangled particles, each with \(d\) degrees of freedom, grows as \(d^{N}\). This means that simulating a quantum system with a classical computer becomes prohibitively expensive for even small groups of particles. And if you simulate such systems probabilistically, you will inevitably encounter cases where the simulated physics doesn’t match reality.5 If it’s that difficult for classical computers to simulate quantum effects – and the universe is quantum mechanical – then isn’t this entire thought experiment destined to fail?
Perhaps not. Claims about the difficulty of simulating quantum effects are based on quantum indeterminacy, the idea that entangled particles do not have definite states prior to measurement. This interpretation of quantum effects comes about when we sacrifice the assumption of realism. But if we sacrifice locality (as we have done in this article), then we need not sacrifice realism. In a world where entangled particles can affect each other’s states instantaneously at a distance (nonlocality), they can always have specific states (realism) and still produce the empirical behaviors (violation of Bell’s theorem) that consitute the basis of the theory of quantum mechanics. This sort of world could be simulated on a classical computer.
Testing our hypothesis
Suppose the ideas we have discussed are an accurate model of reality. How would we test them? We could start by showing that in quantum mechanics, realism is actually preserved whereas locality is not. To that end, here’s one potential experiment:
We set up the apparatus used to test Bell’s inequality. Entangled photons emerge from a source and head in opposite directions. Eventually they get their polarizations measured. We allow the first photon in the pair to enter a double slit experiment. As it passes through the double slit, it interferes with itself, producing a wavelike diffraction pattern on the detector.
One possible means of testing the hypothesis we have outlined. If photons used to test the Bell inequality behave in this manner when they encounter a double slit setup, one could use them to transmit information faster than the speed of light, violating the locality assumption.
Then we change the experiment by measuring the second photon in the pair before the first photon reaches the double slit. This will break the entanglement, causing both photons to enter well-defined polarization states. When this happens, the first photon will behave like a particle as it passes through the double slit experiment. This would be a surprising result because such a setup would violate the locality assumption6 and could be used to transmit information faster than light.
Closing thoughts
To the followers of Plato, the world of the senses was akin to shadows dancing on the wall of a cave. The essential truths and realities of life were not to be found on the wall at all, but rather somewhere else in the cave in the form of real dancers and real flames. A meaningful life was to be spent seeking to understand those forms, elusive though they might be.
In this post, we took part in that tradition by using our knowledge of physics simulations to propose a new interpretation of quantum mechanics. It’s hard to know whether we do indeed live in a simulation. Perhaps we will never know. But at the very least, the idea serves as a good basis for a thought-provoking discussion.
As a subset of conservation of angular momentum, polarization is also conserved. This is relevant to later examples which assume conservation of polarization. ↩
Physicists have certainly entertained the idea of using non-local theories to explain Bell’s inequality. One of the reasons these theories are not more popular is that Groblacher et al, 2007 and others have reported experimental results that rule out some of the more reasonable options (eg Leggett-style non-local theories). But the idea we are proposing here is somewhat more radical; it would permit information to travel faster than the speed of light, violating the No-communication theorem. Of course, the only information that could be communicated faster than the speed of light would be whether a given pair of particles is in a superposition of states or not. Look at the “Testing our hypothesis” section for more discussion on this topic. ↩
Update (May 16, 2022): I tried to code this up and encountered some problems. First of all, it’s a nontrivial simulation problem. But apart from that, it’s difficult to achieve wavelike behaviors across the group without faster-than-light propagation of electric fields (which I suspect is nonphysical). I suspect that this filtering path is still a viable route to explaining the double slit experiment, but I now believe that the implementation details may look a bit different. One idea Jason Yosinski suggested was: what if our simulator was solving a PDE in both the spatial domain and the frequency domain and occasionally, whenever a spatial pattern got too diffuse, it would be transferred over to the frequency domain. Conversely, whenever a frequency pattern got too localized, it would be transferred over to the spatial domain. This could help to explain, for example particle generation in a vacuum. More on this in the future. ↩
Dissipative HNNs (D-HNNs) improve upon Hamiltonian Neural Networks. They output two scalar functions, denoted here by H and D. The first of these two, H, is the Hamiltonian. We use its symplectic gradient to model energy-conserving dynamics. The second, D, is the Rayleigh dissipation function. We use it to model the dissipative component of the system. The addition of this dissipation function allows D-HNNs to model systems where energy is not quite conserved, as, for example, in the case of the damped mass-spring system shown here.
We are immersed in a complex, dynamic world where change is the only constant. And yet there are certain patterns to this change that suggest natural laws. These laws include conservation of mass, energy, and momentum. Taken together, they constitute a powerful simplifying constraint on reality. Indeed, physics tells us that a small set of laws and their associated invariances are at the heart of all natural phenomena. Whether we are studying weather, ocean currents, earthquakes, or molecular interactions, we should take care to respect these laws. And when we apply learning algorithms to these domains, we should ensure that they, too, respect these laws.
We can do this by building models that are primed to learn invariant quantities from data: these models include HNNs, LNNs, and a growing class of related models. But one problem with these models is that, for the most part, they can only handle data where some quantity (such as energy) is exactly conserved. If the data is collected in the real world and there is even a small amount of friction, then these models struggle. In this post, we introduce Dissipative HNNs, a class of models which can learn conservation laws from data even when energy isn’t perfectly conserved.
We live in a sea of change. But no matter how complex a system's dynamics are, they can always be decomposed into the sum of dissipative dynamics and conservative dynamics.
The core idea is to use a neural network to parameterize both a Hamiltonian and a Rayleigh dissipation function. During training, the Hamiltonian function fits the conservative (rotational) component of the dynamics whereas the Rayleigh function fits the dissipative (irrotational) component. Let’s dive in to how this works.
A quick theory section
The Hamiltonian function. The Hamiltonian \(\mathcal{H}(\textbf{q},\textbf{p})\) is scalar function where by definition \( \frac{\partial \mathcal{H}}{\partial \textbf{p}} = \frac{\partial \textbf{q}}{dt}, -\frac{\partial \mathcal{H}}{\partial \textbf{q}} = \frac{\partial \textbf{p}}{dt} \). This constraint tells us that, even as the position and momentum coordinates of the system \(\textbf{(q, p)}\) change, the scalar output \(\mathcal{H}\) remains fixed. In other words, \(\mathcal{H}\) is invariant with respect to \(\textbf{q}\) and \(\textbf{p}\) as they change over time; it is a conserved quantity. Hamiltonians often appear in physics because for every natural symmetry/law in the universe, there is a corresponding conserved quantity (see Noether’s theorem).
The Rayleigh function. The Rayleigh dissipation function \(\mathcal{D}(\textbf{q},\textbf{p})\) is a scalar function that provides a way to account for dissipative forces such as friction in the context of Hamiltonian mechanics. As an example, the Rayleigh function for linear, velocity-dependent dissipation would be \(\mathcal{D} = \frac{1}{2}\rho\dot{q}^2\) where \(\rho\) is a constant and \(\dot q\) is the velocity coordinate. We add this function to a Hamiltonian whenever the conserved quantity we are trying to model is changing due to sources and sinks. For example, if \(\mathcal{H}\) measures the total energy of a damped mass-spring system, then we could add the \(\mathcal{D}\) we wrote down above to account for the change in total energy due to friction.
Helmholtz decompositions. Like many students today, Hermann von Helmholtz realized that medicine was not his true calling. Luckily for us, he switched to physics and discovered one of the most useful tools in vector analysis: the Helmholtz decomposition. The Helmholtz decomposition says that any vector field \(V\) can be written as the gradient of a scalar potential \(\phi\) plus the curl of a vector potential \(\mathcal{\textbf{A}}\). In other words, \( V = \nabla\phi + \nabla\times \mathcal{\textbf{A}}\). Note that the first term is irrotational and the second term is rotational. This tells us that any vector field can be decomposed into the sum of an irrotational (dissipative) vector field and a rotational (conservative) vector field. Here’s a visual example:
Putting it together. In Hamiltonian Neural Networks, we showed how to parameterize the Hamiltonian function and then learn it directly from data. Here, we parameterize a Rayleigh function as well. Our model looks the same as an HNN except now it has a second scalar output which we use for the Rayleigh function (see the first image in this post). During the forward pass, we take the symplectic gradient of the Hamiltonian to obtain conservative forces. Note that as we do this, the symplectic gradient constitutes a rotational vector field over the model’s inputs. During the forward pass we also take the gradient of the Rayleigh function to obtain dissipative forces. This gradient gives us an irrotational vector field over the same domain.
All of this means that, by construction, our model will learn an implicit Helmholtz decomposition of the forces acting on the system.
An introductory model
We coded up a D-HNN model and used it to fit three physical systems: a synthetic damped mass-spring, a real-world pendulum, and an ocean current timeseries sampled from the OSCAR dataset. In this post, we’ll focus on the damped mass-spring example in order to build intuition for how D-HNNs work.
We can describe the state of a damped (one dimensional) mass-spring system with just two coordinates, \(q\) and \(p\). Also, we can plot these coordinates on Cartesian \(x\) and \(y\) axes to obtain phase-space diagrams. These diagrams are useful because they allow us to visualize and compare our model to other baseline models.
In the image above, the damped mass-spring dataset is plotted in the upper left square. Each arrow represents the time derivative of the system with respect to that \((p,q)\) coordinate. The Helmholtz decomposition tells us that this vector field can be decomposed into conservative and dissipative components, and indeed that is what we have done in the second and third columns.1 You may notice that the dissipative field in the third column isolates the force due to friction.
In the second row, we evaluate a D-HNN trained on the system. The D-HNN produces a trajectory that closely matches ground truth. By plotting the symplectic gradient of \(\mathcal{H}\) and the gradient of \(\mathcal{D}\), we can see that it has properly decoupled the conservative and dissipative dynamics respectively. By contrast, in the third row, we train a baseline model (an MLP) on the same data; this model produces a good trajectory but is unable to learn conservative and dissipative dynamics separately. Finally, in the fourth row, we train an HNN on the same dataset and find that it is only able to model the conservative component of the system’s dynamics. It strictly enforces conservation of energy in a scenario where energy is not actually conserved, leading to a poor prediction.
Why decouple conservative and dissipative dynamics?
We’ve described a model that can learn conservative and dissipative dynamics separately and shown that it works on a toy problem. Why is this a good idea? One answer is that it lets our model fit data in a more physically-realistic manner, leading to better generalization.
If we were to suddenly double the coefficient of friction \(\rho\), our MLP model would not be able to predict a viable trajectory. This is because it models the dissipative and conservative dynamics of the system together. However, since our D-HNN learned these dynamics separately, it can generalize to new friction coefficients without additional training. In order to double the scale of dissipative forces, we can simply multiply the gradient of the Rayleigh function by two. The image below shows how this produces viable trajectories under unseen friction coefficients (orange highlights).
Additional experiments
We also trained our model on data from a real pendulum and ocean current data from the OSCAR dataset (shown below). On these larger and more more difficult tasks, our model continued to decouple conservative and dissipative dynamics. The details and results are outside the scope of this post, but you can find them in our paper.
Closing thoughts
This work is a small, practical contribution to science in that it proposes a new physics prior for machine learning models. But it is also a step towards a larger and more ambitious goal: that of building models which can extract conservation laws directly from noisy real-world data. We hope that future work in this direction will benefit from our findings.
Footnotes
In practice, we performed this decomposition using a few hundred iterations of the Gauss-Seidel method to solve Poisson’s equation. Again, see this paper for details. ↩
]]>Andrew Sosanya and Sam GreydanusPiecewise-constant Neural ODEs2021-06-11T11:00:00+00:002021-06-11T11:00:00+00:00http://greydanus.github.io/2021/06/11/piecewise-nodes
Using model-based planning to play billiards. The goal is to impart the tan cue ball with an initial velocity so as to move the blue ball to the black target.
A baseline ODE-RNN trained on billiards dynamics can also be used for model-based planning. It's inefficient because it has to "tick" at a constant rate.
By contrast, our model, trained on the same task, can perform planning in many fewer steps by jumping over spans of time where motion is predictable.
Change, it is said, happens slowly and then all at once…
Billiards balls move across a table before colliding and changing trajectories; water molecules cool slowly and then undergo a rapid phase transition into ice; and economic systems enjoy periods of stability interspersed with abrupt market downturns. That is to say, many time series exhibit periods of relatively homogeneous change divided by important events. Despite this, recurrent neural networks (RNNs), popular for time series modeling, treat time in uniform intervals – potentially wasting prediction resources on long intervals of relatively constant change.
A recent family of models called Neural ODEs has attracted interest as a means of mitigating these problems. They parameterize the time derivative of a hidden state with a neural network and then integrate it over arbitrary amounts of time. This allows them to treat time as a continuous variable. Integration can even be performed using adaptive integrators like Runge-Kutta, thus allocating more compute to difficult state transitions.
Adaptive integration is especially attractive in scenarios where “key events” are separated by variable amounts of time. In the game of billiards, these key events may consist of collisions between balls, walls, and pockets. Between these events, the balls simply undergo linear motion. That motion is not difficult to predict, but it is non-trivial for a model to learn to skip over it so as to focus on the more chaotic dynamics of collisions; this requires a model to employ some notion of temporal abstraction. This problem is not unique to billiards. The same challenge occurs in robotics, where a robot arm occasionally interacts with external objects at varying intervals. It may also occur in financial markets, scientific timeseries, and other environments where change happens at a variable rate.
Towards temporally-abstract hidden state dynamics
In this post, I am going to introduce a special case of Neural ODEs that my research group has been experimenting with recently. The core idea is to restrict the hidden state of a Neural ODE so that it has locally-linear dynamics. The benefit of such a model is that it can be integrated exactly using Euler integration, and it can also be integrated adaptively because we allow these locally-linear dynamics to extend over variable-sized durations of time. Like RNNS and Neural ODEs, our model uses a hidden state \(h\) to summarize knowledge about the world at a given point in time. Also, it performs updates on this hidden state using cell updates (eg. with vanilla, LSTM, or GRU cells). But our model differs from existing models in that the amount of simulation time that occurs between cell updates is not fixed. Rather, it changes according to the variable \(\Delta t\), which is itself predicted.
Our model also predicts a hidden state velocity, \(\dot h\), at each cell update; this enables us to evolve the hidden state dynamics continuously over time according to \(h(t+\Delta t) = h + \dot h \Delta t\). In other words, the hidden state velocity allows us to parameterize the locally-linear dynamics of the hidden state. Thus when our model needs to simulate long spans of homogeneous change (eg, a billiard ball undergoing linear motion), it can do so with a single cell update.
In order to compare our model to existing timeseries models (RNNs and Neural ODEs), we used both of them to model a series of simple physics problems including the collisions of two billiards balls. We found that our jumpy model was able to learn these dynamics at least as well as the baseline while using a fraction of the forward simulation steps. This makes it a great candidate for model-based planning because it can predict the outcome of taking an action much more quickly than a baseline model. And since the hidden-state dynamics are piecewise-linear over time, we can solve for the hidden state at arbitrary points along a trajectory. This allows us to simulate the dynamics at a higher temporal resolution than the original training data:
This video will give you a sense of the underlying temporal resolution of the billiards dataset on which we trained the model.
This video shows how we can use our model to generate simulations at a higher temporal resolution than that of the original simulator.
I am going to give more specific examples of how our model improves over regular timeseries models later. But first we need to talk about what these timeseries models are good at and why they are worth improving in the first place.
The value of timeseries models
Neural network-based timeseries models like RNNs and Neural ODEs are interesting because they can learn complex, long-range structure in time series data simply by predicting one point at a time. For example, if you train them on observations of a robot arm, you can use them to generate realistic paths that the arm might take.
One of the things that makes these models so flexible is that they use a hidden vector \(h\) to store memories of past observations. And they can learn to read, write, and erase information from \(h\) in order to make accurate predictions about the future. RNNs do this in discrete steps whereas Neural ODEs permit hidden state dynamics to be continuous in time. Both models are Turing-complete and, unlike other models that are Turing-complete (eg. HMMs or FSMs), they can learn and operate on noisy, high-dimensional data. Here is an incomplete list of things people have trained these models (mostly RNNs) to do:
Let’s begin with the limitations of RNNs, use them to motivate Neural ODEs, and then discuss the contexts in which even Neural ODEs have shortcomings. The first and most serious limitation of RNNs is that they can only predict the future by way of discrete, uniform “ticks”.
Uniform ticks. At each tick they make one observation of the world, perform one read-erase-write operation on their memory, and output one state vector. This seems too rigid. We wouldn’t divide our perception of the world into uniform segments of, say, ten minutes. This would be silly because the important events of our daily routines are not spaced equally apart.
Consider the game of billiards. When you prepare to strike the cue ball, you imagine how it will collide with other balls and eventually send one of them into a pocket. And when you do this, you do not think about the constant motion of the cue ball as it rolls across the table. Instead, you think about the near-instantaneous collisions between the cue ball, walls, and pockets. Since these collisions are separated by variable amounts of time, making this plan requires that you jump from one collision event to another without much regard for the intervening duration. This is something that RNNs cannot do.
A professional pool player making a remarkable shot. We'll never know exactly what was going through his head when he did this, but we can say at the very least he was planning over a sequence of collisions. An RNN, by contrast, would focus most of its compute on simulating the linear motion of the ball in between collisions.
Discrete time steps. Another issue with RNNs is that they perceive time as a series of discrete “time steps” that connect neighboring states. Since time is actually a continuous variable – it has a definite value even in between RNN ticks – we really should use models that treat it as such. In other words, when we ask our model what the world looked like at time \( t=1.42\) seconds, it should not have to locate the two ticks that are nearest in time and then interpolate between them, as is the case with RNNs. Rather, it should be able to give a well-defined answer.
Avoiding discrete, uniform timesteps with Neural ODEs. These problems represent some of the core motivations for Neural ODEs. Neural ODEs parameterize the time derivative of the hidden state and, when combined with an ODE integrator, can be used to model dynamical systems where time is a continuous variable. These models represent a young and rapidly expanding area of machine learning research. One unresolved challenge with these models is getting them to run efficiently with adaptive ODE integrators…
The problem is that adaptive ODE integrators must perform several function evaluations in order to estimate local curvature when performing an integration step. The curvature information determines how far the integrator can step forward in time, subject to a constant error budget. This is a particularly serious issue in the context of neural networks, which may have very irregular local curvatures at initialization. A single Neural ODE training step can take up to five times longer to evaluate than a comparable RNN architecture, making it challenging to scale these models.1 The curvature problem has, in fact, already motivated some work on regularizing the curvature of Neural ODEs so as to train them more efficiently.2 But even with regularization, these models are more difficult to train than RNNs. Furthermore, there are many tasks where regularizing curvature is counterproductive, for example, modeling elastic collisions between two bodies.3
Our Results
Our work on piecewise-constant Neural ODEs was an attempt to fix these issues. Our model can jump over different durations of time and can tick more often when a lot is happening and less often otherwise. As I explained earlier, these models are different from regular RNNs in that they predict a hidden state velocity in addition to a hidden state. Taken together, these two quantities represent a linear dynamics function in the RNN’s latent space. A second modification is to have the model predict the duration of time \(\Delta t\) over which its dynamics functions are valid. In some cases, when change is happening at a constant rate, this value can be quite large.
Learning linear motion. To show this more clearly, we conducted a simple toy experiment. We created a toy dataset of perfectly linear motion and checked to see whether our model would learn to summarize the whole thing in one step. As the figure below shows, it learned to do exactly that. Meanwhile, the regular RNN had to summarize the same motion in a series of tiny steps.
Learning a change of basis. Physicists will tell you that the way a system changes over time is only linear with respect to a particular coordinate system. For example, an object undergoing constant circular motion has nonlinear dynamics when we use Cartesian coordinates, but linear dynamics when we use polar coordinates. That’s why physicists use different coordinates to describe different physical systems: all else being equal, the best coordinates are those that are maximally linear with respect to the dynamics.
Since our model forces dynamics to be linear in latent space, the encoder and decoder layers naturally learn to transform input data into a basis where the dynamics are linear. For example, when we train our model on a dataset of circular trajectories represented in Cartesian coordinates, it learns to summarize such trajectories in a single step. This implies that our model has learned a Cartesian-to-Polar change of basis.
Learning from pixel videos. Our model can learn more complicated change-of-basis functions as well. Later in the paper, we trained our model on pixel observations of two billiards balls. The pixel “coordinate system” is extremely nonlinear with respect to the linear motion of the two balls. And yet our model was able to predict the dynamics of the system far more effectively than the baseline model, while using three times fewer “ticks”. The fact that our model could make jumpy predictions on this dataset implies that it found a basis where the billiards dynamics were linear for significant durations of time – something that is strictly impossible in a pixel basis.
In fact, we suspect that forcing dynamics to be linear in latent space actually biased our model to find linear dynamics. We hypothesize that the baseline model performed worse on this task because it had no such inductive bias. This is generally a good inductive bias to build into a model because most real-world dynamics can be approximated with piecewise-linear functions
Planning
One of the reasons we originally set out to build this model was that we wanted to use it for planning. We were struck by the fact that many events one would want to plan over – collisions, in the case of billiards – are separated by variable durations of time. We suspected that a model that could jump through uneventful time intervals would be particularly effective at planning because it could plan over the events that really mattered (eg, collisions).
In order to test this hypothesis, we compared our model to RNN and ODE-RNN baselines on a simple planning task in the billiards environment. The goal was to impart one ball, the “cue ball” (visualized in tan) with an initial velocity such that it would collide with the second ball and the second ball would ultimately enter a target region (visualized in black). You can see videos of such plans at the beginning of this post.
We found that our model used at least half the wall time of the baselines and produced plans with a higher probability of success. These results are preliminary – and part of ongoing work – but they do support our initial hypothesis.
Simulator
Baseline RNN
Baseline ODE-RNN
Our model
85.2%
55.6%
17.0%
61.6%
Related work aside from RNNs and Neural ODEs
Quite a few researchers have wrestled with the same limitations of RNNs and Neural ODEs that we have in this post. For example, there are a number of other RNN-based models designed with temporal abstraction in mind: Koutnik et al. (2014)4 proposed dividing an RNN internal state into groups and only performing cell updates on the \(i^{th}\) group after \(2^{i-1}\) time steps. More recent works have aimed to make this hierarchical structure more adaptive, either by data-specific rules5 or by a learning mechanism6. But although these hierarchical recurrent models can model data at different timescales, they still must perform cell updates at every time step in a sequence and cannot jump over regions of homogeneous change.
For a discussion of these methods (and many others), check out the full paper, which we link to at the top of this post.
Closing thoughts
Neural networks are already a widely used tool, but they still have fundamental limitations. In this post, we reckoned with the fact that they struggle at adaptive timestepping and the computational expense of integration. In order to make RNNs and Neural ODEs more useful in more contexts, it is essential to find solutions to such restrictions. With this in mind, we proposed a PC-ODE model which can skip over long durations of comparatively homogeneous change and focus on pivotal events as the need arises. We hope that this line of work will lead to models that can represent time more efficiently and flexibly.
Jan Koutnik, Klaus Greff, Faustino Gomez, and Juergen Schmidhuber. A Clockwork RNN. International Conference on Machine Learning, pp. 1863–1871, 2014. ↩
Wang Ling, Isabel Trancoso, Chris Dyer, and Alan W Black. Character-based neural machine translation. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2015. ↩
]]>Sam Greydanus, Stefan Lee, and Alan FernScaling down Deep Learning2020-12-01T11:00:00+00:002020-12-01T11:00:00+00:00http://greydanus.github.io/2020/12/01/scaling-down
Constructing the MNIST-1D dataset. As with the original MNIST dataset, the task is to learn to classify the digits 0-9. Unlike the MNIST dataset, which consists of 28x28 images, each of these examples is a one-dimensional sequence of points. To generate an example, we begin with 10 digit templates and then randomly pad, translate, add noise, and transform them as shown above.
By any scientific standard, the Human Genome Project was enormous: it involved billions of dollars of funding, dozens of institutions, and over a decade of accelerated research. But that was only the tip of the iceberg. Long before the project began, scientists were hard at work assembling the intricate science of human genetics. And most of the time, they were not studying humans. The foundational discoveries in genetics centered on far simpler organisms such as peas, molds, fruit flies, and mice. To this day, biologists use these simpler organisms as genetic “minimal working examples” in order to save time, energy, and money. A well-designed experiment with Drosophilia, such as Feany and Bender (2000), can teach us an astonishing amount about humans.
The deep learning analogue of Drosophilia is the MNIST dataset. A large number of deep learning innovations including dropout, Adam, convolutional networks, generative adversarial networks, and variational autoencoders began life as MNIST experiments. Once these innovations proved themselves on small-scale experiments, scientists found ways to scale them to larger and more impactful applications.
They key advantage of Drosophilia and MNIST is that they dramatically accelerate the iteration cycle of exploratory research. In the case of Drosophilia, the fly’s life cycle is just a few days long and its nutritional needs are negligible. This makes it much easier to work with than mammals, especially humans. In the case of MNIST, training a strong classifier takes a few dozen lines of code, less than a minute of walltime, and negligible amounts of electricity. This is a stark contrast to state-of-the-art vision, text, and game-playing models which can take months and hundreds of thousands of dollars of electricity to train.
Yet in spite of its historical significance, MNIST has three notable shortcomings. First, it does a poor job of differentiating between linear, nonlinear, and translation-invariant models. For example, logistic, MLP, and CNN benchmarks obtain 94, 99+, and 99+% accuracy on it. This makes it hard to measure the contribution of a CNN’s spatial priors or to judge the relative effectiveness of different regularization schemes. Second, it is somewhat large for a toy dataset. Each input example is a 784-dimensional vector and thus it takes a non-trivial amount of computation to perform hyperparameter searches or debug a metalearning loop. Third, MNIST is hard to hack. The ideal toy dataset should be procedurally generated so that researchers can smoothly vary parameters such as background noise, translation, and resolution.
In order to address these shortcomings, we propose the MNIST-1D dataset. It is a minimalist, low-memory, and low-compute alternative to MNIST, designed for exploratory deep learning research where rapid iteration is a priority. Training examples are 20 times smaller but they are still better at measuring the difference between 1) linear and nonlinear classifiers and 2) models with and without spatial inductive biases (eg. translation invariance). The dataset is procedurally generated but still permits analogies to real-world digit classification.
Constructing the MNIST-1D dataset. Like MNIST, the classifier's objective is to determine which digit is present in the input. Unlike MNIST, each example is a one-dimensional sequence of points. To generate an example, we begin with a digit template and then randomly pad, translate, and transform it.
Visualizing the performance of common models on the MNIST-1D dataset. This dataset separates them cleanly according to whether they use nonlinear features (logistic regression vs. MLP) or whether they have spatial inductive biases (MLP vs. CNN). Humans do best of all. Best viewed with zoom.
Visualizing the MNIST and MNIST-1D datasets with tSNE. The well-defined clusters in the MNIST plot indicate that the majority of the examples are separable via a kNN classifier in pixel space. The MNIST-1D plot, meanwhile, reveals a lack of well-defined clusters which suggests that learning a nonlinear representation of the data is much more important to achieve successful classification. Thanks to Dmitry Kobak for making this plot.
Example use cases
In this section we will explore several examples of how MNIST-1D can be used to study core “science of deep learning” phenomena.
Finding lottery tickets. It is not unusual for deep learning models to have ten or even a hundred times more parameters than necessary. This overparameterization helps training but increases computational overhead. One solution is to progressively prune weights from a model during training so that the final network is just a fraction of its original size. Although this approach works, conventional wisdom holds that sparse networks do not train well from scratch. Recent work by Frankle & Carbin (2019) challenges this conventional wisdom. The authors report finding sparse subnetworks inside of larger networks that train to equivalent or even higher accuracies. These “lottery ticket” subnetworks can be found through a simple iterative procedure: train a network, prune the smallest weights, and then rewind the remaining weights to their original initializations and retrain.
Since the original paper was published, a multitude of works have sought to explain this phenomenon and then harness it on larger datasets and models. However, very few works have attempted to isolate a “minimal working example” of this effect so as to investigate it more carefully. The figure below shows that the MNIST-1D dataset not only makes this possible, but also enables us to elucidate, via carefully-controlled experiments, some of the reasons for a lottery ticket’s success. Unlike many follow-up experiments on the lottery ticket, this one took just two days of researcher time to produce. The curious reader can also reproduce these results in their browser in a few minutes.
Finding and analyzing lottery tickets. In a-b), we isolate a "minimum viable example" of the effect. Recent work by Morcos et al (2019) shows that lottery tickets can transfer between datasets. We wanted to determine whether spatial inductive biases played a role. So we performed a series of experiments: in c) we plot the asymptotic performance of a 92% sparse ticket. In d) we reverse all the 1D signals in the dataset, effectively preserving spatial structure but changing the location of individual datapoints. This is analogous to flipping an image upside down. Under this ablation, the lottery ticket continues to win.
Next, in e) we permute the indices of the 1D signal, effectively removing spatial structure from the dataset. This ablation hurts lottery ticket performance significantly more, suggesting that part of the lottery ticket's performance can be attributed to a spatial inductive bias. Finally, in f) we keep the lottery ticket sparsity structure but initialize its weights with a different random seed. Contrary to results reported in Frankle & Carbin (2019), we see that our lottery ticket continues to outperform a dense baseline, aligning well with our hypothesis that the lottery ticket mask has a spatial inductive bias. In g), we verify our hypothesis by measuring how often unmasked weights are adjacent to one another in the first layer of our model. The lottery ticket has many more adjacent weights than chance would predict, implying a local connectivity structure which helps give rise to spatial biases.
You can also visualize the actual masks selected via random and lottery pruning:
Visualizing first layer weight masks of random tickets and lottery tickets. For interpretabilty, we have sorted the mask along the hidden layer axis according to the number of adjacent unmasked parameters. This helps reveal a bias towards local connectivity in the lottery ticket masks. Notice how there are many more vertically-adjacent unmasked parameters in the lottery ticket masks. These vertically-adjacent parameters correspond to local connectivity along the input dimension, which in turn biases the sparse model towards data with spatial structure. Best viewed with zoom.
Observing deep double descent. Another intriguing property of neural networks is the “double descent” phenomenon. This phrase refers to a training regime where more data, model parameters, or gradient steps can actually reduce a model’s test accuracy1234. The intuition is that during supervised learning there is an interpolation threshold where the learning procedure, consisting of a model and an optimization algorithm, is just barely able to fit the entire training set. At this threshold there is effectively just one model that can fit the data and this model is very sensitive to label noise and model mis-specification.
Several properties of this effect, such as what factors affect its width and location, are not well understood in the context of deep models. We see the MNIST-1D dataset as a good tool for exploring these properties. In fact, we were able to reproduce the double descent pattern in a Colab notebook after just 25 minutes of walltime. The figure below shows our results for a fully-connected network. You can reproduce these results here.
Observing deep double descent. MNIST-1D is a good environment for determining how to locate the interpolation threshold of deep models.
Gradient-based metalearning. The goal of metalearning is to “learn how to learn.” A model does this by having two levels of optimization: the first is a fast inner loop which corresponds to a traditional learning objective and second is a slow outer loop which updates the “meta” properties of the learning process. One of the simplest examples of metalearning is gradient-based hyperparameter optimization. The concept was was proposed by Bengio (2000) and then scaled to deep learning models by Maclaurin et al. (2015). The basic idea is to implement a fully-differentiable neural network training loop and then backpropagate through the entire process in order to optimize hyperparameters like learning rate and weight decay.
Metalearning is a promising topic but it is very difficult to scale. First of all, metalearning algorithms consume enormous amounts of time and compute. Second of all, implementations tend to grow complex since there are twice as many hyperparameters (one set for each level of optimization) and most deep learning frameworks are not set up well for metalearning. This places an especially high incentive on debugging and iterating metalearning algorithms on small-scale datasets such as MNIST-1D. For example, it took just a few hours to implement and debug the gradient-based hyperparameter optimization of a learning rate shown below. You can reproduce these results here.
Metalearning a learning rate: looking at the third plot, the optimal learning rate appears to be 0.6. Unlike many gradient-based metalearning implementations, ours takes seconds to run and occupies a few dozen lines of code. This allows researchers to iterate on novel ideas before scaling.
Metalearning an activation function. Having implemented a “minimal working example” of gradient-based metalearning, we realized that it permitted a simple and novel extension: metalearning an activation function. With a few more hours of researcher time, we were able to parameterize our classifier’s activation function with a second neural network and then learn the weights using meta-gradients. Shown below, our learned activation function substantially outperforms baseline nonlinearities such as ReLU, Elu5, and Swish6. You can reproduce these results here.
Metalearning an activation function. Starting from an ELU shape, we use gradient-based metalearning to find the optimal activation function of a neural network trained on the MNIST-1D dataset. The activation function itself is parameterized by a second (meta) neural network. Note that the ELU baseline (red) is obscured by the tanh baseline (blue) in the figure above.
We transferred this activation function to convolutional models trained on MNIST and CIFAR-10 images and found that it achieves middle-of-the-pack performance. It is especially good at producing low training loss early in optimization, which is the objective that it was trained on in MNIST-1D. When we rank nonlinearities by final test loss, though, it achieves middle-of-the-pack performance. We suspect that running the same metalearning algorithm on larger models and datasets would further refine our activation function, allowing it to at least match the best hand-designed activation function. We leave this to future work, though.
Measuring the spatial priors of deep networks. A large part of deep learning’s success is rooted in “deep priors” which include hard-coded translation invariances (e.g., convolutional filters), clever architectural choices (e.g., self-attention layers), and well-conditioned optimization landscapes (e.g., batch normalization). Principle among these priors is the translation invariance of convolution. A primary motivation for this dataset was to construct a toy problem that could effectively quantify a model’s spatial priors. The second figure in this post illustrates that this is indeed possible with MNIST-1D. One could imagine that other models with more moderate spatial priors would sit somewhere along the continuum between the MLP and CNN benchmarks. Reproduce here.
Benchmarking pooling methods. Our final case study begins with a specific question: What is the relationship between pooling and sample efficiency? We had not seen evidence that pooling makes models more or less sample efficient, but this seemed an important relationship to understand. With this in mind, we trained models with different pooling methods and training set sizes and found that, while pooling tended to be effective in low-data regimes, it did not make much of a difference in high-data regimes. We do not fully understand this effect, but hypothesize that pooling is a mediocre architectural prior which is better than nothing in low-data regimes and then ends up restricting model expression in high-data regimes. By the same token, max-pooling may also be a good architectural prior in the low-data regime, but start to delete information – and thus perform worse compared to L2 pooling – in the high-data regime. Reproduce here.
Benchmarking common pooling methods. We observe that pooling helps performance in low-data regimes and hinders it in high-data regimes. While we do not entirely understand this effect, we hypothesize that pooling is a mediocre architectural prior that is better than nothing in low-data regimes but becomes overly restrictive in high-data regimes.
When to scale
This post is not an argument against large-scale machine learning research. That sort of research has proven its worth time and again and has come to represent one of the most exciting aspects of the ML research ecosystem. Rather, this post argues in favor of small-scale machine learning research. Neural networks do not have problems with scaling or performance – but they do have problems with interpretability, reproducibility, and iteration speed. We see carefully-controlled, small-scale experiments as a great way to address these problems.
In fact, small-scale research is complimentary to large-scale research. As in biology, where fruit fly genetics helped guide the Human Genome Project, we believe that small-scale research should always have an eye on how to successfully scale. For example, several of the findings reported in this post are at the point where they should be investigated at scale. We would like to show that large scale lottery tickets also learn spatial inductive biases, and show evidence that they develop local connectivity. We would also like to try metalearning an activation function on a larger model in the hopes of finding an activation that will outperform ReLU and Swish in generality.
We should emphasize that we are only ready to scale these results now that we have isolated and understood them in a controlled setting. We believe that scaling a system is only a good idea once the relevant causal mechanisms have been isolated and understood.
Other small datasets
The core inspiration for this work stems from an admiration of and, we daresay, infatuation with the MNIST dataset. While it has some notable flaws – some of which we have addressed – it also has many lovable qualities and underappreciated strengths: it is simple, intuitive, and provides the perfect sandbox for exploring creative new ideas.
Our work also bears philosophical similarities to the Synthetic Petri Dish by Rawal et al. (2020). It was published concurrently and the authors make similar references to biology in order to motivate the use of small synthetic datasets for exploratory research. Their work differs from ours in that they use metalearning to obtain their datasets whereas we construct ours by hand. The purpose of the Synthetic Petri Dish is to accelerate neural architecture search whereas the purpose of our dataset is to accelerate “science of deep learning” questions.
There are many other small-scale datasets that are commonly used to investigate “science of deep learning” questions. The examples in the CIFAR-10 dataset are four times larger than MNIST examples but the total number of training examples is the same. CIFAR-10 does a better job of discriminating between MLP and CNN architectures, and between various CNN architectures such as vanilla CNNs versus ResNets. The FashionMNIST dataset is the same size as MNIST but a bit more difficult. One last option is Scikit-learn’s datasets: there are dozens of options, some synthetic and others real. But making real world analogies to, say, digit classification, is not possible and one can often do very well on them using simple linear or kernel-based methods.
Closing thoughts
There is a counterintuitive possibility that in order to explore the limits of how large we can scale neural networks, we may need to explore the limits of how small we can scale them first. Scaling models and datasets downward in a way that preserves the nuances of their behaviors at scale will allow researchers to iterate quickly on fundamental and creative ideas. This fast iteration cycle is the best way of obtaining insights about how to incorporate progressively more complex inductive biases into our models. We can then transfer these inductive biases across spatial scales in order to dramatically improve the sample efficiency and generalization properties of large-scale models. We see the humble MNIST-1D dataset as a first step in that direction.
]]>Sam GreydanusOptimizing a Wing Inside a Fluid Simulation2020-10-14T11:00:00+00:002020-10-14T11:00:00+00:00http://greydanus.github.io/2020/10/14/optimizing-a-wing(My last post in a series about human flight; post 1, post 2).
Figure 1: In this post, we'll simulate a wind tunnel, place a rectangular occlusion in it, and then use gradient descent to turn it into a wing.
[The images above are videos. Click to pause or play.]
Legos are an excellent meta-toy in that they represent the potential for a near-infinite number of toys depending on how you assemble them. Each brick has structure. But each brick is only interesting to the extent that it can combine with other bricks, forming new and more complex structures. So in order to enjoy Legos, you have to figure out how they fit together and come up with a clever way of making the particular toy you have in mind. Once you have mastered a few simple rules, the open-ended design of Lego bricks lets you build anything you can imagine.
Our universe has the same versatile structure. It seems to run according to just a few simple forces, but as those forces interact, they give rise to intricate patterns across many scales of space and time. You see this everywhere you look in nature – in the fractal design of a seashell or the intricate polities of a coral. In the convection of a teacup or the circulation of the atmosphere. And this simple structure even determines the shape and behavior of man’s most complicated flying machines.
To see this more clearly, we are going to start from the basic physical laws of airflow and use them to derive the shape of a wing.1 Since we are using so few assumptions, the wing shape we come up with will be as fundamental as the physics of the air that swirls around it. This is pretty fundamental. In fact, if an alien species started building flying machines on another planet, they would probably converge on a similar shape.
Navier-Stokes
We will begin this journey with the Navier-Stokes equation, which sums up pretty much everything we know about fluid dynamics. It describes how tiny fluid parcels interact with their neighbors. The process of solving fluid dynamics problems comes down to writing out this equation and then deciding which terms we can safely ignore. In our case, we would like to simulate the flow of air through a wind tunnel and then use it to evaluate various wing shapes.
Since the pressure differences across a wind tunnel are small, one of the first assumptions we can make is that air is incompressible. This lets us use the incompressible form of the Navier-Stokes equation:
Another term we can ignore is viscous diffusion. Viscous diffusion describes how fluid parcels distribute their momenta due to sticky interactions with their neighbors. We would say that a fluid with high viscosity is “thick”: common examples include molasses and motor oil. Even though air is much thinner, viscous interactions still cause a layer of slow-moving air to form along the surface of an airplane wing. However, we can ignore this boundary layer because its contribution to the aerodynamics of the wing is small compared to that of self-advection.
The final term we can ignore is the forces term, as there will be no forces on the air once it enters the wind tunnel. And so we are left with but a hair of the original Navier-Stokes hairball:
This simple expression describes the effects that really dominate wind tunnel physics. It says, intuitively, that “the change in velocity over time is due to the fact that velocity follows itself.” So the entire simulation comes down to two simple rules:
Rule 1: Velocity follows itself
(+)
The technical term for this effect is "self-advection." Advection is when a field, say, of smoke, is moved around by the velocity of a fluid. Self-advection is a special case where the field being advected is the velocity field, and so it actually advects itself. In principle, a self-advection step is as simple as moving the velocity field according to x' = v * dt + x at every point on the grid. We can simulate self-advection over time by repeating this over and over again.
Rule 2: Volume is conserved
(+)
This rule comes from our incompressibility assumption and the process of enforcing it is called projection. Since volume is conserved, fluid parcels can only move into positions that their neighbors have recently vacated. This puts a strong constraint on our simulation's velocity field: it needs to be volume-conserving. Fortunately, Helmholtz’s theorem tells us that any vector field can be decomposed into an incompressible field and a gradient field, as a figure from this paper shows:
One way to make our velocity field incompressible is to find the gradient field and then subtract it from the original field as shown above. This projects our velocity field onto a volume-conserving manifold.
By alternating between these two rules, we can iteratively 1) move the system forward in time and 2) enforce conservation of volume and mass. In practice, we implement each rule as a separate function and then apply both functions to the system at every time step. This allows us to simulate, say, a gust of wind passing through the wind tunnel. But before we can direct this wind over a wing, we need to decide how to represent the wing itself.
Representing the Wing
The wing is an internal boundary, or occlusion, of the flow. A good way to represent an occlusion is with a mask of zeros and ones. But since the goal of our wind tunnel is to try out different wing shapes, we need our wing to be continuously deformable. So we will allow the mask to take on continuous values between zero and one, making it semi-permeable in proportion to its mask values. This lets us add semi-permeable obstructions to the wind tunnel as shown:
(+)
A note on filtering. In practice, the wing is still not quite continuously deformable. Big differences in the mask at neighboring grid points can lead to sharp boundary conditions and non-physical airflows around the mask. One way to reduce this effect is to apply a Gaussian filter around the edges of the mask so as to prevent these grid-level pathologies. This approach may seem a bit arbitrary at first glance, but it is actually a common simulation technique used in, for example, topology optimization, largeeddy simulation, and 3D graphics.
Mask = 0.0
Mask = 0.05
Mask = 0.12
Mask = 0.5
Mask = 1.0
Choosing an Objective
Now we are at the point where we can simulate how air flows over arbitrary, semi-permeable shapes. But in order to determine which of these shapes makes a better wing, we still need to define a measure of performance. There are many qualities that one could look for in a good wing, but we will begin with the most obvious: it should convert horizontal air velocity into upward force as efficiently as possible. We can measure this ability using something called the lift-drag ratio where “lift” measures the upward force generated by the wing and “drag” measures the frictional forces between the air and the wing. Since “change in downward airflow” in the tunnel is proportional to the upward force on the wing, we can use it as a proxy for lift. Likewise, “change in rightward airflow” is a good proxy for the drag forces on the wing. With this in mind, we can write out the objective function as
\[\max_{\theta} L/D\]
where \(\theta\) represents some tunable parameters associated with the shape of the wing mask and \(L/D\) can be obtained using the initial and final wind velocities of the simulation according to
Solving this optimization problem will give us a wing shape that generates the most efficient lift possible. In other words, we new have the correct problem setup; what remains is to figure out how to solve it.
Optimization
We are going to solve this problem with gradient ascent. Gradient ascent is simple and easy to implement, but there is one important caveat: we need a way to efficiently compute the gradient of the objective function with respect to the wing mask parameters. This involves differentiating through each step of the fluid simulation in turn – all of the way back to the initial conditions. This would be difficult to implement by hand, but fortunately there is a tool called Autograd which can perform this back-propagation of gradients automatically. We will use Autograd to compute the gradients of the mask parameters, move the mask parameters in that direction, and then repeat this process until the lift-drag ratio reaches a local maximum.
(+)
A note on Autograd. Amazingly, every mathematical operation we've described so far – from the wing masking operation to the advection and projection functions to the lift-drag ratio – is differentiable. This is why we can use Autograd to compute analytic gradients with respect to the mask parameters. Autograd uses automatic differentiation, closely related to the adjoint method, to propagate gradient information backwards through the simulation until it reaches the parameters of the wing mask. We can do all of this in a one-line function transformation:grad_fn = autograd.value_and_grad(get_lift_drag_ratio).
So let’s review. Our goal is to simulate a wind tunnel and use it to derive a wing shape. We began by writing down the general Navier-Stokes equation and eliminating irrelevant terms: all of them but self-advection. Next, we figured out how to represent a wing shape in the tunnel using a continuously-deformable occlusion. Finally, we wrote down an equation for what a good wing should do and discussed how to optimize it. Now it is time to put everything together in about two hundred lines of code and see what happens when we run it…
Final result
[Click image to pause or play.]
Sure enough, we get a beautiful little wing. Of all possible shapes, this is the very best one for creating efficient lift in our wind tunnel. This wing is definitely a toy solution since our simulation is coarse and not especially accurate. However, after making a few simple improvements we would be able to design real airplane wings this way. We would just need to:
Simulate in 3D instead of 2D
Use a mesh parameterization instead of a grid
Make the flow laminar and compressible
Aside from these improvements, the overall principle is much the same. In both cases, we write down some words and symbols, turn them into code, and then use the code to shape our wing.2 The fact that we can do all of this without ever building a physical wing makes it feel a bit like magic. But this process really works, for when we put these wings on airplanes and trust them with our lives, they carry us safely to our destinations.34
Just like the real wind tunnels of the twentieth century, these simulated wind tunnels need to go through lots of debugging before we can trust them. In fact, while building this demo we discovered a number of ways that things can go wrong. Here are some of the most amusing failure cases:
Several of these wings are just plain dreadful. But others seem reasonable, if unexpected. The two-wing solution is particularly amusing. We did not intend for this “biplane” solution to occur, and yet it is a completely viable way of solving the objective we wrote down. One advantage to keeping the problem setup so simple is that, in doing so, we left space for these surprising behaviors to occur.
The Manifold of Solutions
There are variations on the base wing shape which excel in particular niches. Sometimes we will want a wing that is optimal at high speeds and other times we will want one that is optimal at low speeds. In order to accommodate a large fuselage, we might want an extra-thick wing. Alternatively, in order to reduce its overall weight, we might want to keep it thin. It turns out that we can change simulation parameters and add auxiliary losses to find optimal wing shapes for each of these scenarios.
Our wind tunnel simulation is interesting first, because it illustrates how the Platonic ideal of wing design is rooted in the laws of physics. As we saw in the earlier posts, there were many cultural and technological forces that contributed to airfoil design. These forces were important for many reasons, but they were not the primary factor in the wing shapes they produced – physics was.
But to balance this idea, we have also shown how a million variants of the Platonic form of a wing can fulfill particular needs. Indeed, these variants could be said to occupy complimentary niches in the same way that different birds and flying insects occupy different niches in nature. After all, even though nature follows the laws of physics with absolute precision, she takes a consummate joy in variation. Look at the variety of wing shapes in birds, for example.5 Species of hummingbirds have wings with low aspect ratios that enable quick, agile flight patterns. Other birds, like the albatross, have high aspect ratios for extreme efficiency. Still others, like the common raven, are good all-around fliers. Remarkably, we are beginning to see this same speciation occur in modern aircraft as well. There are surveillance planes built for speed and stealth, short-winged bush planes built for maneuverability, and massive commercial airliners built for efficiency.6
A figure from Lockwood (1998) arranging bird species by wing pointedness and wingtip convexity. Different wing designs stem from adaptations to different ecological niches.
A plot by Lindhe (2002) showing aspect ratio versus wing loading index in some birds, airplanes, a hang-glider, a butterfly, and a maple seed. Just like the families of birds, different human flying machines display substantial variation along these axes.
Perhaps less intuitively, even a single bird is capable of a huge range of wing shapes. The falcon, for example, uses different wing shapes for soaring, diving, turning, and landing. Its wings are not static things, but rather deformable, dynamic objects which are constantly adapting to their surroundings. And once again, we are beginning to see the same thing happen in modern aircrafts like the Boeing 747. The figure below shows how its triple-slotted wing design lets pilots reconfigure the airfoil shape during takeoff, cruising, and landing.
Closing Thoughts
One of the lessons from attempting to optimize a wing is that the optimization itself is never the full story. When we write down the optimization objective (like we did above), our minds already have a vague desire to obtain a wing. And behind that desire, our minds may want to obtain a wing because we are drawn to the technology of flight. And perhaps we are drawn to flight for the same reasons that the early aviators were – because it promises freedom, glory, and adventure. And behind those desires – what? The paradox of an objective function is that it always seems to have a deeper objective behind it.
The deeper objectives do not change as quickly. Even as the early aviators progressed from wingsuits to gliders to planes, they retained the same fundamental desire to fly. Their specific desires, of course, were different: some wanted to survive a tower jump and others wanted to break the speed of sound. And their specific desires led to specific improvements in technology such as a better understanding of the Smeaton coefficient or a stable supercritical airfoil. Once they made these improvements, the next generation was able to use them to pursue more ambitious goals. But even as this cycle progressed, the more deeply-held desire to fly continued to inspire and unify their efforts.
Thanks
Thanks to Maclaurin et al. (2018) for releasing Autograd1 to the world along with a number of thought-provoking demos.
Thanks to Stephan Hoyer, Shan Carter, and Matthew Johnson for conversations that shaped some of the early versions
of this work. And thanks to Andrew Sosanya, Jason Yosinski, and Tina White for feedback on early versions of this
essay. Special thanks to my family and friends for serving as guinea pigs for early iterations of this story.
]]>Sam GreydanusThe Stepping Stones of Flight2020-10-13T11:00:00+00:002020-10-13T11:00:00+00:00http://greydanus.github.io/2020/10/13/stepping-stonesBy the year 1900, humans seemed to have figured out all the important ideas of aviation. There were patents for dozens of self-powered aircrafts including biplanes,1 seaplanes,2 and bombers.3 There were also designs for retractable landing gear,4 aileron wing controls,5 and curved airfoils.6 To many people, these designs indicated that the age of the airplane was at hand. Indeed, by this time there were already two commercial airline startups7 and one program for constructing bombers, fully funded by the French government.3 But there was just one problem: nobody had managed to fly a real airplane yet. In fact, the Wright brothers were still several years from achieving that breakthrough. As for bombers, seaplanes, and airline companies – such things were still many decades away.
This bizarre gap between theory and practice brings into question the meaning of the word invention. Generally speaking, one would think of an invention as a detailed design of the sort that could be patented. But in the case of the airplane, dozens of people patented airplanes that never could have flown. Did those people really invent airplanes? Otto Lilienthal, the first glider pilot, would have answered in the negative. “To design an aircraft is nothing” he wrote, “To build one is something. But to fly is everything.”
Otto Lilienthal
Airfoils
In order to focus on the practical stepping stones of flight, let’s adopt Lilienthal’s perspective. In other words, let’s focus on the changes in wing design that led to the most significant empirical improvements in flight. When we start down this path, one of the first things we notice is that most of these improvements are related to the cross-sectional shape of a wing, also known as the airfoil. Generally speaking, an airfoil has no moving parts. In fact, it is just a two-dimensional shape that influences the speed of air above and below a wing. Prior to the Wright brothers, few people gave serious thought to airfoil design. But it just so happened that the details of this shape play a critical role in determining the lift and drag profile of a wing. Only through repeated iteration of design and demonstration did we become aware of the airfoil’s surprising complexity.
Lilienthal, with his emphasis on practical results, was the first person to realize how much airfoils matter. They came to his attention when he set out to build a glider that could support the weight of a man. In order to build such an apparatus, he needed to know how the lift and drag characteristics of various wings scaled with length, width, and thickness. In thinking about these questions, he quickly realized that the cross-sectional shape was an important design parameter. He started by studying the airfoils of bird wings, especially those of storks. Then, with their shapes in mind, he built artificial replicas in his laboratory and tested their lift coefficients. These methodical experiments took nearly twenty years of work, after which he published his findings in his thorough (and beautifully illustrated) book, Birdflight as the Basis of Aviation.8 Taking what he had learned from biology, Lilienthal spent the latter part of his life building and flying human-scale gliders – the first winged flying machines that could carry a human through the air. And so, with an eye on nature and great attention to detail, Lilienthal achieved the goal he had been working towards since his twenties.
But even Lilienthal, for all his care, made some errors. The Wright brothers used his results to design their first glider, and when that glider crashed unexpectedly, they realized that something was wrong. After performing their own set of wind tunnel experiments, they determined that the widely-accepted value of the Smeaton coefficient – a key part of Lilienthal’s lift and drag equations – was about 60% too high.9 Starting from this discovery, they reworked their entire wing design. They tested out hundreds of airfoils in a miniature wind tunnel and finally settled on a new airfoil shape. It was slightly wider and more arched, and the highest point of its arch was closer to the front of the wing (more “forward camber”). In spite of these changes, it looked only slightly different from their original wing shape. And yet its improved lift and stability was what the Wrights needed in order to build the world’s first self-propelled airplane.
A figure from Otto Lilienthal's book Birdflight as the Basis of Aviation. Lilienthal studied bird wings and carried out small scale experiments for two decades (1867-1889) in preparation for building his gliders.
Years of careful experiments by the Wright brothers yielded a new wing shape with a slightly more forward camber. This seemingly small change was crucial to the Flyer's success..
Although Lilienthal and the Wrights lived on different continents and had very different lives, they were united by the fact that they each spent years doing tedious, small-scale experiments in order to understand flight on a deep level. Only after this exploratory phase did they build real flying machines. In a way, those long hours of tedium are a sacrifice one must make when they set out to pursue the romantic ideal of flight. In profiling the early aviators, we saw that the frontier of flight often attracted radical and temperamental dreamers. These were not reliable people. And yet each of them had to discipline and civilize themselves, becoming the most practical of the lot of us, before they could become heroes. Interestingly, the next breakthroughs in flight were to involve the same dynamic, but this time playing out across nations rather than individuals. This was the era of the national labs.
The National Labs
National labs were a new phenomenon that emerged in the 1910’s and 1920’s as forward-thinking governments started to reckon with the military and economic applications of flight. Leading up to World War I, airplanes were still slow, unreliable, and expensive. They were great for stunts and parades, but close to useless on the battlefield. One of the main goals of the national labs was to change this.
The first improvements in airfoil design came out of Britain’s National Physical Laboratory. Managers at this lab used its infrastructure and manpower to test airfoil designs much more thoroughly than the hobbyist-inventors before them. One of their key findings was that thicker wings with even more forward camber gave better lift. As soon as they made this discovery, they built it into military planes like the Airco DH.2 fighter (1915) and the Vickers Vimy bomber (1917).
But even though these changes in airfoil design improved lift, they did not improve stability. World War I era biplanes suffered from a dangerous effect called “thin airfoil stall.” This effect occurred when streams of air above and below a wing collided behind it, creating unpredictable drag and sending the plane into a stall. German engineers were the first to find a solution to this problem. They found that thicker airfoils like the Göttingen 398 could mitigate thin airfoil stall and make fighter planes more maneuverable. They used these insights to build the Fokker Dr. I (1917) which was one of the most dangerous fighters of the war.10
The most amazing thing about flight research during World War I was the speed at which national labs turned research into real technology. Often it only took a year or two. The condensed timeline and extreme real-world impact of airplanes led to dramatic improvements in their designs and finalized their transition from the world of ideas to the world of things. And the wonderful thing about having an idea take root in the world is its tendency to become the bedrock for an entirely new generation of ideas.
That is the story of the 1920’s and 1930’s, which is when the mathematical theory of flight got started. Government physicists in the United States finally had time to come up with theories that explained experimental results. Then they used these theories to make airfoils better in small but important ways. Their work culminated in the 1933 National Advisory Committee for Aeronautics (NACA) Report 460, which set the industry standard for the next several decades. World War II planes like the DC-2 transport and the B-17 Flying Fortress used these results.11 And after the war, designs like the NACA 2412 found their way into commercial plane designs, some of which are still in use today.
The 1901 wind tunnel that the Wright brothers used to study airfoil shapes.
A man standing in the enormous Langley wind tunnel in 1925.
The progression of notable airfoils developed by national labs between 1915 and 1945.
The process of minor improvements based on theory continued into the 1940’s, when NACA researchers invented the laminar flow airfoil and installed it on the P-51 Mustang.11 In practice, the laminar flow “correction” was rather small and it led to modest improvements. But it represented a milestone in that it was one of the first major innovations motivated by theory rather than human intuition or observations of biology. Focusing on the causal mechanisms of flight ended up being crucial for later innovations in the supersonic regime since the way air behaves at those speeds is much less intuitive.
In fact, there is a deep connection between how well we understand the laws of nature and what we can build in the world. The laws of nature are the rules of the game. We are constantly learning more about these rules and we can only innovate in proportion to how well we understand them. To see this, consider evolution for a moment. Over millions of years, it has deformed life so as to probe the laws of nature at many different scales. So with time, the fundamental forces of nature have constrained and shaped life into the variety of forms we see today. Human design mimics this trial-and-error approach, but our mental models of the world give us an advantage. They speed our search in proportion to how much of the physical world they can explain. And by acting on our mental models, we can make intuitive leaps that evolution, in all of its billions of years, never could have managed. One such intuitive leap was made by Richard Whitcomb when he discovered supercritical airfoils.
Supercritical Airfoils
This discovery occurred in 1965, which was a time when the aerospace industry was trying to improve supersonic flight. Jet engines, which were invented at the end of World War II, had improved to the point where they produced enough force to accelerate planes to supersonic speeds. But once planes reached these speeds, the physics of airflow started to change and existing airfoil designs stopped working. NACA researchers realized that they would have to rethink every aspect of wing design in order to adapt. One of the most challenging problems was what to do with airfoil design.11
At the time, many of Whitcomb’s colleagues were looking for solutions in aerodynamic theory. Whitcomb took a different approach: he grabbed a can of putty and headed for the Langley wind tunnel.12 He knew that the problem with existing airfoils was that air flowed at a higher rate around the top of the wing than the bottom. As the plane approached supersonic speeds, the air on top was the first to hit the sound barrier. Energy, normally dissipated as sound, would then be moving at the same speed as the air itself and slowly start to accumulate. A shock wave would form. Then the shock wave would create all sorts of pathological drag and instabilities.13
With this in mind, Whitcomb used putty to decrease the camber of the wing so as to lower the airspeed above it. Then he added a slight concavity to the underside of the wing to maintain lift and stability. All of this was based on his intuition for how air flowed over a wing at high speeds, but it ended up being extraordinarily effective. His “supercritical” wing design allowed the United States to build the fastest bombers, fighters, and reconnaissance planes of the Cold War. And surprisingly, this wing design turned out to be stable and efficient even at subsonic speeds. Today’s commercial airliners, which cruise at speeds around Mach 0.85, all use supercritical airfoils to improve fuel efficiency.
Looking over the history of wing design, it is easy to see that the boundary between imagination and the constraints of the real world is where invention happens. When ideas are fully constrained to our minds, we have the tendency to indulge in impractical fantasies. And yet we need imagination too. For without it, we are limited to the incremental trial-and-error pace of evolution. Imagination is our one clear advantage over evolution, for it requires no intermediary. For evolution to invent a wing, there needed to be a half-winged precursor. But imagination has a strangely liberating effect in that it allows us to move from the ground to the sky in a single intuitive leap.
An evolutionary pathway from small sauropods to flying birds, proposed by Kurochkin and Bogdanovich (2010). Each intermediary took hundreds of thousands of years of natural selection.
The Supermarine Spitfire (top) was one of the fastest planes of World War II. The Bell X-1 (bottom) unseated the Spitfire and broke the sound barrier a few years later. Notice how different the two planes look; human design lacks intermediaries.
Physical Theories
Since the first half of the twentieth century when the core breakthroughs of aeronautics occurred, scientists have been hard at work on physical theories that can explain those breakthroughs. These theories have expanded into fields of study like “computational fluid dynamics,” “aeronautical science,” and “turbulent flow.” Such principles are quite complex, but the question they aim to answer is simple: how do wings work? We are going to answer that question in the next section by obtaining our own wing starting from nothing but the physics of airflow.
Here is a complete timeline of the airfoils we discussed in this post. Outlines in the first three columns were obtained from primary sources and are technically accurate. Outlines in the fourth row are believed to be technically accurate – or close 🤷♂️
Allward, Maurice. An Illustrated History of Seaplanes and Flying Boats, New York: Dorset Press, p. 11, 1981. ↩
Crosby, Francis. The Complete Guide to Fighters & Bombers of the World: An Illustrated History of the World’s Greatest Military Aircraft, London: Anness Publishing Ltd., p. 16, 2006. ↩↩2
Gibbs-Smith, Charles Harvard. Aviation. London: NMSI, p. 57, 2003. ↩
Boulton, Matthew Piers Watt. On Aerial Locomotion. Bradbury & Evans, London, 1864. ↩
National Air and Space Museum. The Ariel: The First Carriage Of The Ærial Transit Company. National Air and Space Museum Collection, 1843. ↩
Otto Lilienthal. Birdflight as the Basis of Aviation. Longmans, Green, and Co., London, 1 edition, 1889. ↩
The wrong value of this coefficient had been in use for more than a hundred years and was part of the accepted equation for lift. So in determining that this number was wrong, the Wrights made a major discovery. ↩
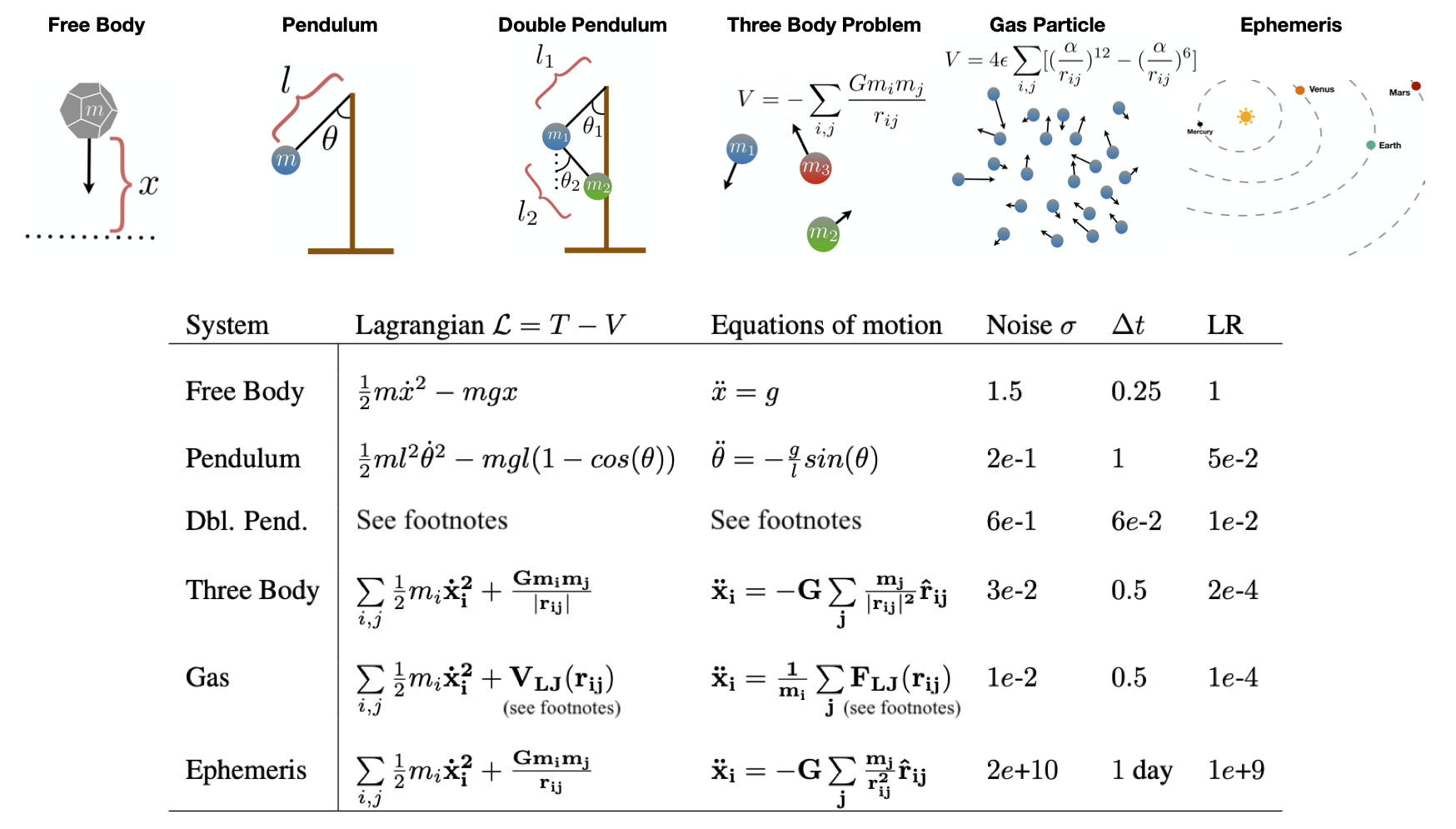
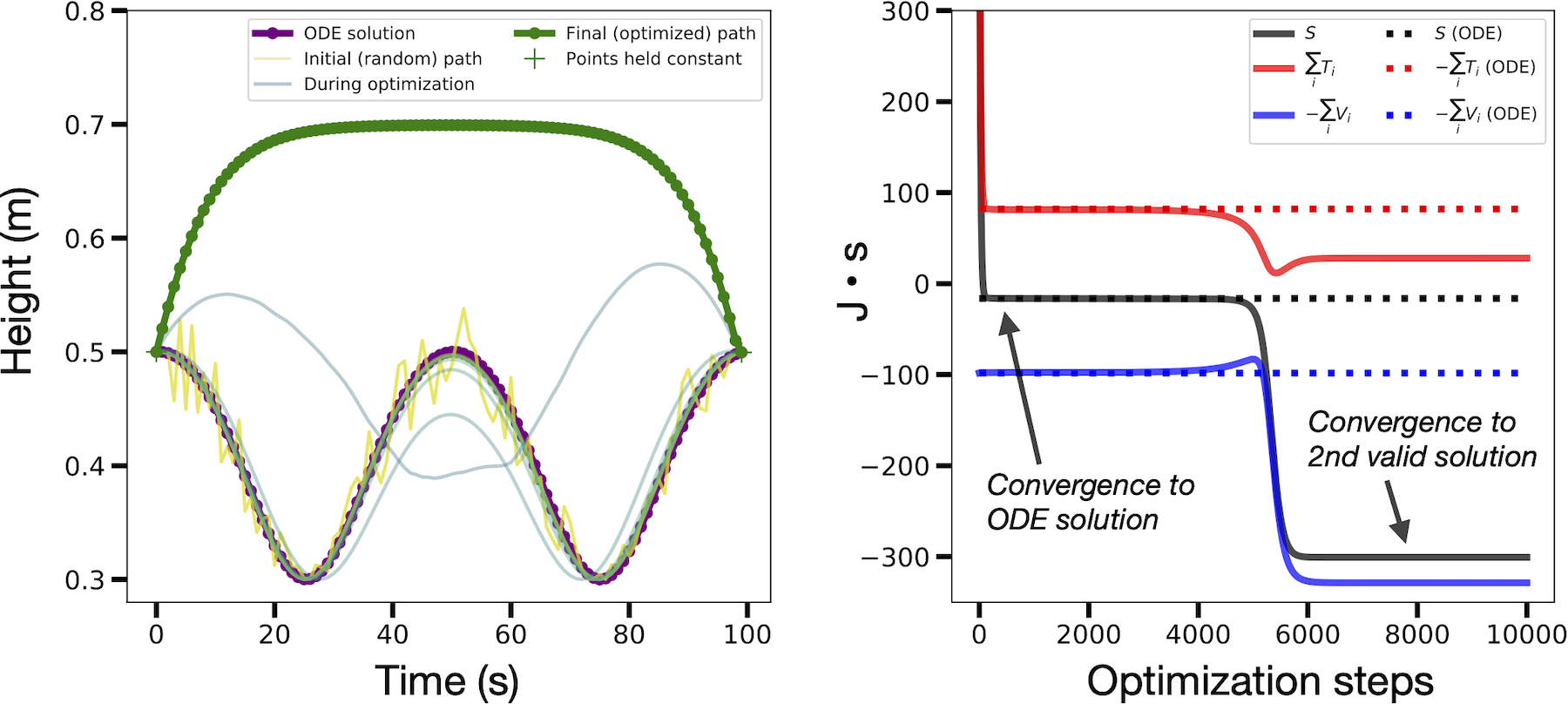
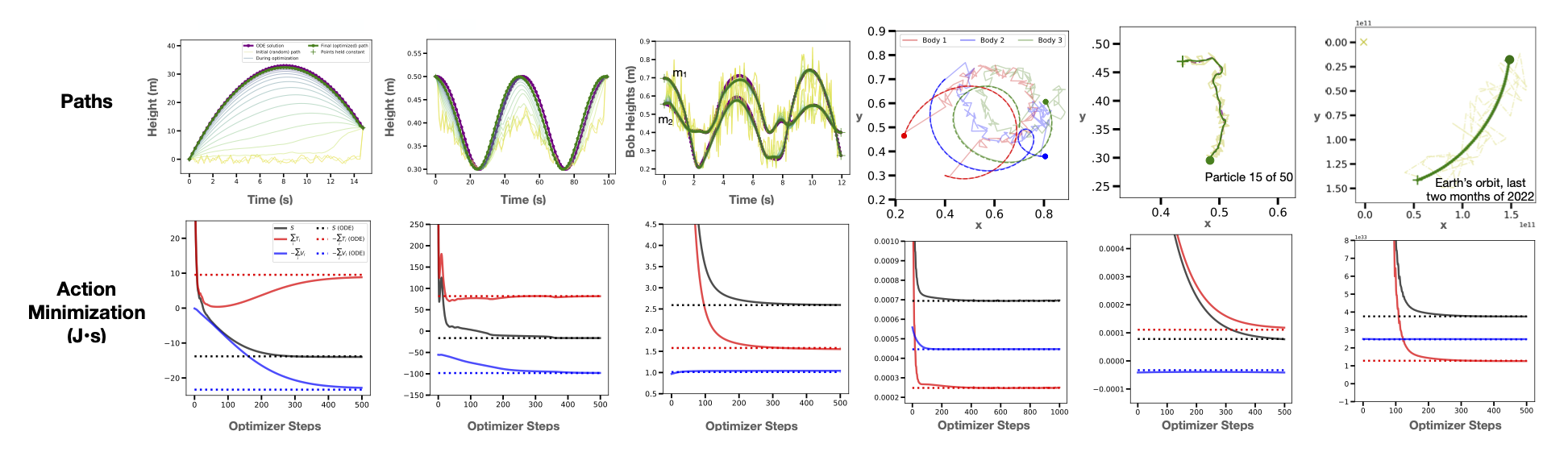

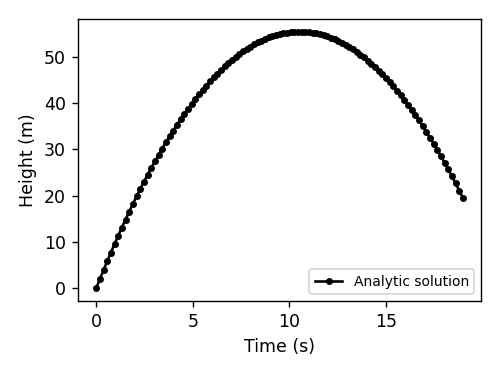
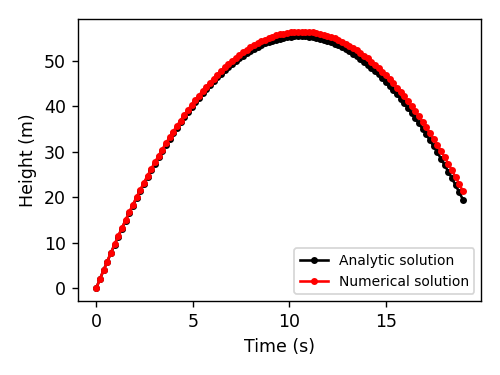
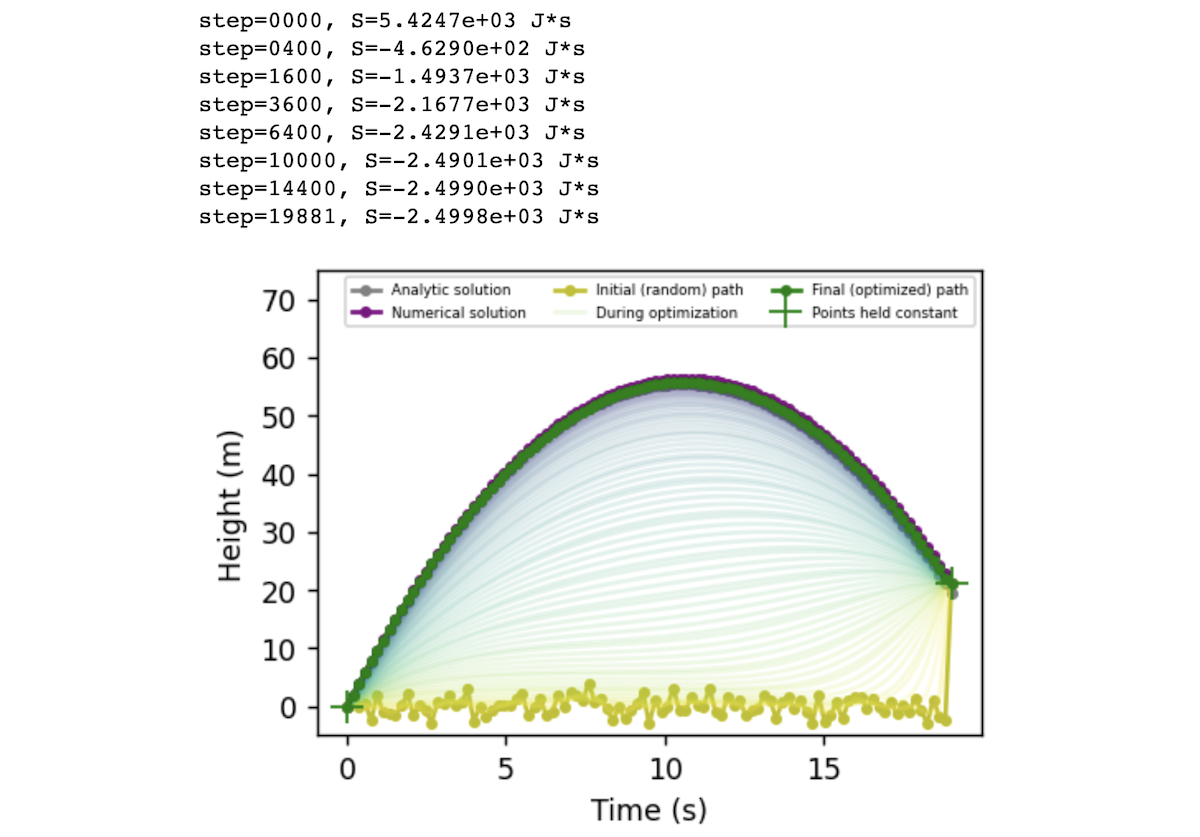
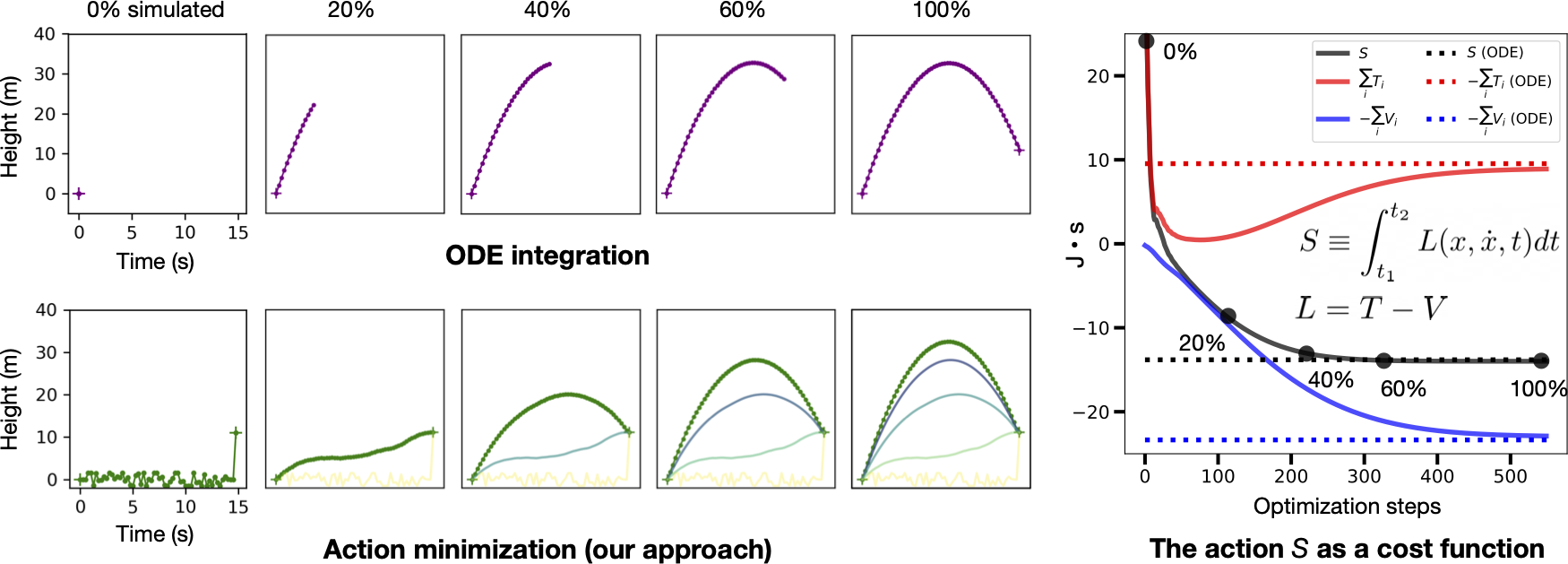
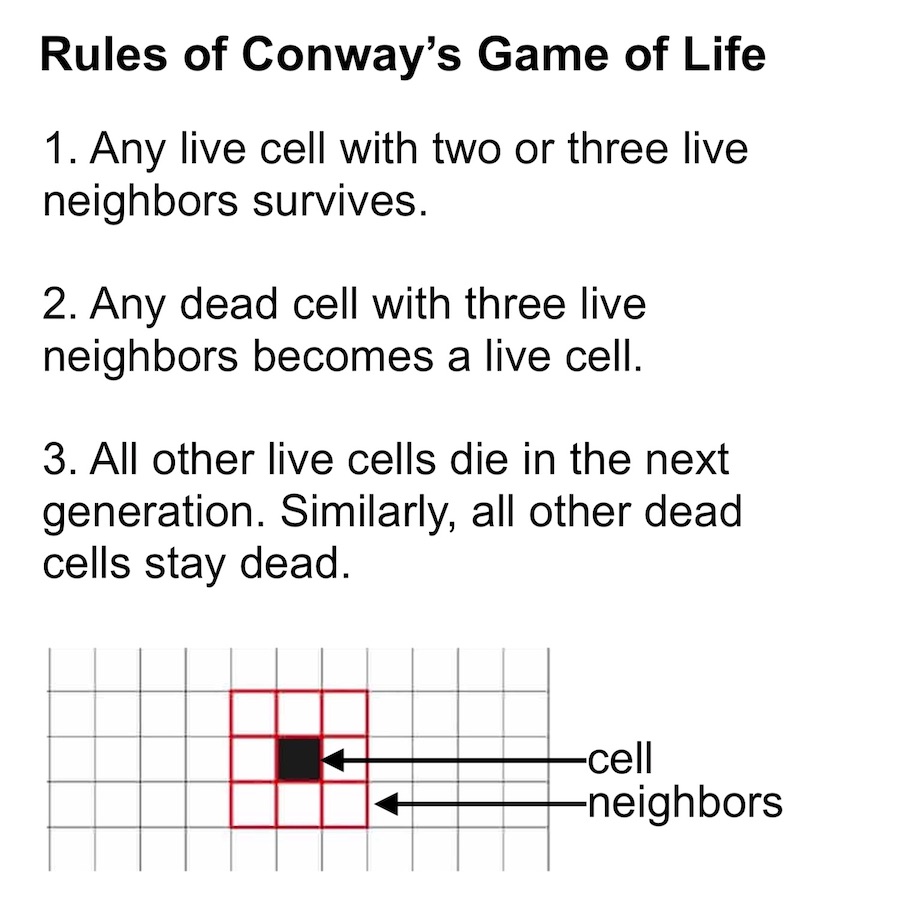
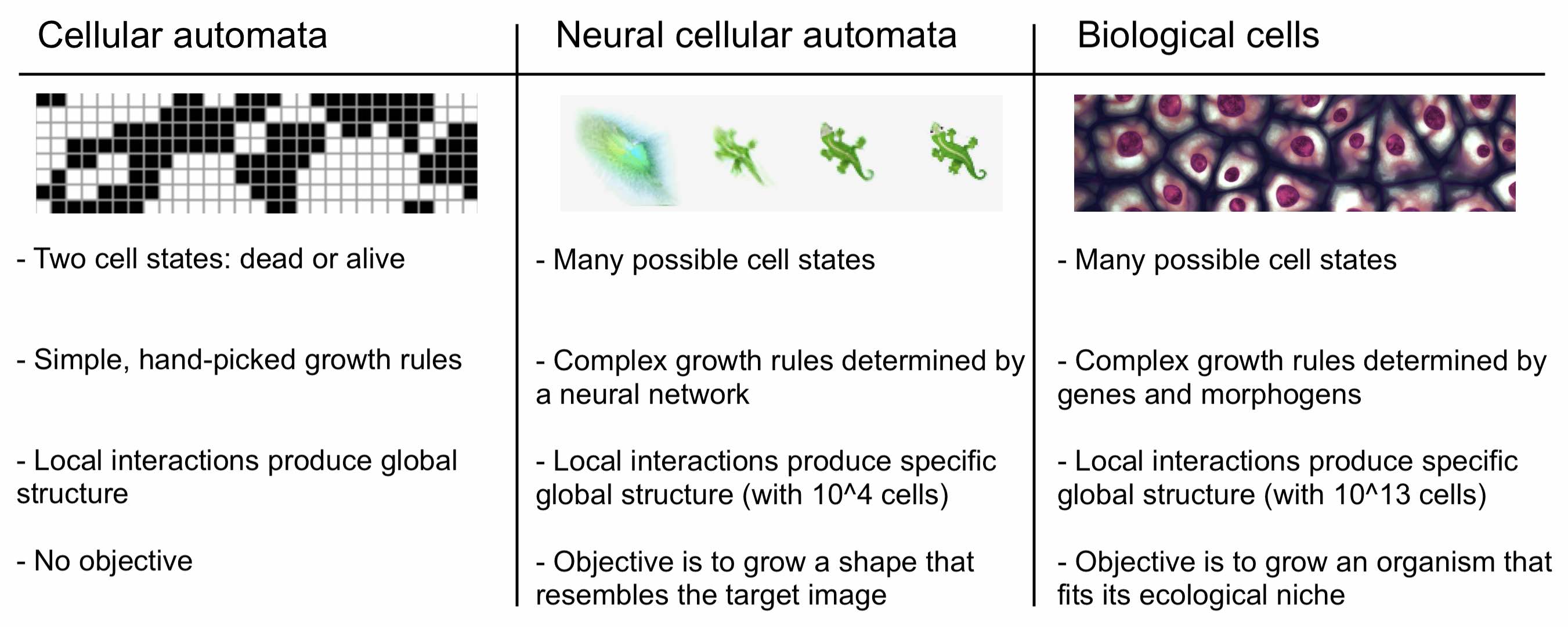
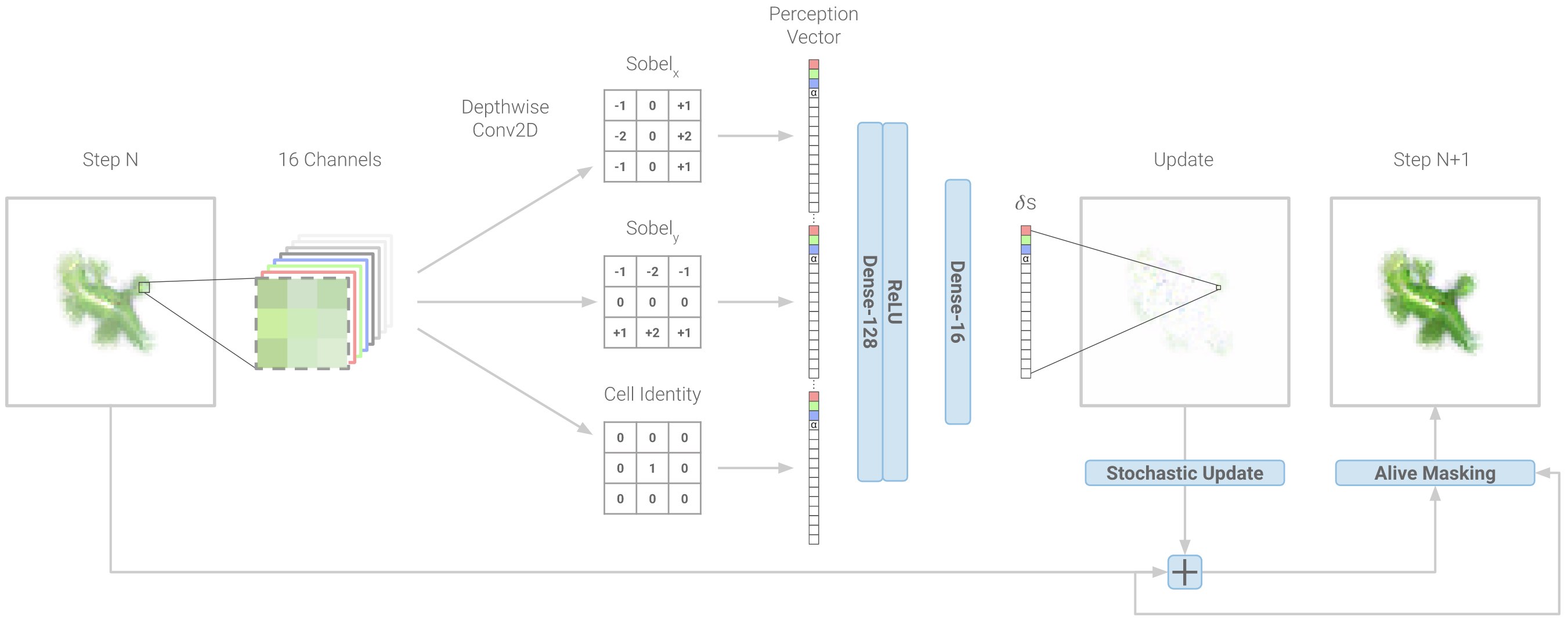








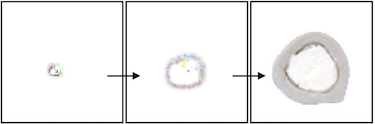



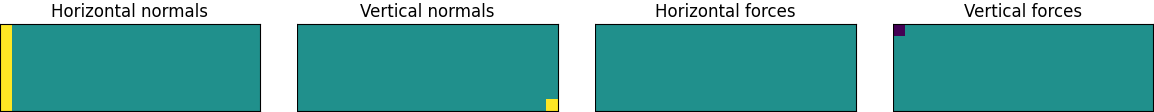
 Final MBB beam design:
Final MBB beam design:



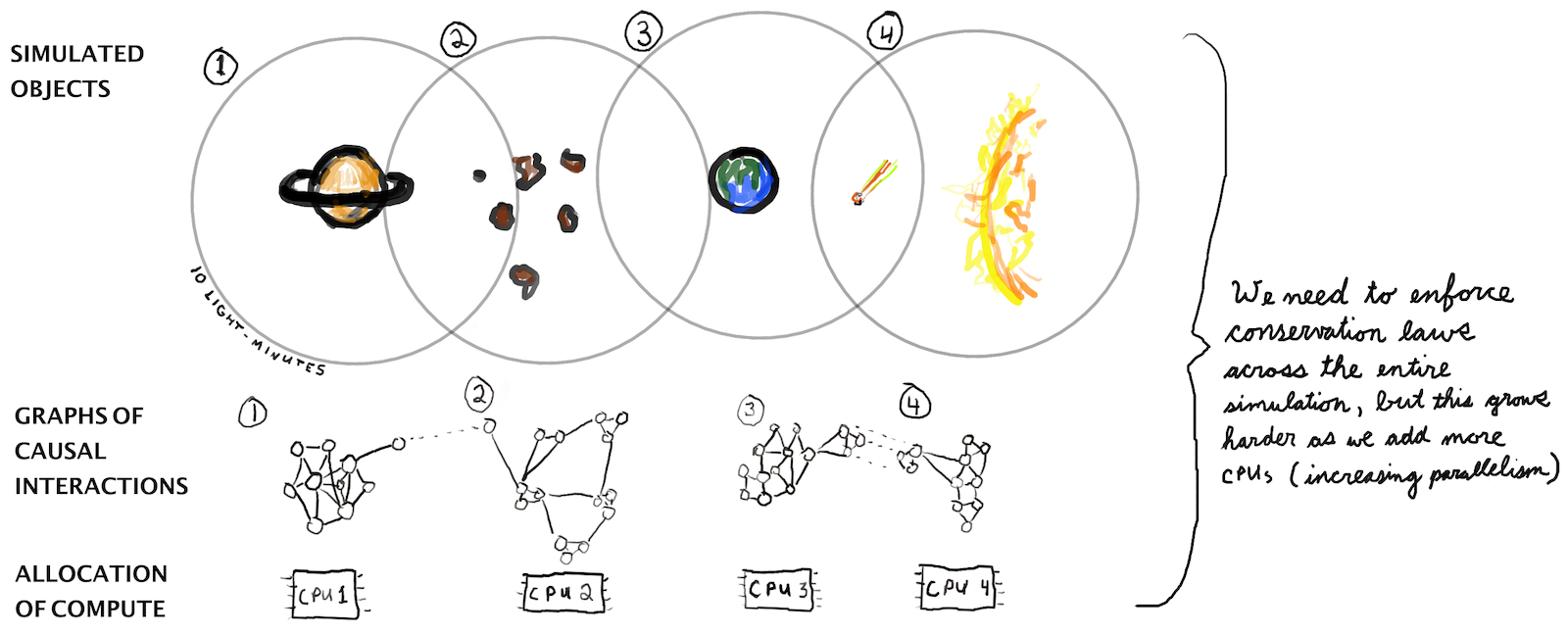
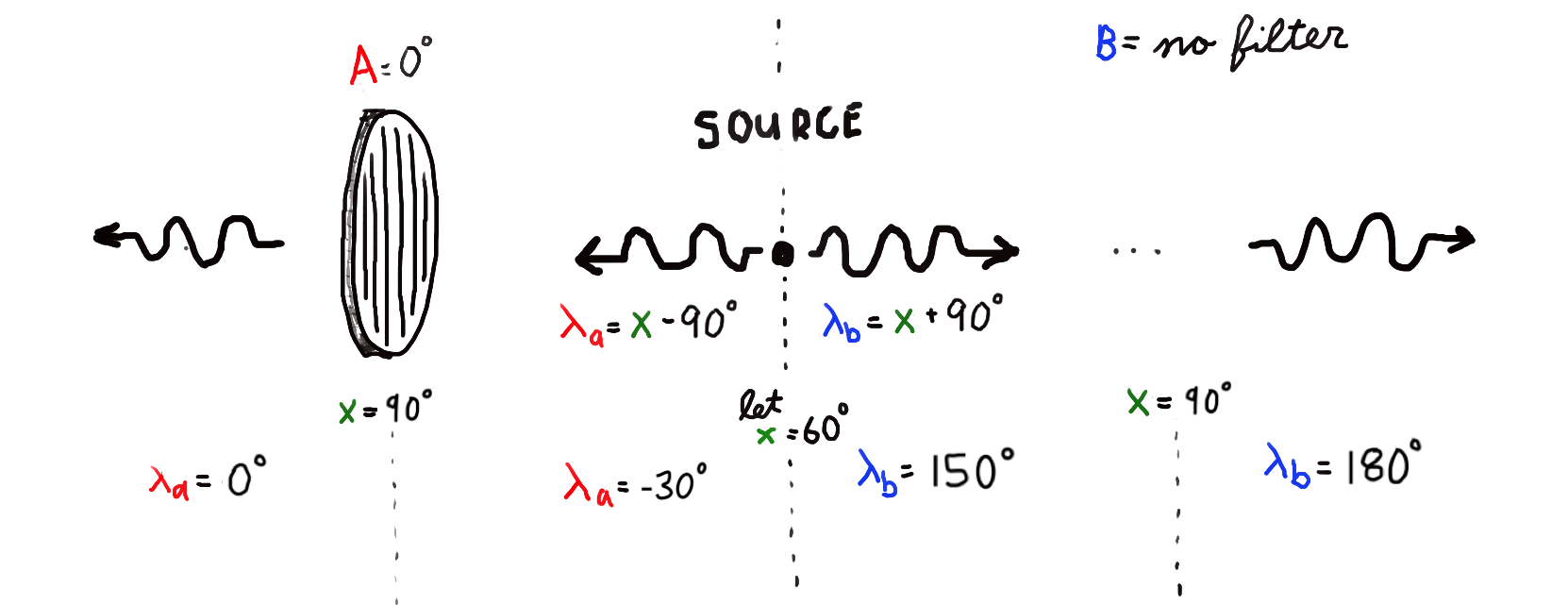
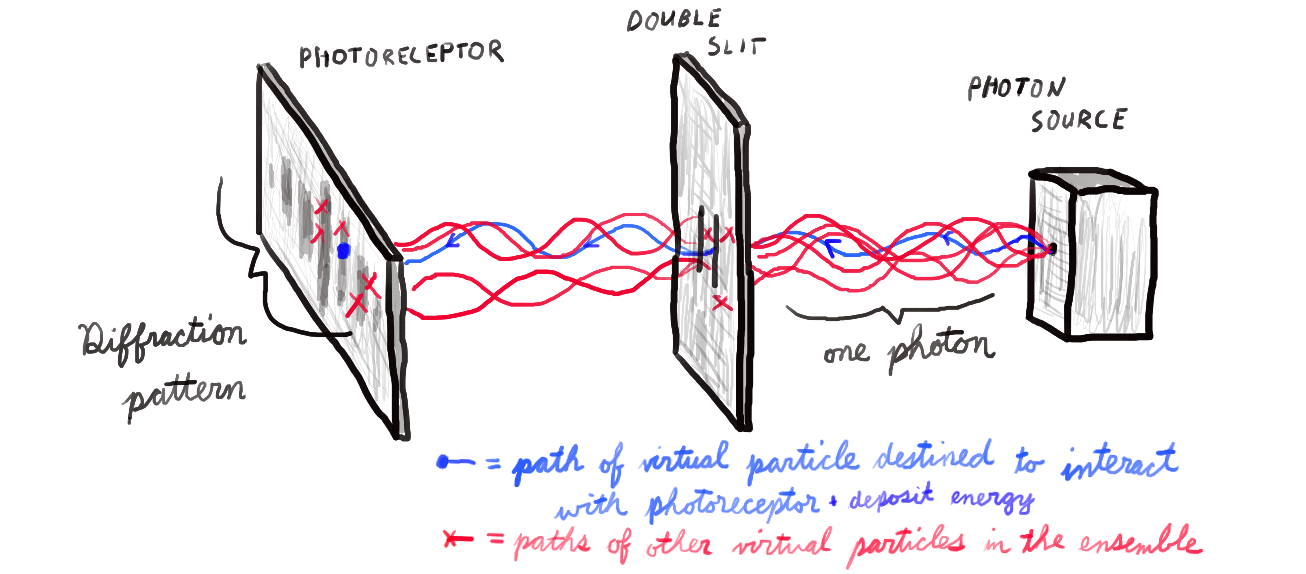
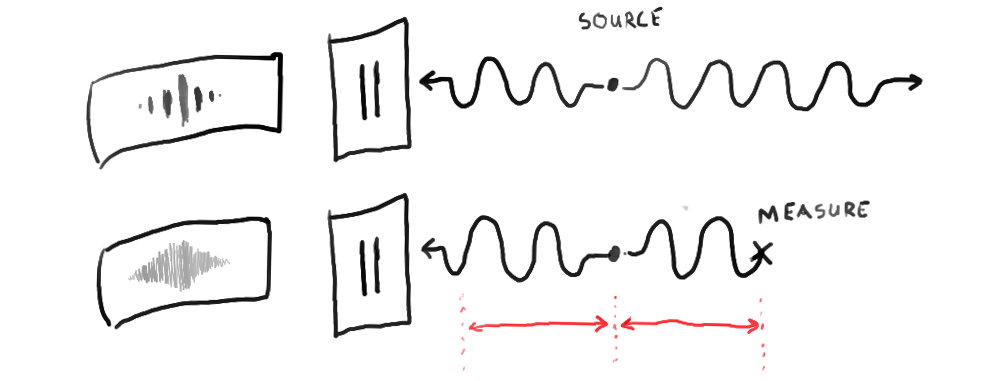
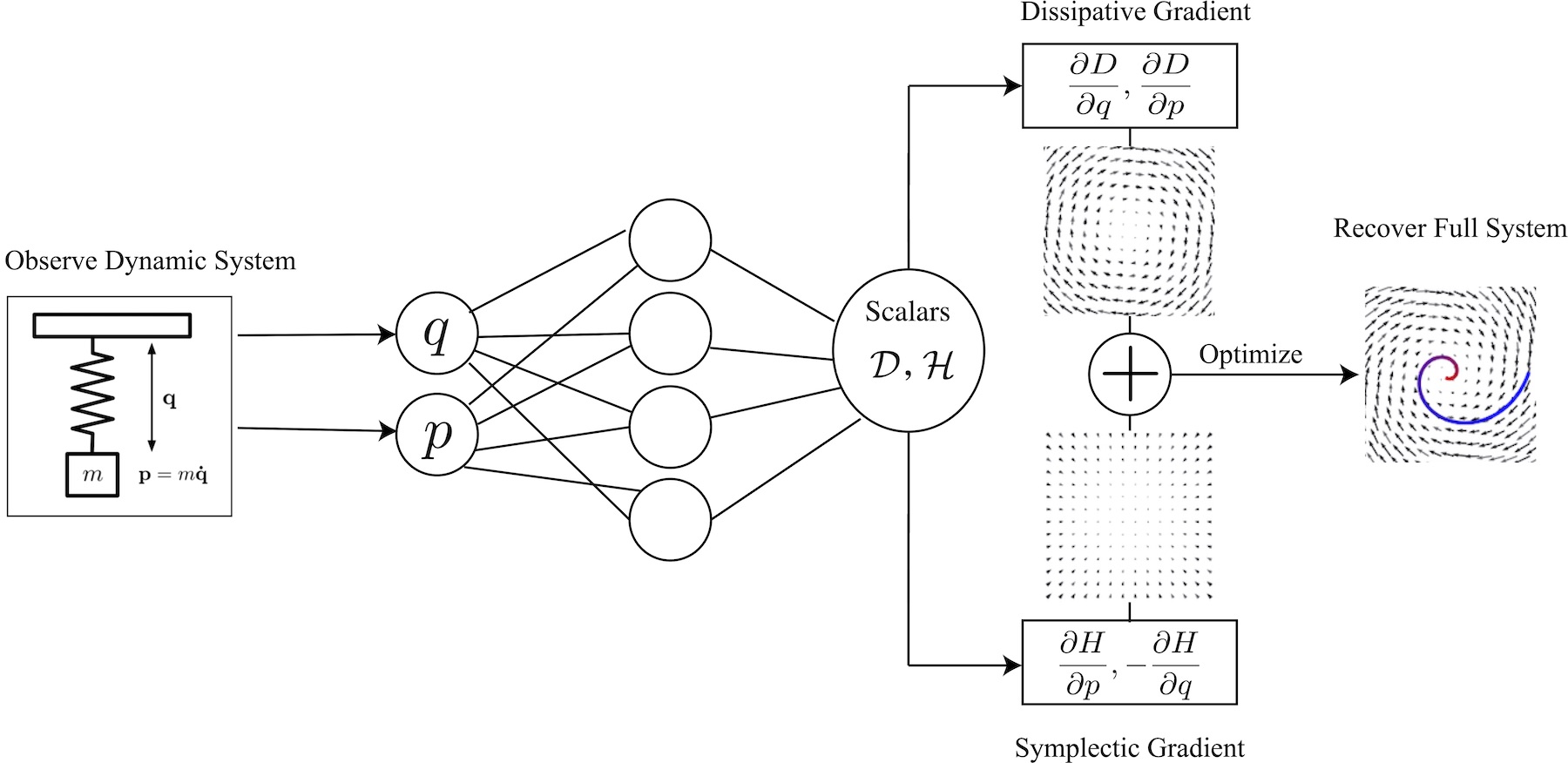

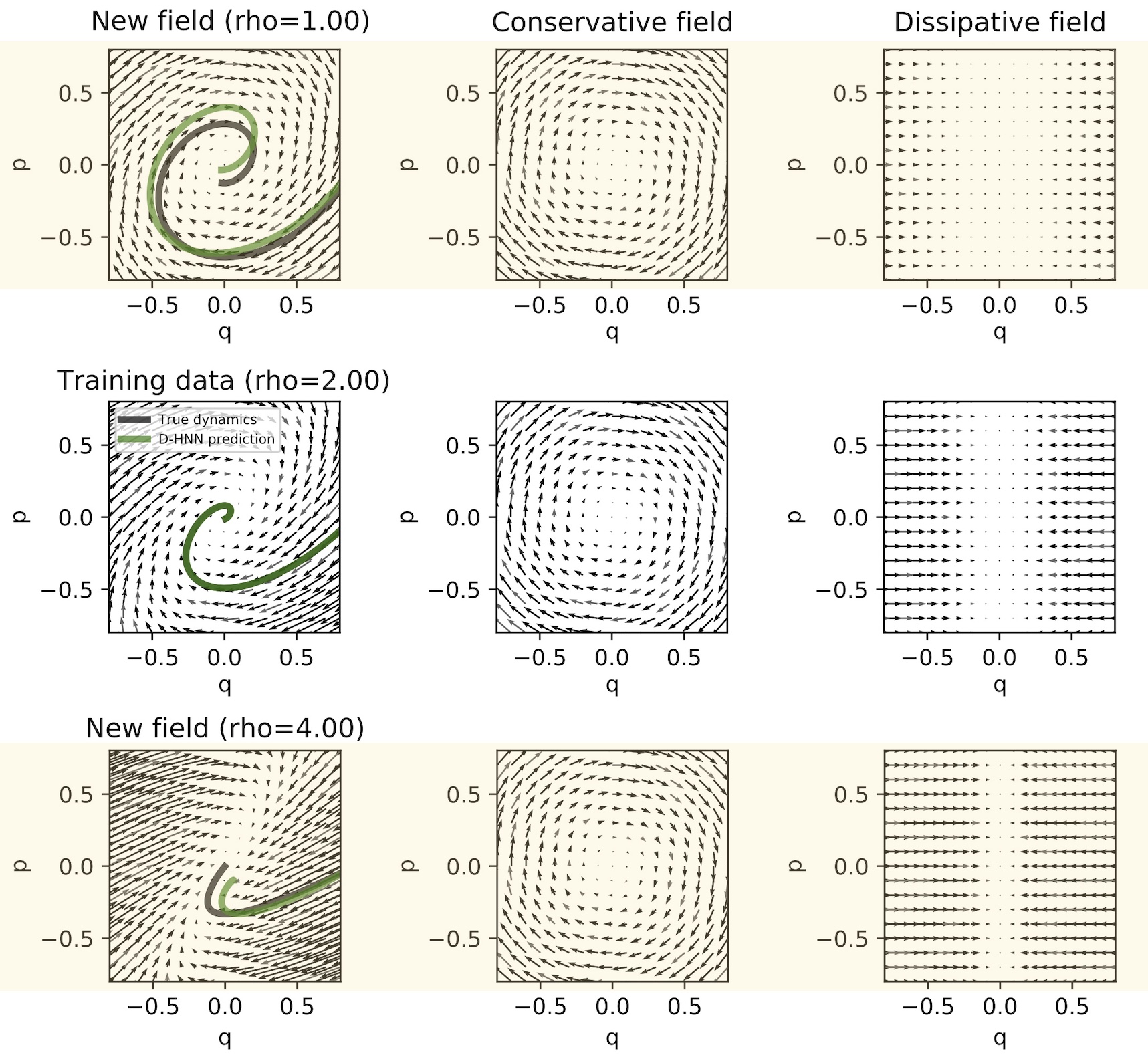
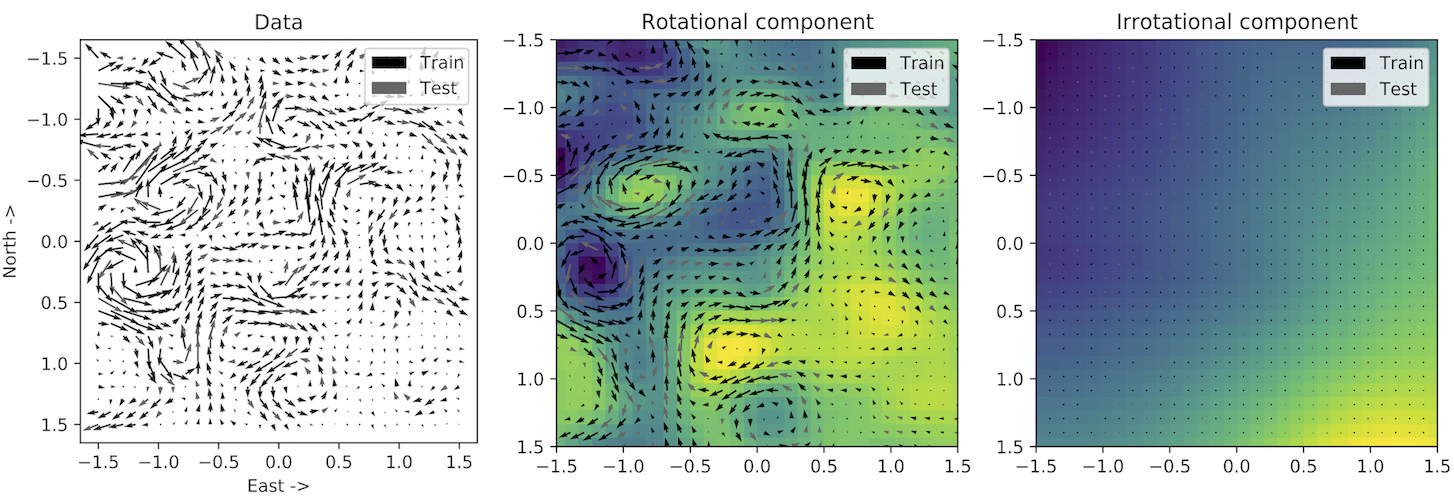
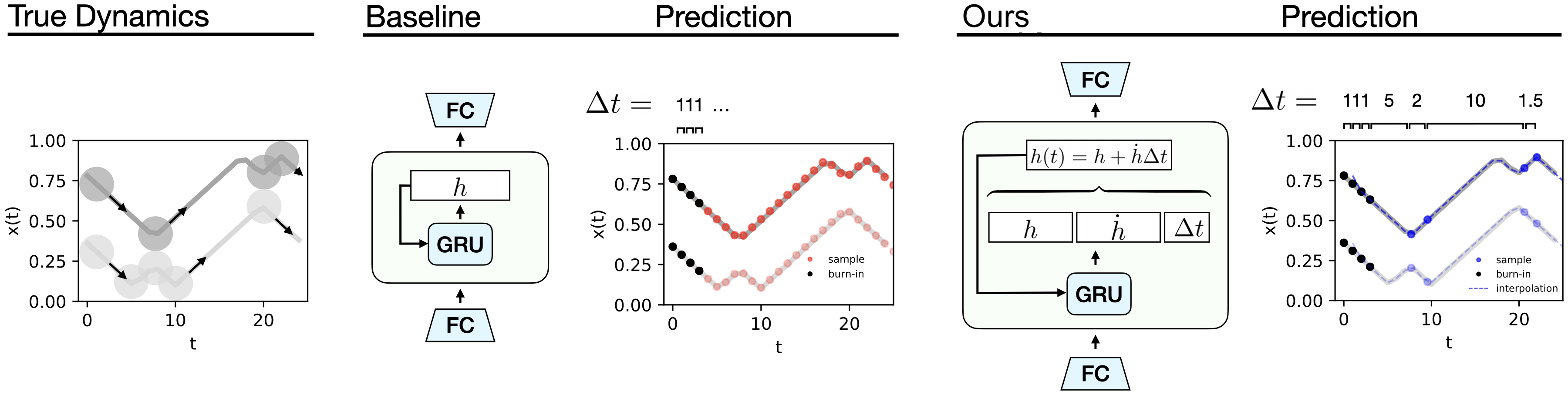
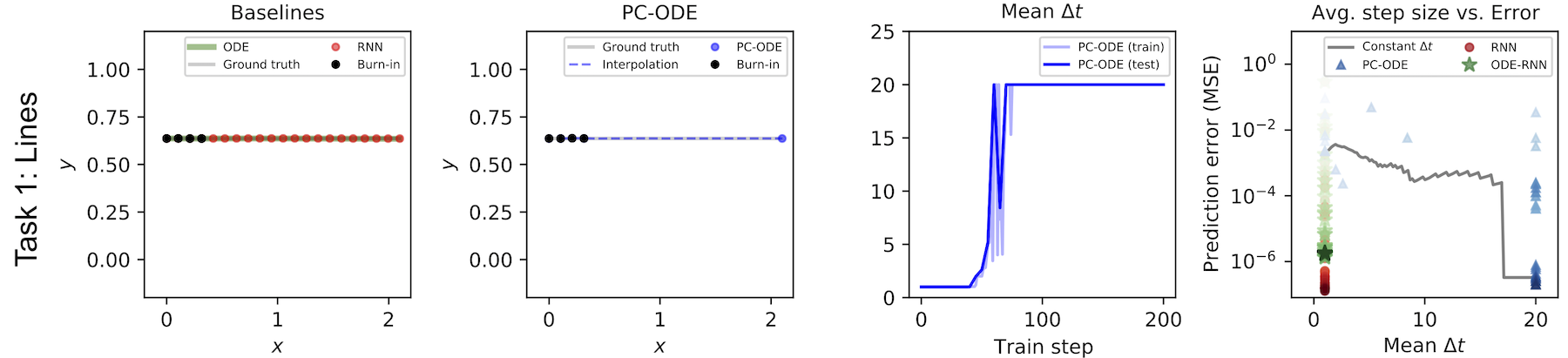
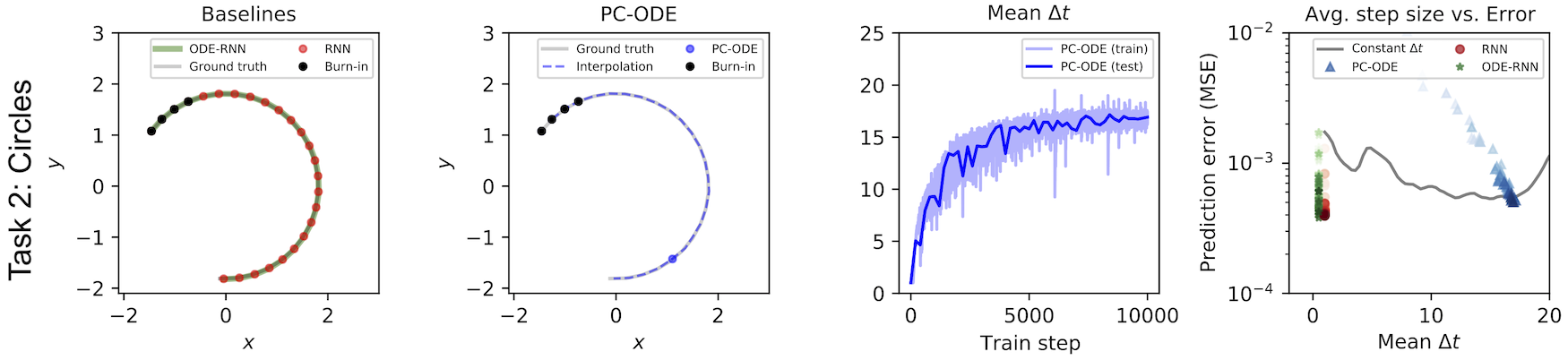
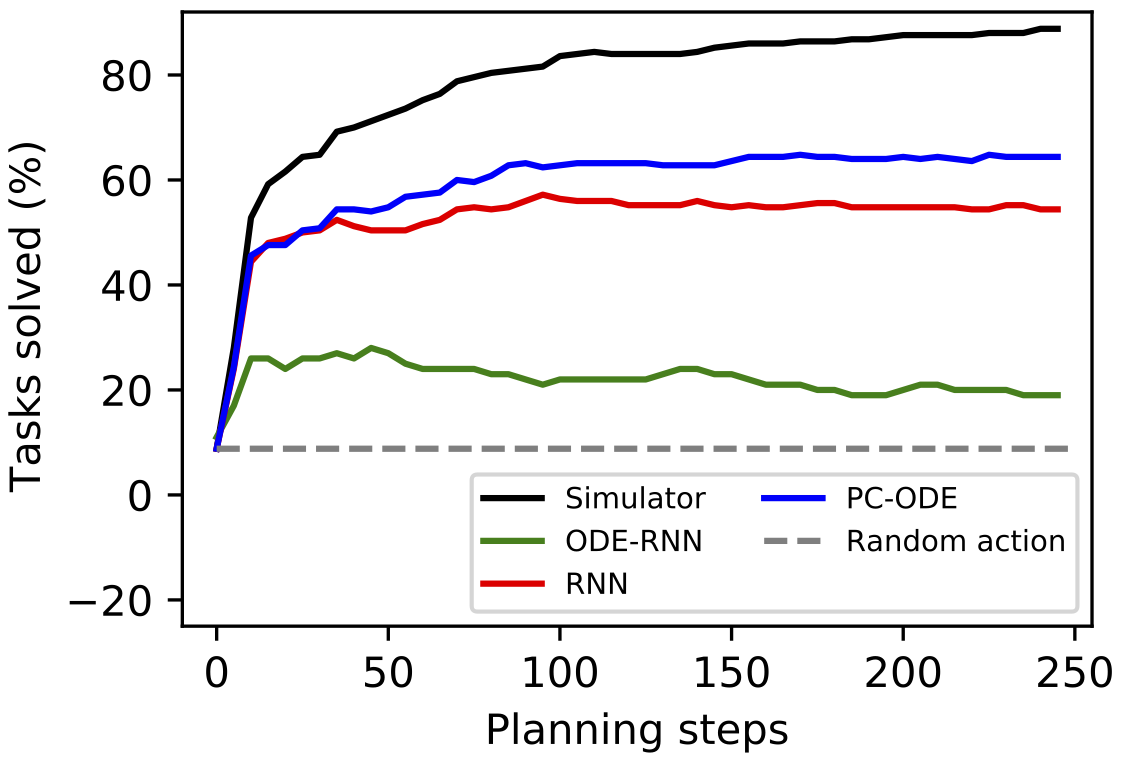
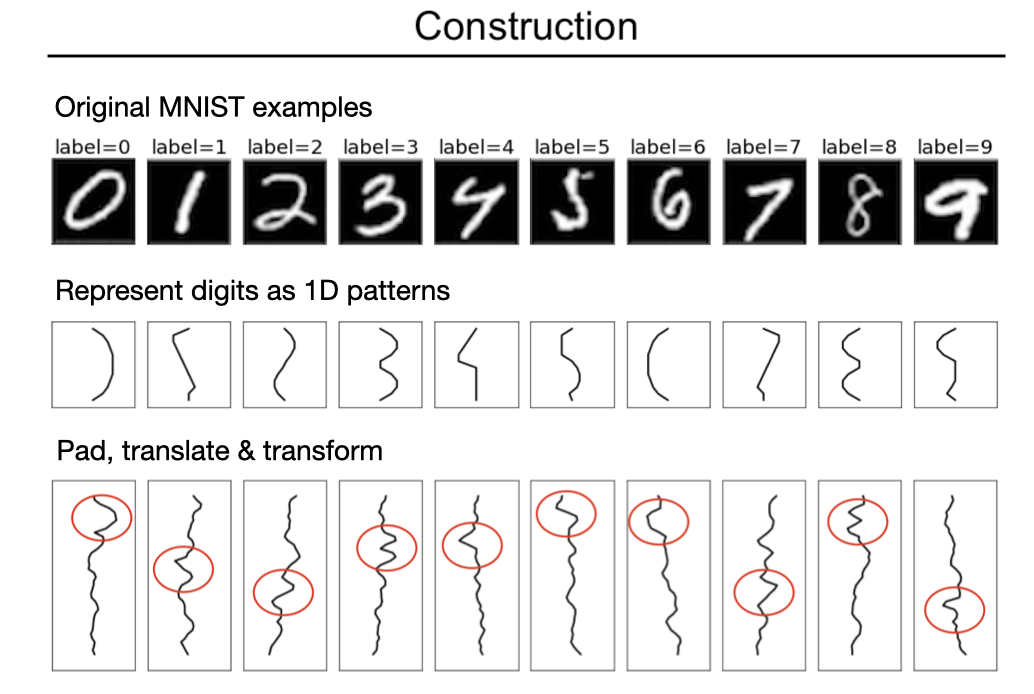
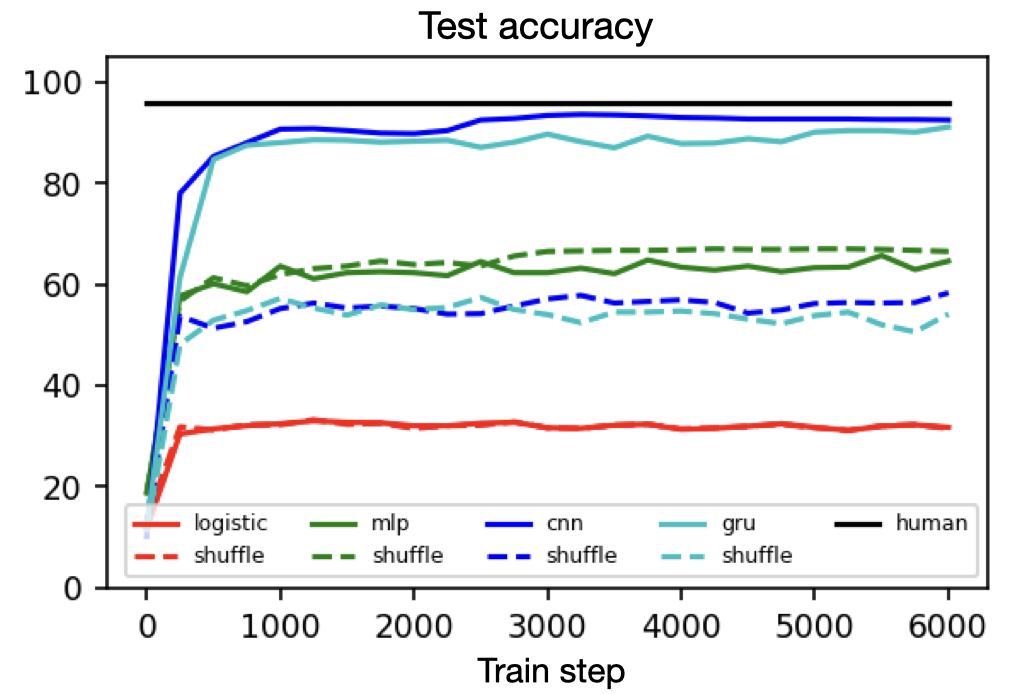
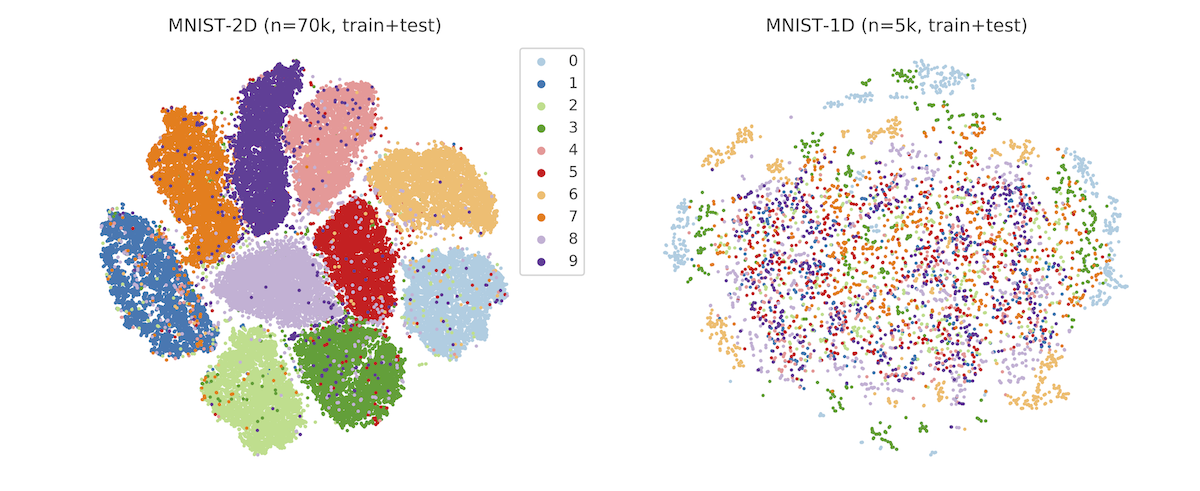
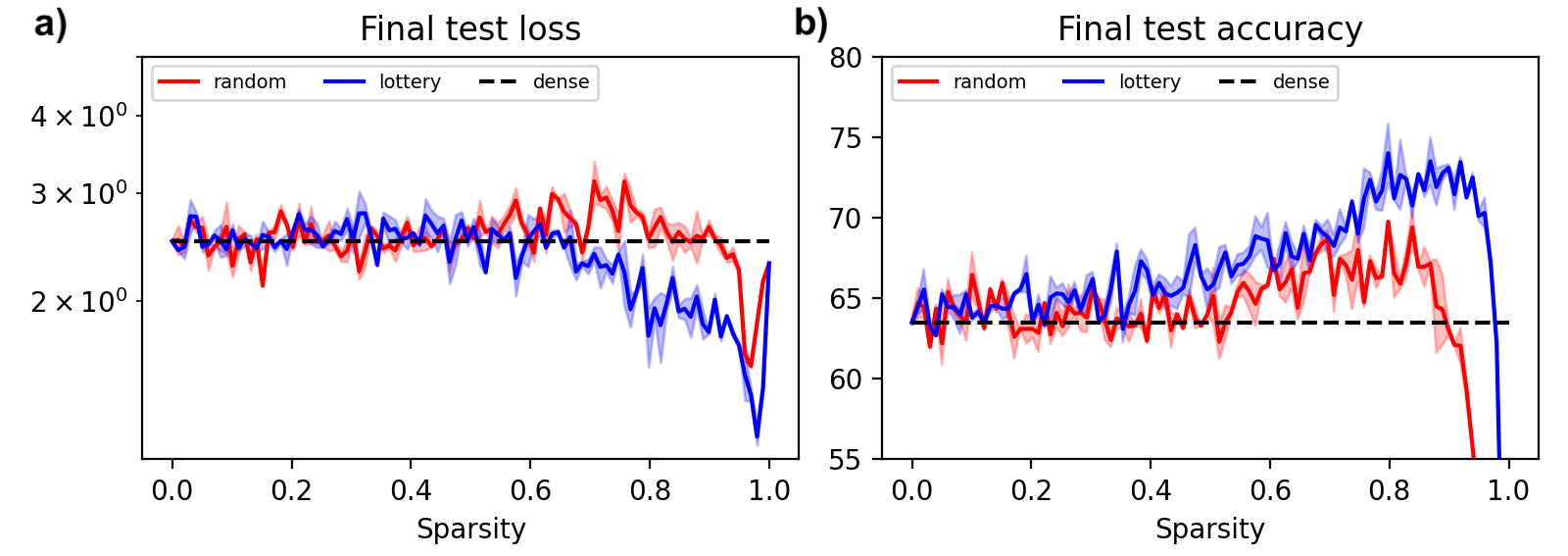
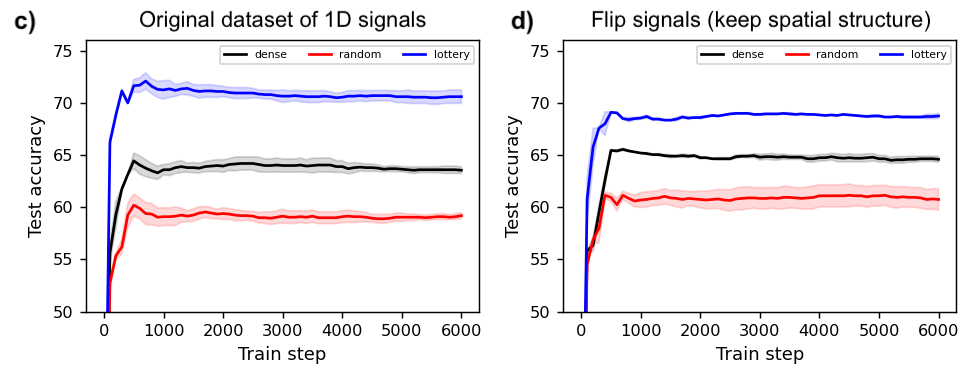
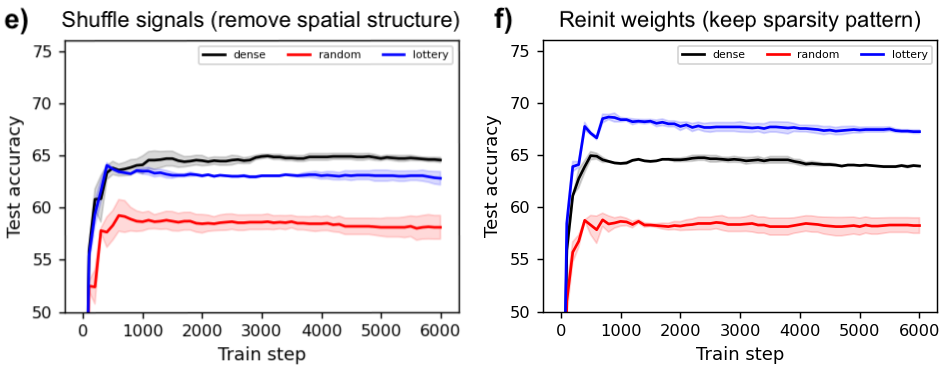
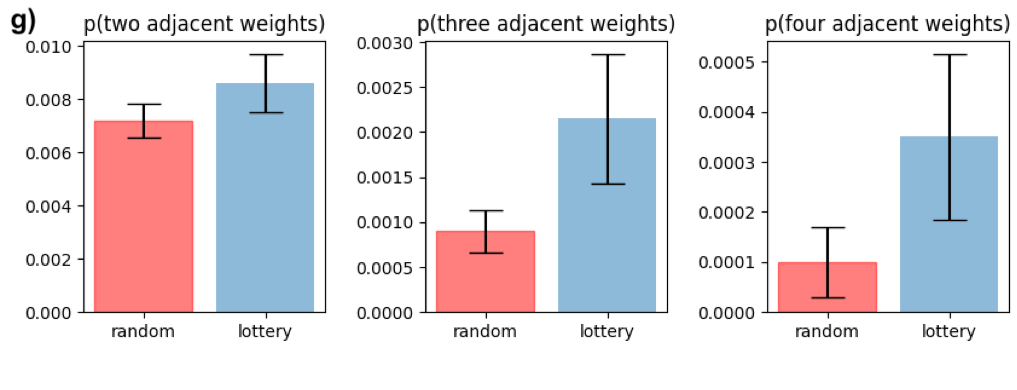
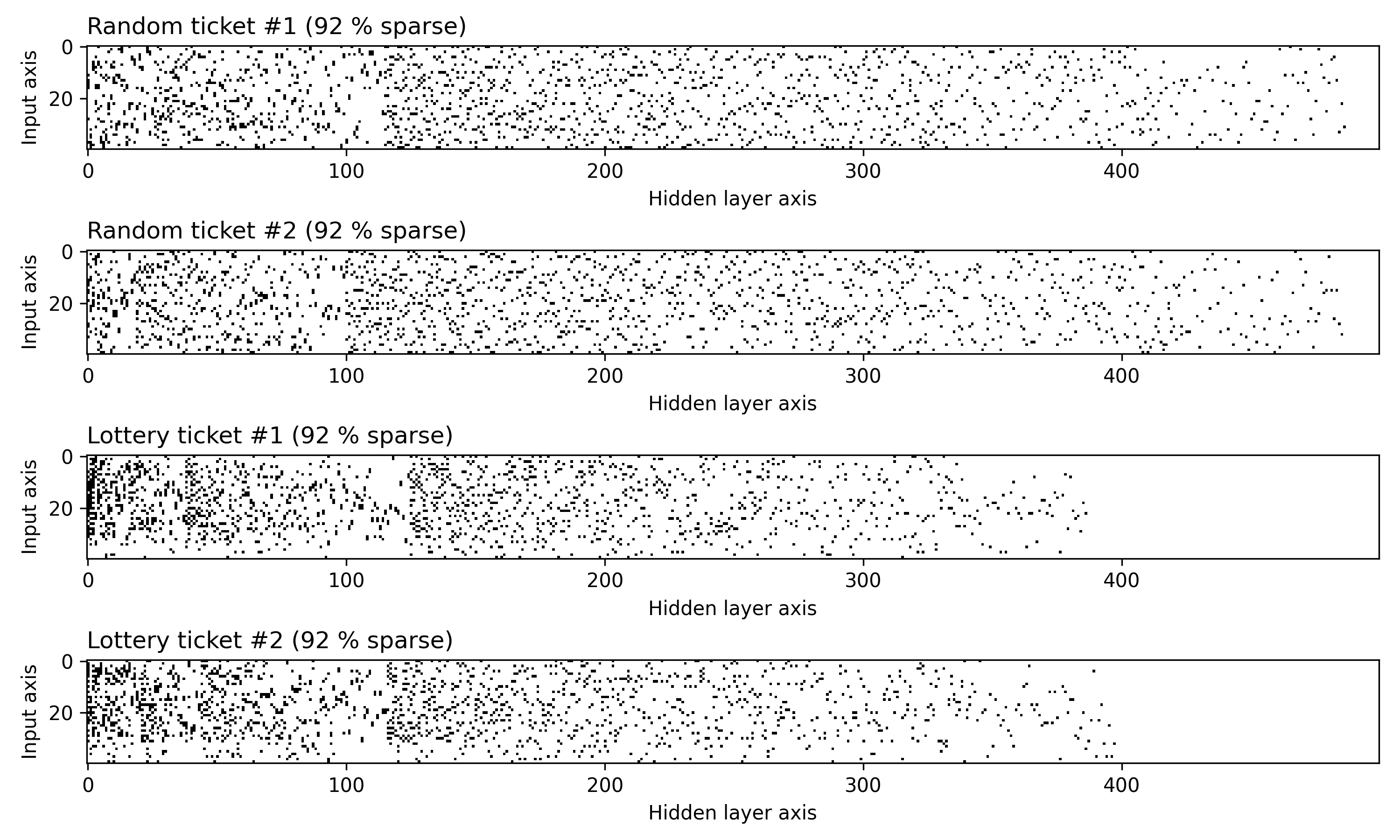
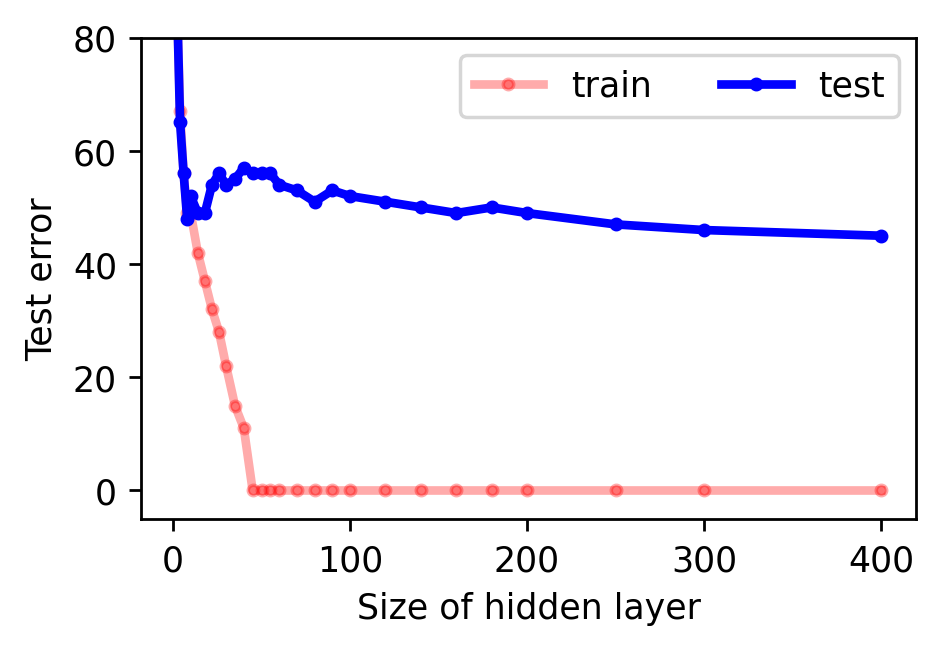
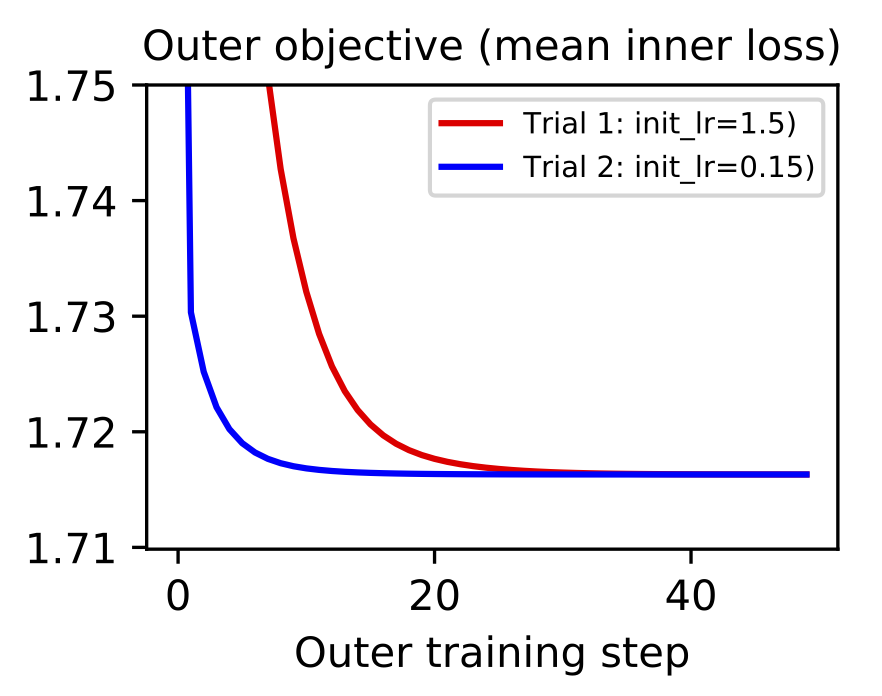
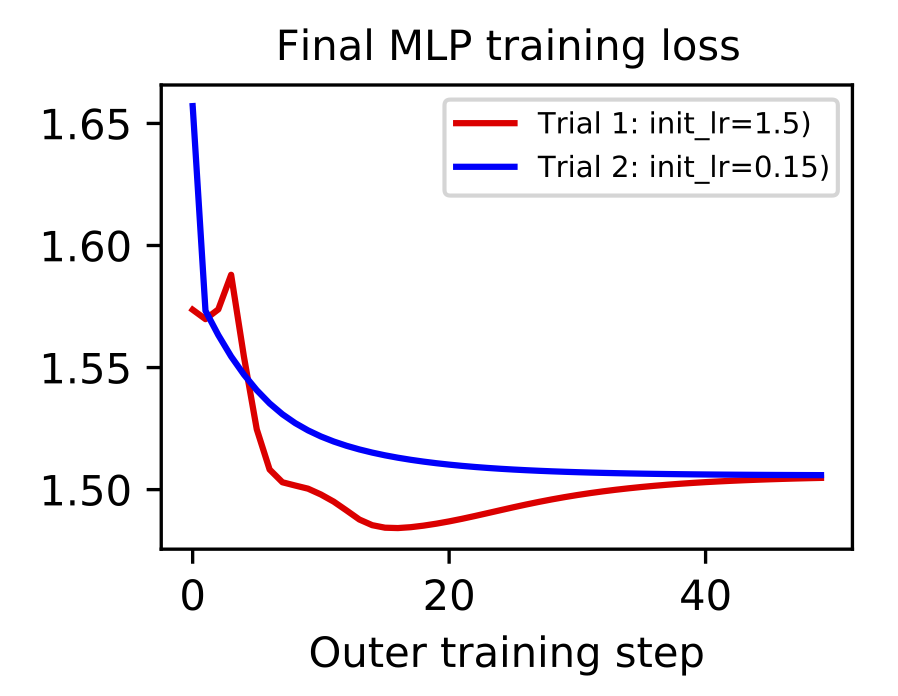
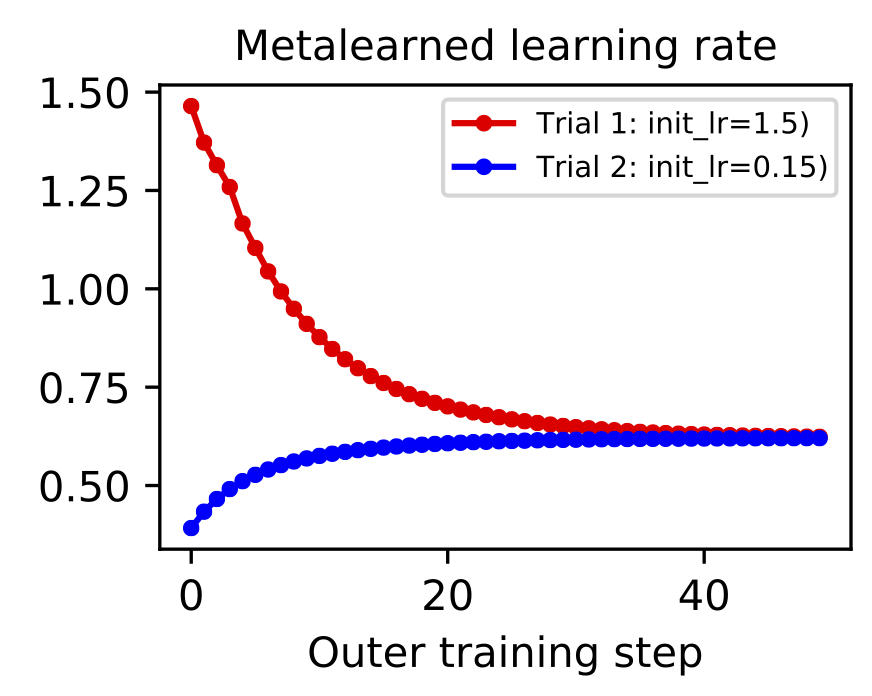
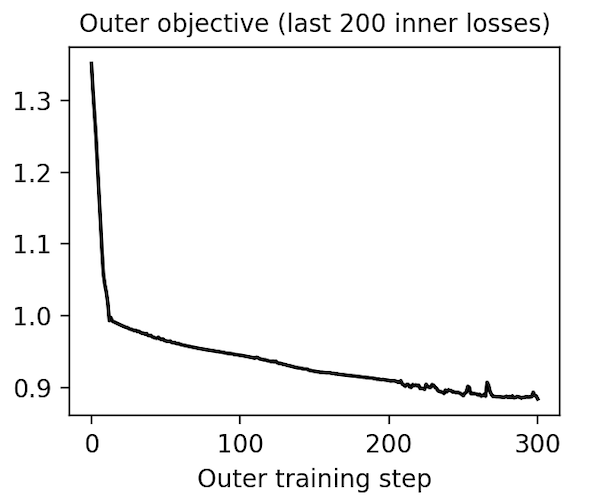
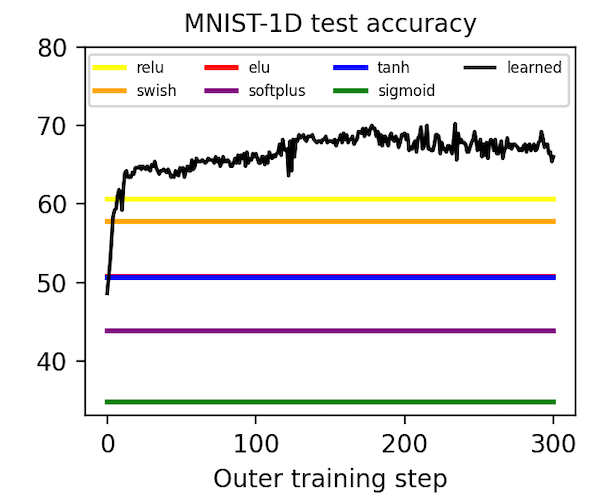
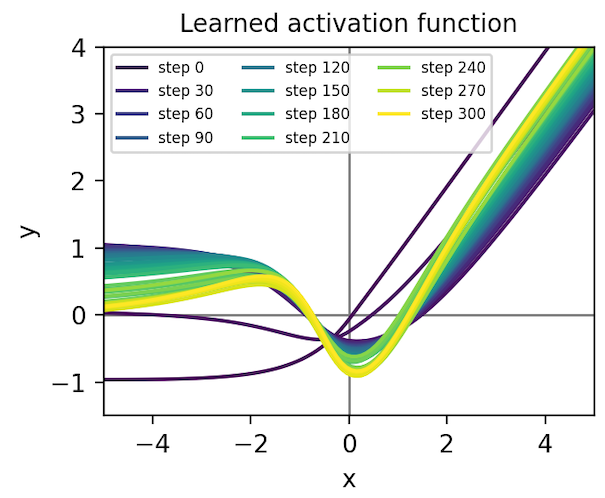
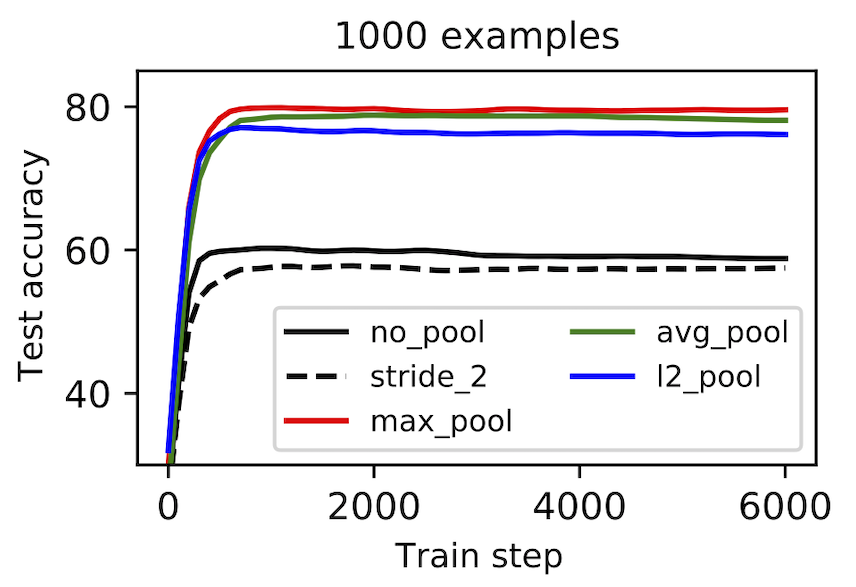
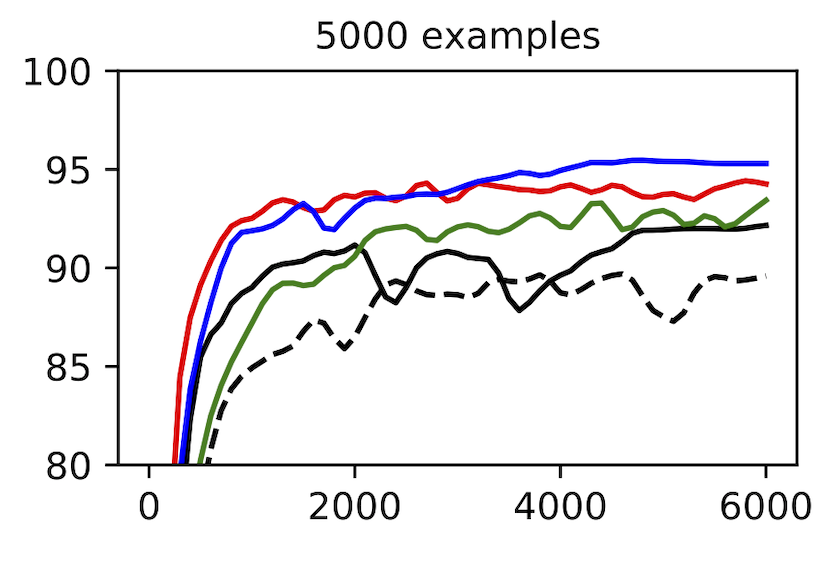
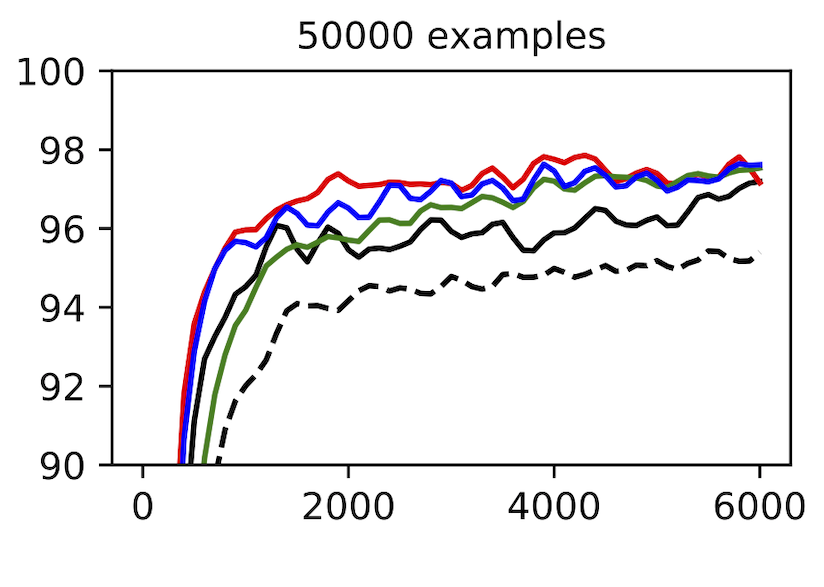


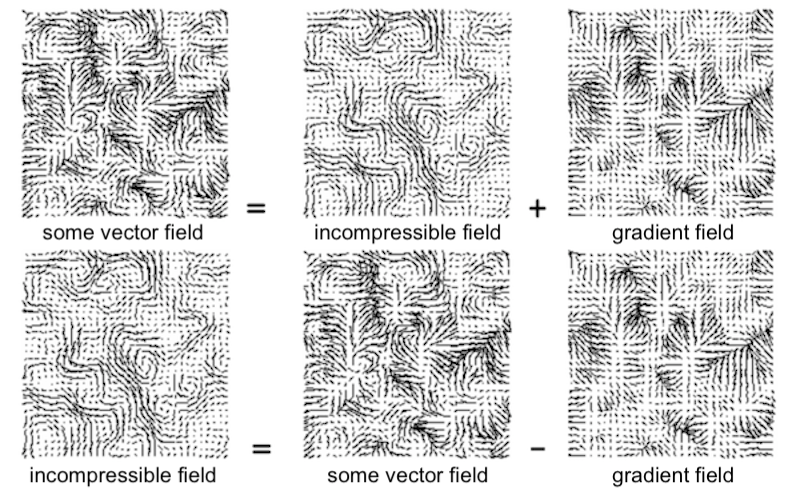







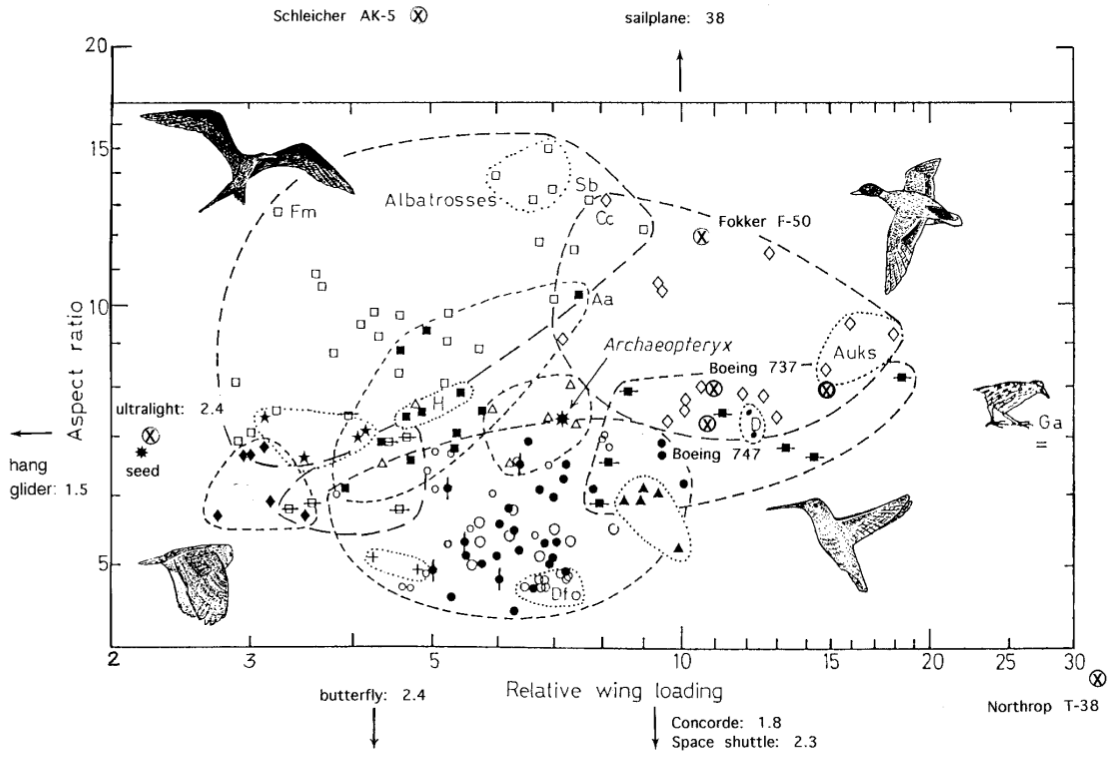
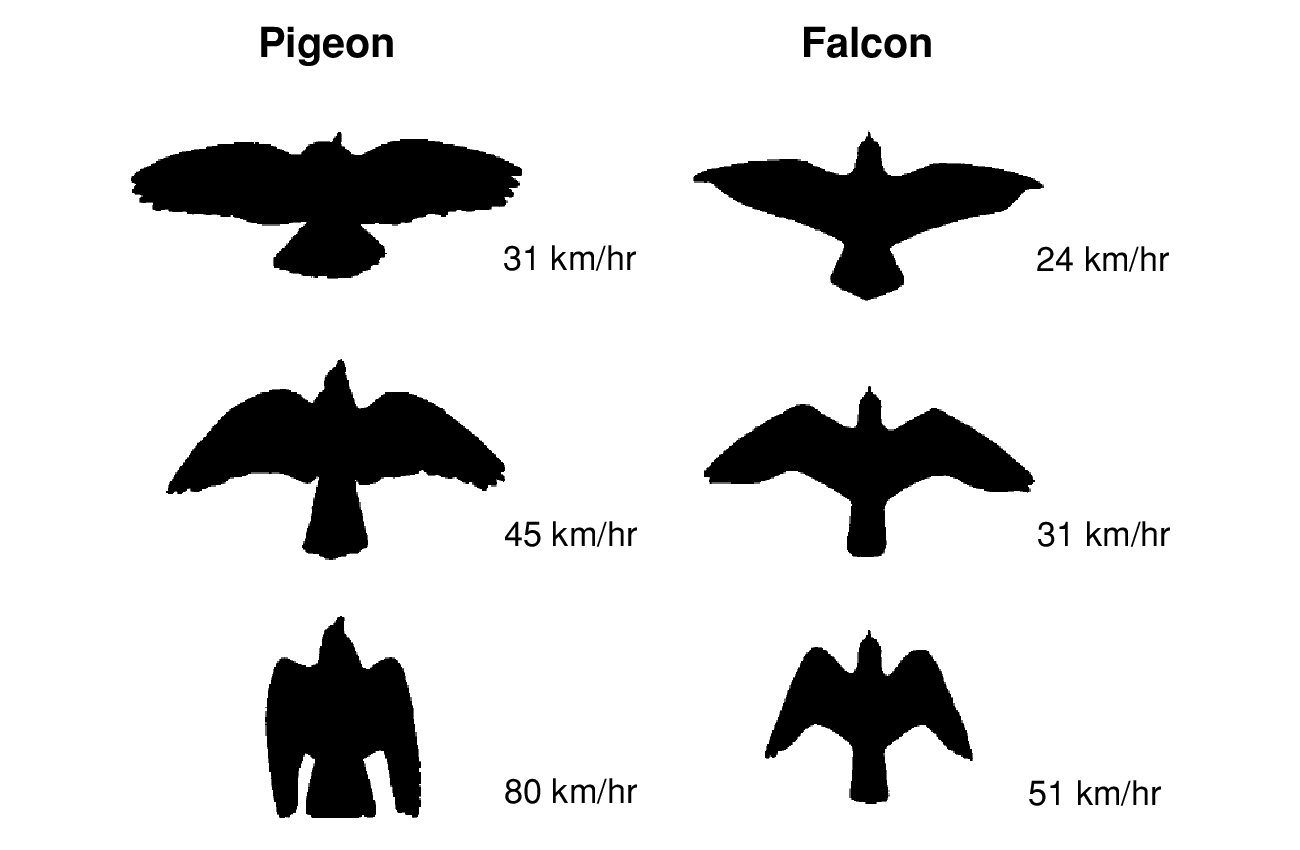
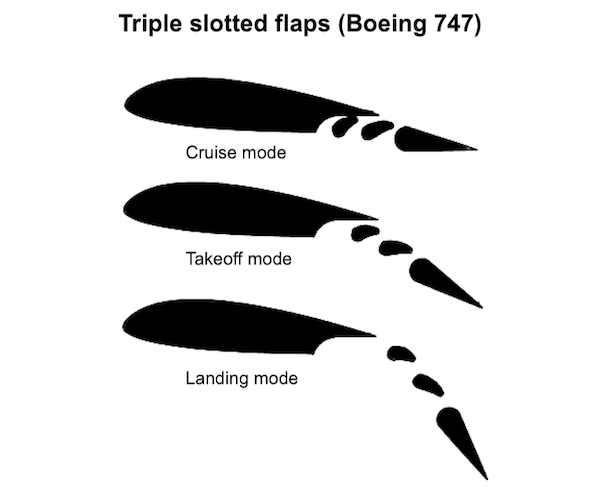

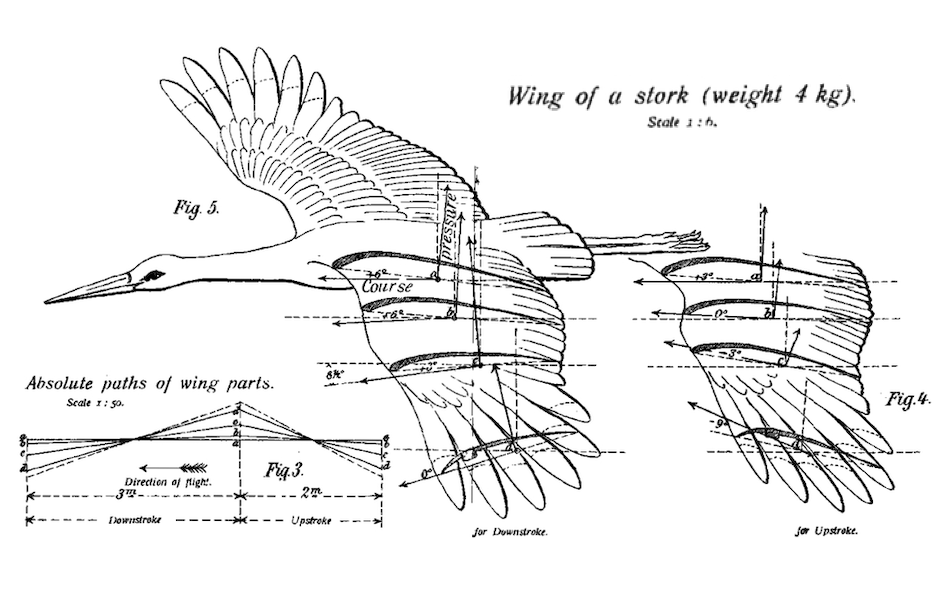
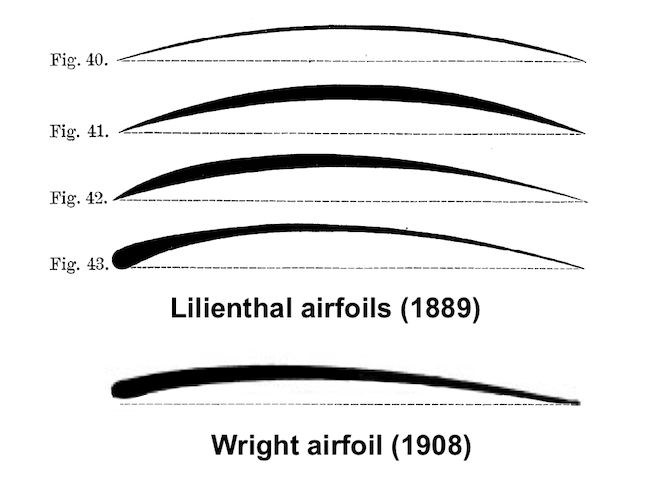




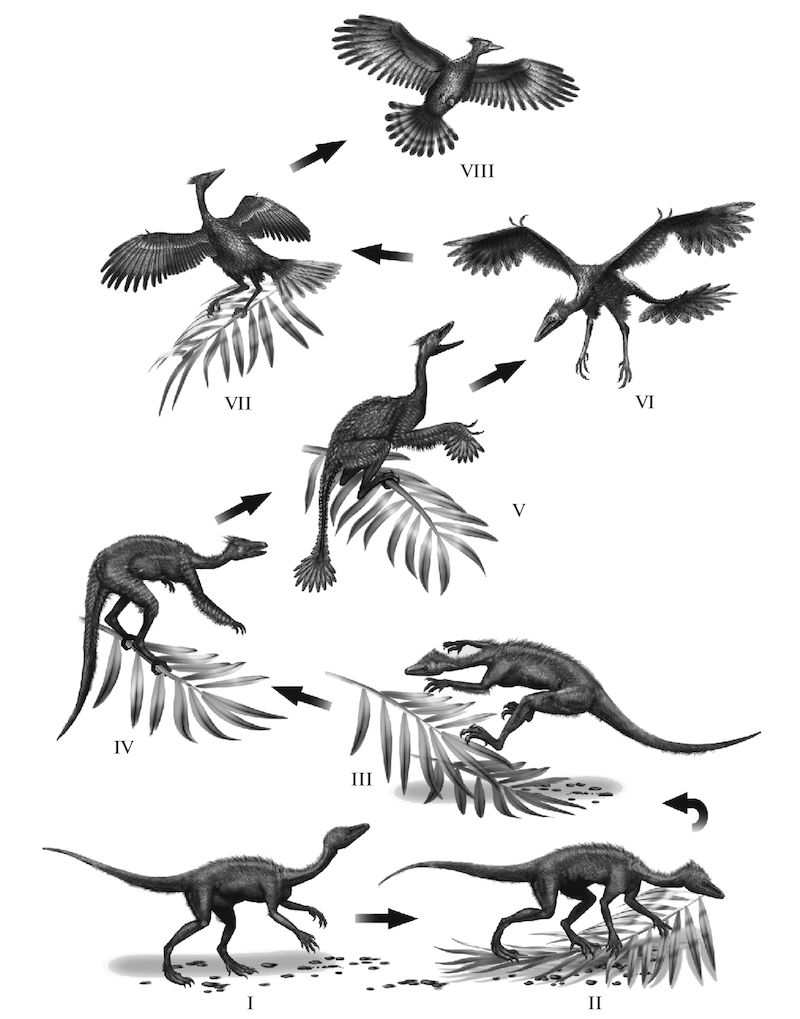


{kind=link}