
Visualizing and Understanding Atari Agents
Deep RL agents are effective at maximizing rewards but it’s often unclear what strategies they use to do so. I’ll talk about a paper1 I just finished, aimed at solving this problem.
Solving Atari in 180 lines
Deep RL. It’s hard not to get excited about deep reinforcement learning (deep RL). The field is exciting from an experimental standpoint because a major innovation or state-of-the-art result seems to emerge every few months. Most recently, Google DeepMind described AlphaGo Zero, a Go-playing algorithm which, over the course of 72 hours, rediscovered many of the strategies used by top human players…and then discarded them in favor of strategies unknown to humans. Deep RL is exciting from a theoretical standpoint because it combines the elegant simplicity of reinforcement learning with the raw power of deep neural networks.
Getting started is hard. Though deep RL is a ~glamorous~ field, it’s painfully difficult for newcomers to get started. Getting started with deep (supervised) learning is not easy, but training deep RL agents is far more difficult (see rant). In my experience, adjusting a single hyperparameter (e.g. learning rate, discount factor, etc.) or changing the code in a way that feels pretty innocent often results in catastrophic failure. At the same time, this is what helps one learn deep RL: fiddling with settings and then watching your model crash and burn…again and again and again (sort of meta, when you think about it).
I got sick of Cartpole quickly. It’s not a rich environment, and succeeding at Cartpole does NOT mean you’re succeeding at deep RL. The PyTorch tutorial is feeding you a lie! A better totem for the challenges – and the impressive results – of training deep RL agents is the Atari 2600 suite.
Baby-A3C. The problem with Atari agents is that most open-source implementations are clunky and opaque. I ran them, got good results, and understood nothing. There was only one thing left to do: write my own one-file, 180-line, high-performance A3C Atari agent. GitHub link.



At this point, I had obtained three really strong Atari agents using the exact same code/hyperparameters. It was pretty cool to watch them play Atari with superhuman skill…but what exactly had they learned? What were they thinking? As a visiting researcher at DARPA’s Explainable AI Project at Oregon State, it was my job to come up with some answers.
Why should I trust you?
Deep learning can make good guesses about whether or not you have cancer or whether or not there is a stop sign ahead, but it can’t explain these guesses. Clearly, this is a problem.
For better or worse, AI (I’m using AI and machine learning interchangeably here, which is common but not technically correct) is going to play a larger and larger role in our lives. Deep learning can already do quite a bit: diagnose cancer, drive cars, discover drugs, translate languages, and detect fake news. While deep RL is still in the research phase, many believe that it will have an equally dramatic impact.
The black box problem. Unfortunately, these models are extremely difficult to interpret. The way things are right now, they can make good guesses about whether or not you have cancer or whether or not there is a stop sign ahead, but they can’t explain these guesses. Clearly, this is a problem.

Past work. Many papers aim to fix this. Some focus on feedforward models, which are used for computer vision. Others focus on recurrent models, often preferred for translation. My research group was surprised to find, though, that very little has been done in the way of understanding deep RL models. To our knowledge, there’s just one strong paper on the topic. This paper does a good job of explaining deep RL policies to experts: think t-SNE plots, Jacobian saliency plots, and a way of extracting a Markov Decision Process (MDP) from a Deep Q-Network (DQN). Sadly, there’s not much a non-expert could glean from these results.
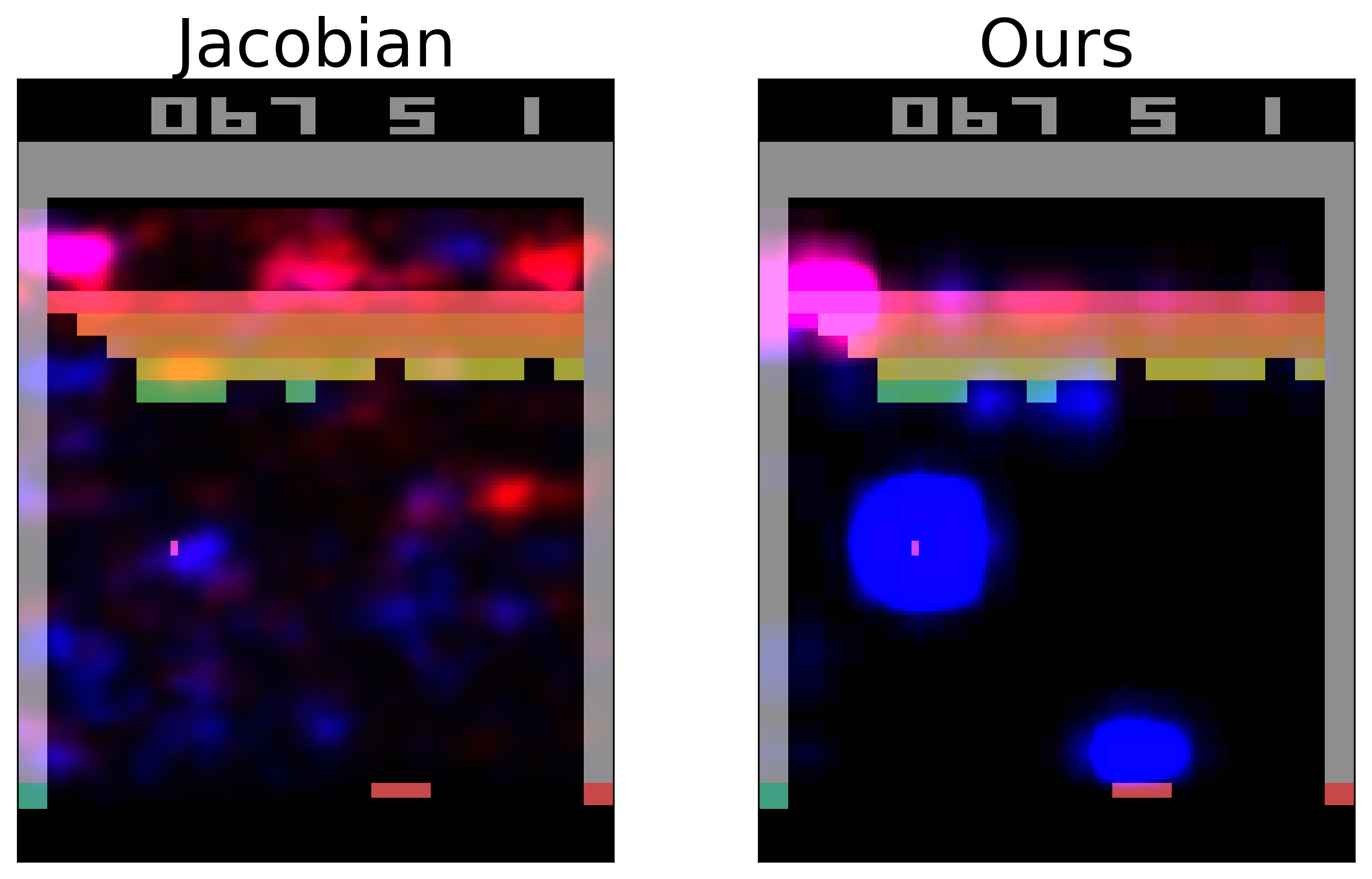
Our approach (link to paper). We decided to explain deep RL agents in way that was informative to experts and non-experts alike. The question we asked was “What is the agent looking at in order to make its decisions?” and the answer we came up with was a technique for generating “saliency maps” that show where the agent is “looks” in order to make decisions. Let me be clear: before our paper, there were methods for generating saliency maps like this…but ours is a lot better :).


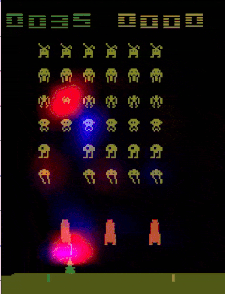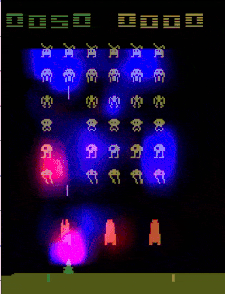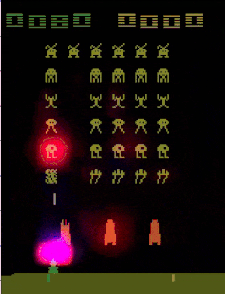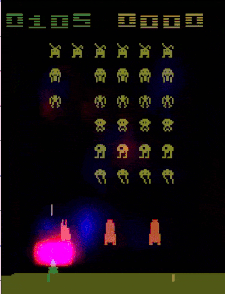
Before looking at saliency videos for our agents, we made guesses about that they were doing. After watching the videos (above), we found that all three agents were doing things differently from we had imagined (see paper). GitHub link.
Catching cheaters
Hint pixels. The next step was to determine whether our method could spot agents that were making the right decisions for the wrong reasons. We modified each Atari environment by inserting green “hint pixels” at the top of the game space. We used the hint pixels to send information about what an “expert” (pretrained Atari agent) would do, given the current state of the game. Then, we trained “overfit” agents to predict the actions of the “expert.” We also trained “control” agents in the same manner, but with the hint pixels set to random values.
Overfit vs. control. The overfit agents learned to use the hint pixels to mimic the expert. Think of this strategy as “cheating”: doing the right things for the wrong reasons. Meanwhile, the control agents learned to use relevant features of the gamespace (ball, paddle, etc.) to reconstruct the expert’s policy from scratch. In spite of these very different underlying strategies, the two agents looked almost identical in replays.
Survey. We made videos of both agents, with and without saliency maps. Next, we instructed 30 engineering students to watch these videos and answer questions about the agents. Even though these students had limited – if any – experience with deep RL and Atari, the majority of them were able to identify the overfit agent with the help of our saliency technique.
Table 1: Which agent has a more robust strategy?
| Video type | Can’t tell | Agent 1 (overfit) | Agent 2 (control) |
|---|---|---|---|
| Without saliency | 16.1 | 48.4 | 35.5 |
| With saliency | 16.1 | 25.8 | 58.1 |
Watching agents learn
Deep RL agents are known to transition through a broad spectrum of strategies. Some of these strategies are eventually discarded in favor of better ones (recall the AlphaGo Zero example). We wanted to see if we could visualize this process in Atari agents. Below are some cool results: the leftmost frames represent how untrained agents see their environment whereas the rightmost frames represent how fully-trained agents see their environment. Each frame is separated by about 10 million frames of training.



Going forward
Recap. Our long-term purpose is not to explain Atari agents; it is to explain any deep RL agents. In this project, we introduced a tool we believe takes us one step closer to that goal. We used it to explore Atari agents in a variety of different ways, and learned a lot about them in the process.
Memory. One major limitation of our technique is that our agents use recurrent connections (in the form of an LSTM layer), so memory plays a key role in their policies. A simple example is an agent which has learned to reason about the velocity of a ball (e.g. in Pong); it needs information about previous frames in addition to information from the current frame to do this. We present preliminary results for “the saliency of memory over time” in our paper, but it’s not the main focus of this project.
More than one tool. I think the comment about memory suggests a fundamental truth about explanations for deep RL: we need more than one. To produce explanations that satisfy human users, researchers will need to assemble many complimentary explanation techniques. To this end, I see this project as something which compliments previous efforts while motivating future efforts, taking the field one step closer to producing truly satisfying explanations.
-
Selected for an oral presentation at the NIPS 2017 Interpretability Workshop! ↩