
Interesting papers
A fairly random set of papers that I found interesting. Updated weekly. Filter by subject, click for details
DeepMind researchers used a bag of really clever tricks to drastically improve the memory and computational efficiency of a Neural Turing Machine. Sparse Access Memory (SAM), as they call it, is 1000x faster and uses 3000x less physical memory than non-sparse model. As a cherry on top, they provide a convincing argument for why an optimal content-based addresing scheme of memory management cannot be much more efficient than this model. The sparse reads and writes are chosen by a tree data structure sorted according to nearest-neighbors. For a million memory vectors, the SAM only reads/writes to ~8 locations at a time (huge improvement).
This is a very personal reaction...BUT I FREAKING LOVE THIS PAPER!!! It's not particularly creative or shocking. Indeed, the most exciting and original work was presented in the original Neural Turing Machine paper and the recent Differentiable Neural Computer (DNC) paper. What I love about this paper is that with just a few simple but clever adjustments to those algorithms it achieves dramatically better results. Plus the acronym spells my name...
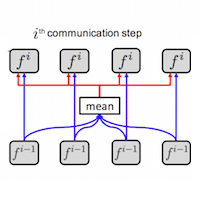
The authors introduce a formalism for multi-agent communication with a single communication channel and use it to solve several proof-of-concept tasks. You can understand almost all of the paper by looking at the diagram at the top of page 3. There are three proof-of-concept tasks 1) decentralized traffic control 2) predation 3) cooperative bAbI. There is a fourth sanity-check task but it's not especially interesting. Tasks 1) and 2) appear to have been invented by the authors but provide reasonable metrics.
The true strength of the paper lies in the formalism it introduces for multi-agent RL communication tasks: it's both scalable and modular. The ideas in this paper compliment DeepMind's recent communication paper but I wish that the authors had made more of an effort to build on DeepMind's work. Sometimes it seems as though they are reinventing the wheel...even if the end result is a very elegant wheel.
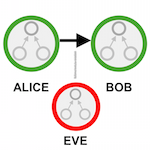
It looks like the researchers trained two neural networks (Alice and Bob) to establish a communication protocol with one another, then penalized the cost function whenever a third network (Eve) was able to decipher messages in that communication. As an extra flourish, they showed that it's possible for the Alice and Bob networks to selectively encrypt information - in other words, learn to keep only some of the information in their messages private.
This is an awesome proof-of-concept paper. Though not strictly theoretical, the paper shows that neural networks can "learn to use secret keys to protect information from other neural networks." This is a very interesting property in its own right. While these results are not immediately applicable, they could become important several years down the road (when neural networks are more ubiquitous).
Abbreviated HM-RNN, this architecture is a cleverly modified stack of LSTMs. Previous papers (going back to the early 90's) have dreamed of using multiple stacked recurrent neural networks to process data at different timescales. This looks to be the most successful attempt so far. The key to this paper's success is 1) allowing the RNNs to choose whether they want to COPY, UPDATE, or FLUSH their memory state and 2) having Yoshua Bengio as an author :). In all seriousness, point 1) is a very effective innovation. Look at Figure 4 on page 9 if nothing else!
Yes, this is state of the art in recurrent architectures and the authors got some cool results. That said, it doesn't really inspire me. There's nothing particularly exciting but a lot of programming heavy-lifting clearly went into making all this work. The ability to learn patterns at different timescales is key to improving RNNs but I think there must be a way to do it in a less artificial, hand-crafted fashion. I think differentiable memory might help.
I implemented ideas from this paper in a Jupyter notebook and a 145-line Gist.
DeepMind researchers used linear regression to approximate gradients between each layer in a deep neural network computation graph. This effectively 'decoupled' the layers and enabled the model to update its layers asynchronously. The paper remarks that this technique could be very useful in multi-agent systems, recurrent architectures (to extend backpropagation through time), and distributed/parallel computing. This blog post gives a few more details and has some great GIFs.
I LOVE THIS PAPER! It's the kind of paper that you do not understand at first because it is such an unexpected idea. Then, when you understand what is going on, you think it's a really stupid idea that could not possibly work. Then you read a little further and realize that it really does work. Then you finally start to admire the authors for having the gumption to try out such an insane idea and follow it to fruition.

Approximating parameters in deep networks with binary weights leads to 32x memory savings so there is a lot of interest in binarization. In this paper, researchers binarized a vision model and approximated convolutions with binary add and subtract operations, obtaining a 58x speedup for convolutions. Classification accuracy only dropped 2.9% on AlexNet. The paper's main idea was to train a set of scalar parameters with gradient descent as usual and then convert them to binary representations using the sign function during forward passes.
One of the major drawbacks of running deep vision models on phones and personal computers is computation time. This paper is a big step towards solving this problem. Researchers might be able extend this work to other deep architectures (recurrent nets, for example) that are used for NLP/translation.

Simulating fluid and smoke with physics-based methods requires a lot of compute time. In this paper, researchers trained a 3D ConvNet to approximate the mapping from geometry, pressure, and velocity to pressure in the next step of the simulation and used it to speed up the process.
This paper is exciting for two reasons: 1) it's a really impressive example of training a 3D generative model with a ConvNet and 2) it captures the more general idea that deep learning can approximate arbitrarily complex functions from physics. They could just as easily have modeled a raindrop, a charged plasma, or an evolving quantum system.
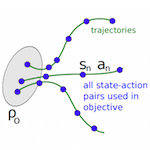
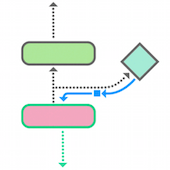
Trust Region Policy Optimization (TRPO) is a procedure for optimizing the policy function, which maps an agent's states to future actions, with respect to the advantage function. The entire first part of this paper is spent deriving a new theoretical result: the Kakade and Langford (2002) policy improvement bound can be extended to general stochastic policies using, in this case, Kullback-Liebler (KL) divergence as a distance measure between the old and new policies. The authors use this theoretical result to suggest a new method for optimizing large, nonlinear policies; think of TRPO as a new way to estimate the gradients in a policy network. Then, they demonstrate that it works well in practice on a variety of tasks including simulated robotic gaits and the Atari games.
This paper, especially the first several pages, is extremely dense. That said, it's a great glimpse at the theoretical frontiers of reinforcement learning. Furthermore, the TRPO algorithm is quite powerful and general so I suspect that it will gain a lot of usage. In particular, OpenAI seems to favor TRPO over other RL learning algorithms. I noticed that the 2015 DQN paper by Mnih et al. had consistently higher scores on the Atari games so I wonder what advantages TRPO has over DQN.
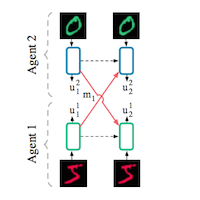
This paper lays out a framework for training dep multi-agent reinforcement learning systems which can communicate with each other to solve tasks. The two main structures it introduces are Reinforced Inter-Agent Learning (RIAL) and Differentiable Inter-Agent Learning (DIAL). The only difference between these is that in DIAL, gradients can flow between agents. Next, the authors use two simple tasks which require communication to show that DIAL has significant advantages of RIAL. Furthermore, sharing parameters between agents (ie training one brain for all agents) turns out to be necessary for convergence in some cases. Adding noise to messages was found to improve communication by forcing messages to be discrete!
This is a very well-written paper which develops an extremely important framework for learning communication in multi-agent systems. There are also several practical notes for training these models. There are only a few papers in this field at this point - this one is probably the best.
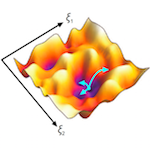
Taken from the abstract: For the squared loss function of a deep linear neural network with any depth and any width, 1) the function is non-convex and non-concave 2) every local minimum is a global minimum, 3) every critical point that is not a global minimum is a saddle point, and 4) there exist "bad" saddle points (where the Hessian has no negative eigenvalue) for networks with more than three layers but not for networks with fewer than three layers.
One of the biggest issues in deep learning is the gap between theory and practice so this paper is an important step in the right direction! Training deep networks used to be considered intractible by many researchers in part because their cost functions are neither convex nor concave. People thought that nets would get 'stuck' in poor local minimal during training. This paper finally lays that issue to rest by showing that (at least in the linear case) deep nets do not have poor local minima.
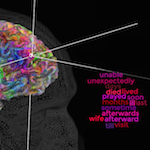
The Gallant lab is awesome. In this study, subjects listened to podcasts while their brain activity was recorded in an fMRI. Researchers then built a model to predict brain activations from transcripts of the podcasts. They found that the model was able to predict brain activity well in many areas of the cortex. To create the semantic map, they reduced the coefficients of the generative model with PCA and somehow mapped regions of the cortex to words that most consistently generated a response.
Definitely check out the interactive 3D 'atlas' they released. The result is interesting because it is one of the most detailed analyses of language in the brain and a really cool glimpse at how the brain organizes information about the world. I also like the paper because it represents a new wave of neuro research aimed at extracting more detailed/precise patterns from data using ML techniques.
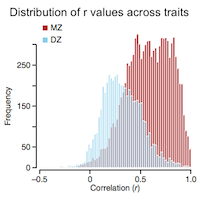
This is a meta study on genetic heritability of traits (both mental and physical) in twins. Heritability across all domains of traits ends up being 49% which leaves the question of nature vs. nurture in a statistically overwhelming deadlock.
I like the paper because it surveys an extremely broad range of traits and thus obtains the highest statistical significance possible for a twin study. Usually these studies are limited by statistical uncertainty, but this one actually has enough data to make some strong claims. I think the most exciting finding is the 49% heritability statistic; either it's the cumulative effect of confirmation bias in the original papers or the impacts of nature and nurture are truly equal.
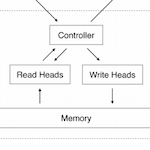
This paper extends the capabilities of neural networks by coupling them to external memory sources, which they can interact with by attentional processes. The system is analagous to a Turing Machine but is end-to-end differentiable and so it can be trained with gradient descent. Neural Turing Machines can learn to infer algorithms such as copy, sort, and associative recall.
In this architecture, memory access requires training read/write heads over the entire memory space, which is impractical for scalable memory. However, it is a huge algorithmic breakthrough in the sense that it incorporates long term memory storage into a differentiable architecture. Giving deep networks access to long term memory will drastically expand their effectiveness in most tasks. The challenge now is to make a long term neural memory architecture which is both differentiable and scalable!
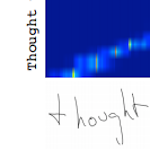
Recurrent neural networks excel at generating complex sequences and this is one of the first major papers to explore their full potential. Graves found that LSTMs can generate text one character at a time and even handwriting one pen coordinate at a time. A note of interest is that Graves trained his models with adaptive weight noise, a form of regularization that is not very common and which I want to learn more about.
The paper is significant because 1) it showcases the huge potential of RNNs and 2) it is one of the first good examples of the Lego Effect (see my blog post inspired by this paper)

This paper addresses an age-old physics question: what is the optimal speed for a person to walk in the rain to minimize the number of raindrops which strike them? The authors make a couple questionable simplifications - for example, they approximate the human as a tall cylinder. This allows them to solve for optimal walking speeds analytically. Apparently, it's best to match the horizontal component of the rain's velocity.
I love this paper not because it's great physics but because it captures the heart and soul of physics. Doing physics is a way of playing with the world around you. It's about asking simple, clever questions and then taking delight in finding a creative solution. While exploring the original question, I was surprised to find dozens of academic papers on the subject. I chose this paper because it's approachable and well written. Probably the best way to answer the original question would be with a sophisticated simulation...but where's the fun in that?
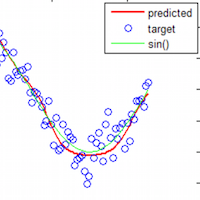
Highlight reel: Standard feedforward networks with as few as one hidden layer and an arbitrary number of hidden units can approximate any measurable function to any degree of accuracy. There are no theoretical constraints on the success of a feedforward network; lack of success is due to insufficient number of hidden units, poor learning, or lack of deterministic relationship between input and target. In depth summary here
This is a math paper so it's pretty dry. It's also one of the most important theoretical pillars of deep learning. Another old paper (Barron, 1993) adds convergence bounds to this theoretical framework, "Because of the economy of number of parameters, order nd instead of n^d, these approximation rates permit satisfactory estimation...even in moderately high-dimensional problems." Knowing these guarantees enables deep learning researchers to use neural networks to make new and ever more creative approximations without worrying about whether there are theoretical restrictions.