
Moviescape: Google Maps for all of Cinema
 Built with Tidepool
Built with TidepoolThe Library of Babel
In Borges’ story The Library of Babel, the universe is an infinite library containing every possible arrangement of letters. Every book that could be written is somewhere in this library: every novel, proof, or love letter. But since there is no catalogue the library is useless. People wander through the twisted stacks of books for lifetimes, finding only gibberish.
The internet often feels like exactly that library. It contains more film criticism, reviews, recommendations, and AI-generated summaries of AI-generated summaries than anyone could read – and yet I, and many others – find it increasingly difficult to find a good new niche movie. Every year, somewhere around 10,000 feature films are produced around the world, and yet most recommendation algorithms point us towards the same top 20 titles. These recommendation algorithms, which promised to help us discover more variety and customization, actually seem to be sharpening the power law distribution of “movies people actually watch.”
The problem is not information – we have more of that than ever before – but structure and geography. We need a map to orient ourselves. And it needs to be spatial, ideally 2D, and organized in such a way that we can use popular movies and categories to orient ourselves, but it is also easy to stumble across a niche/unusual title by accident. The “top 10” lists don’t do this. They are based on the taste of movie critics and Hollywood institutions which, at this point, are wildly out of sync with what most people actually care about or want to watch.
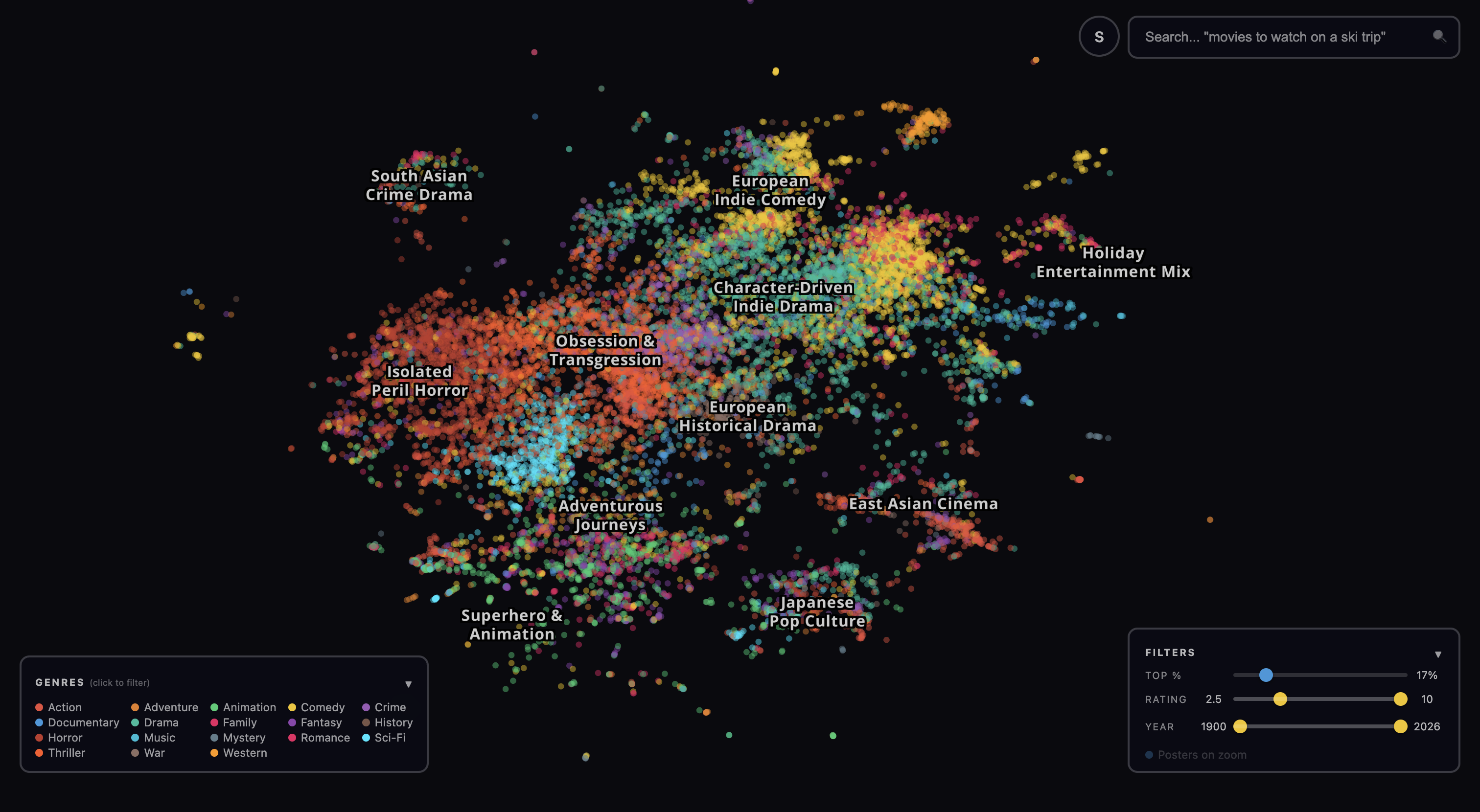
Moviescape is a first attempt at that map. We took 80,000 movies, used AI to characterize their plots, themes and mood, and projected them onto a 2D map that’s zoomable, pannable, and searchable. In this post, we will walk through how this was done and how the map itself can be used to explore the world of cinema and pick out interesting films on the “long tail” of content. We will see that perhaps AI itself is the best tool we have for imposing structure on the chaotic depths of the post-ChatGPT internet.
Making a Navigable UMAP of the top 80k movies
Enrichment of Metadata. We got our list of movies from TMDb (The Movie Database) daily export, a Kaggle dataset with 960,000+ movies updated daily. This dataset contains titles and some metadata such as ratings, number of votes, and year produced. We sorted by vote count and took the top 80k items, giving us a dataset of the most well-known movies, plus a fairly long tail of obscure movies (I hadn’t heard of most movies beyond the 1k mark).
This was a good place to start, but in order to build a better UMAP, we needed to make our context vectors as rich as possible. To this end, we decided to first enrich the metadata with “deep fields” – open-ended descriptions of the plot, mood, what_its_really_about, the_experience, and who_loves_it. These fields were chosen to produce per-movie context vectors that would group movies together not just based on surface-level similarities (title, year made, some basic plot notes), but also around mood, aesthetics, themes, and other things that people might actually care about when organizing a library of the world’s movies.
For example, we want a context vector for Fight Club that doesn’t put the movie next to movies about “fighting” or “clubs.” We want there to be something in the context vector about the unique mood of the movie and, on the theme side – the subterranean identity crisis that men undergo when trapped in a soft, consumerist society.
To this end, we asked Claude Haiku (via the Anthropic Message Batches API, at a cost of about $100 total) to fill in these fields for every movie in the dataset:
Fields:
- id, title, year, rating, vote_count, poster_url, director: pass through from input
- decade: derive from year ("1990s", "2010s", etc.)
- country: primary production country (short form: "USA", "UK", "France", etc.)
- language: full name from the code provided
- genre: exactly ONE from: {', '.join(GENRES)}
- subgenres: 2-3 specific subgenre terms (e.g. "neo-noir", "body horror", "mumblecore")
- cast: top 7 cast in billing order from YOUR knowledge. Empty list if unknown.
Deep fields — write for an embedding model, not an audience. Semantic precision over style:
- plot: 1-2 sentences. Concrete events, setting, social milieu, central conflict.
- mood: 1-2 sentences. Visual/sonic texture. Name the filmmaking tradition.
- what_its_really_about: 2 sentences. Thematic core — philosophical tensions, not plot. Use analytical vocabulary an embedding model can match across films.
- the_experience: 1-2 sentences. Specific emotional/cognitive effect on viewer. Name the feeling precisely.
- who_loves_it: 1 sentence. Audience archetypes by relationship to themes, not demographics.
For Fight Club, the result looked like this:
{
"title": "Fight Club",
"year": 1999,
"genre": "Thriller",
"subgenres": ["psychological thriller", "dark satire", "cult film"],
"plot": "An insomniac office worker and a charismatic soap salesman form
an underground fight club that metastasizes into an anarchist movement,
set in the corporate wastelands of late-90s urban America.",
"mood": "Hyperkinetic editing, industrial noise score, subliminal image
insertions. Late-90s corporate-critique cinema rejecting classical
continuity for punk montage.",
"what_its_really_about": "Masculine identity crisis under late capitalism —
the construction of selfhood through consumption, labor alienation, and
the fantasy that physical violence can restore authentic agency. The film
stages the contradiction between transcendence through destruction and
the recognition that revolutionary violence reproduces the systems it
opposes.",
"the_experience": "Visceral exhilaration followed by moral vertigo. The
film seduces through style and mythology, then ruptures that seduction
through formal disruption and narrative betrayal, leaving the viewer
complicit in both the fantasy's appeal and its bankruptcy.",
"who_loves_it": "Viewers experiencing alienation within corporate
structures, those questioning whether counterculture reproduces the
domination it opposes, and anyone drawn to films that make their own
formal manipulations part of the thematic content."
}
The deep fields are written for the embedding model, not for humans. They’re designed so that two films with shared themes end up as neighbors even if their titles and genres look nothing alike.
Obtaining per-movie context vectors. With the enriched per-movie JSONs in hand, we proceeded to concatenate the fields of each json to create a single per-movie string (as shown below) and then convert these strings into vectors with Voyage AI (voyage-3-large, 512 dimensions). The deep fields dominate the context vectors because they have the most words, but the simpler fields (title, cast, genre) are also present and searchable. Which movies end up as neighbors is mostly driven by the deep fields.
{title} ({year}, {decade}). {country}, {language}.
Directed by {director}, starring {cast}.
{genre}; {subgenres}.
{plot} {mood}
What it's really about: {what_its_really_about}
The experience: {the_experience}
Audience: {who_loves_it}
The full embedding matrix is 80,937 × 512 values, stored as float16 to halve memory (from ~195MB to ~79MB). At runtime, the server loads this matrix into memory once at startup and uses a numpy dot product for search (cosine similarity against the full matrix of movie vectors).
UMAP dimensionality reduction. The last step of the data pipeline involves projecting the 512-dimensional context vectors to 2D using the UMAP (Uniform Manifold Approximation and Projection) algorithm. The result is an approximation of the high-dimensional space that preserves some of the global and local structure while making the overall point cloud viewable in two dimensions.
In order to make the UMAP zoomable and interactive, we decided to plot it on a full-viewport dark Mapbox map. Mapbox comes with nice zoom properties, thumbnail support, and it’s relatively easy to embed coordinates in links. So we chose to plot our UMAP as if each movie coordinate were literally a position on earth with latitude/longitude coordinates. To this end, we scaled the 2D coordinates to latitude/longitude ranges of -30° to +30° lng and -20° to +20° lat so that Mapbox can render them at a reasonable scale.
Running UMAP on 80,937 × 512 vectors takes less than 10 minutes on a laptop. After we got our 2D coordinates, we ran a two-level hierarchical k-means clustering on the points, yielding about 12 large-scale clusters and 80 sub-regions. Then we drew about 20 random samples from each of these regions and used Haiku to name each cluster based on that random sample (eg “French Art House”, “Slasher Horror”, “90s Action”). These labels appear at different zoom levels and are meant to help orient the reader.
Final result. The final result is Google Maps for all movies. It is a dark map full of dots, each corresponding to a different movie. The dots are colored by genre and filterable by IMDB rating, year made, and popularity (top 10%, 50%, etc). The user can also search the corpus of movies with a search bar, and when this happens the dots are all made partially transparent except for the top 200 results, which are rendered with a glow effect. The glow color varies from white to yellow to red to cyan to dark blue, where lighter colors represent higher ranks. Thus the regions of the map with the highest density of relevant results glow white or yellow while other parts of the map look dark. The result looks like a milky way with different densities and brightnesses of stars and is quite beautiful to pan over and explore.

The whole application, data loading, API endpoints, search, and the entire frontend, is a single Python file of about 930 lines, deployed as a Tidepool pod.
Genre clusters
The lion’s share of movies live on a large central landmass of character-driven indie drama and European indie comedy. Bollywood forms its own island to the northwest. Superhero and animation films sit in the south, with Japanese pop culture (anime, tokusatsu, manga adaptations) just below them. Horror and transgressive cinema dominate the west, with action films between them and the center. And floating off to the northeast is a little island of “Holiday Entertainment Mix” movies: whimsical, safe and far from the horror regions.
Of the 80,000+ movies, the majority are dramas of one form or another. There are historical dramas, crime dramas, character studies, and family dramas. The long tail of cinema is not distributed evenly across genres; it is especially rich in character-driven stories. This is partly because dramas are the easiest kind of movie to make (no elaborate sets or special effects required). But another, deeper cause might be that indie filmmakers disproportionately care about families, friendships, and romantic relationships. In short, about our relationships with one another. If you only pay attention to blockbusters and top-1000 movies you might miss this fact.
Zooming in reveals structure that no genre taxonomy would predict. Here are four regions that show what the embedding captures.

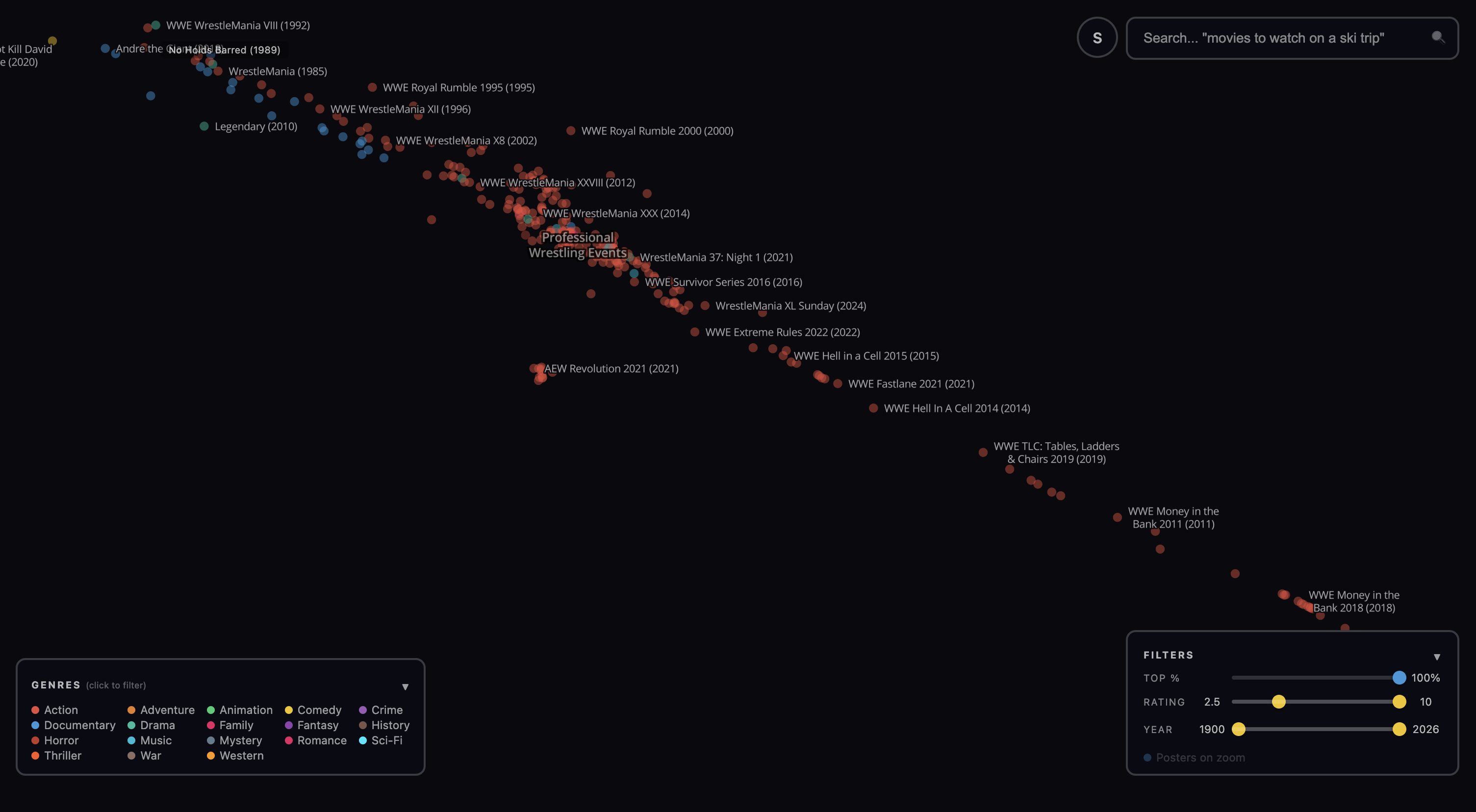
The WWE cluster is interesting because the movies themselves don’t have a TMDb genre tag. Some are classified as “Action”, others as “Drama” or “Documentary.” It was the enrichment step that produced the semantic details needed to produce context vectors with enough similarity to create this little island.
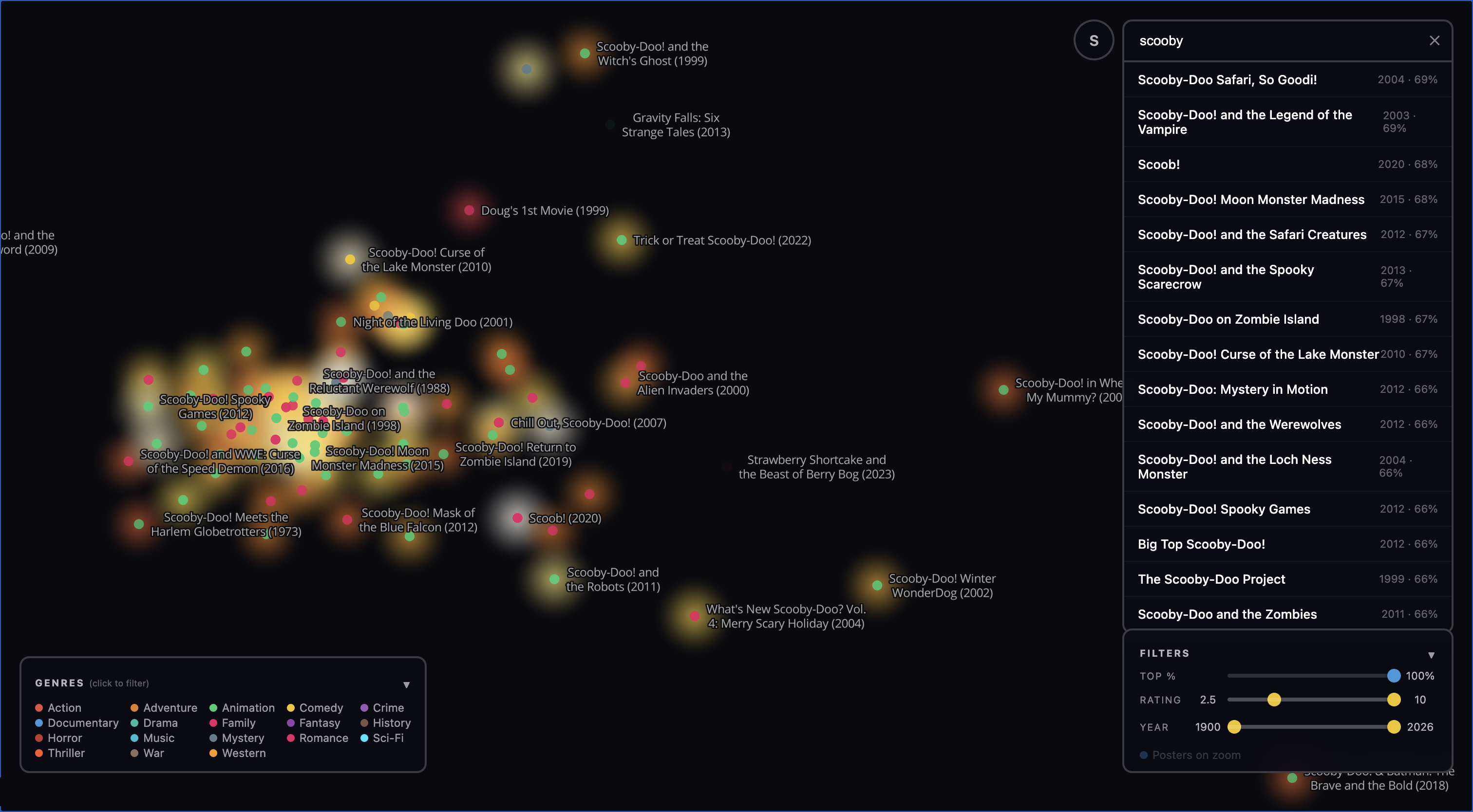
The Scooby-Doo region is also fun because many people know of one or two Scooby-Doo movies, but have not heard of all the others. The fact that a person who likes Scooby-Doo can zoom in on this little region and see how the lesser-known titles relate to the better-known ones shows that the map is working more or less as intended.
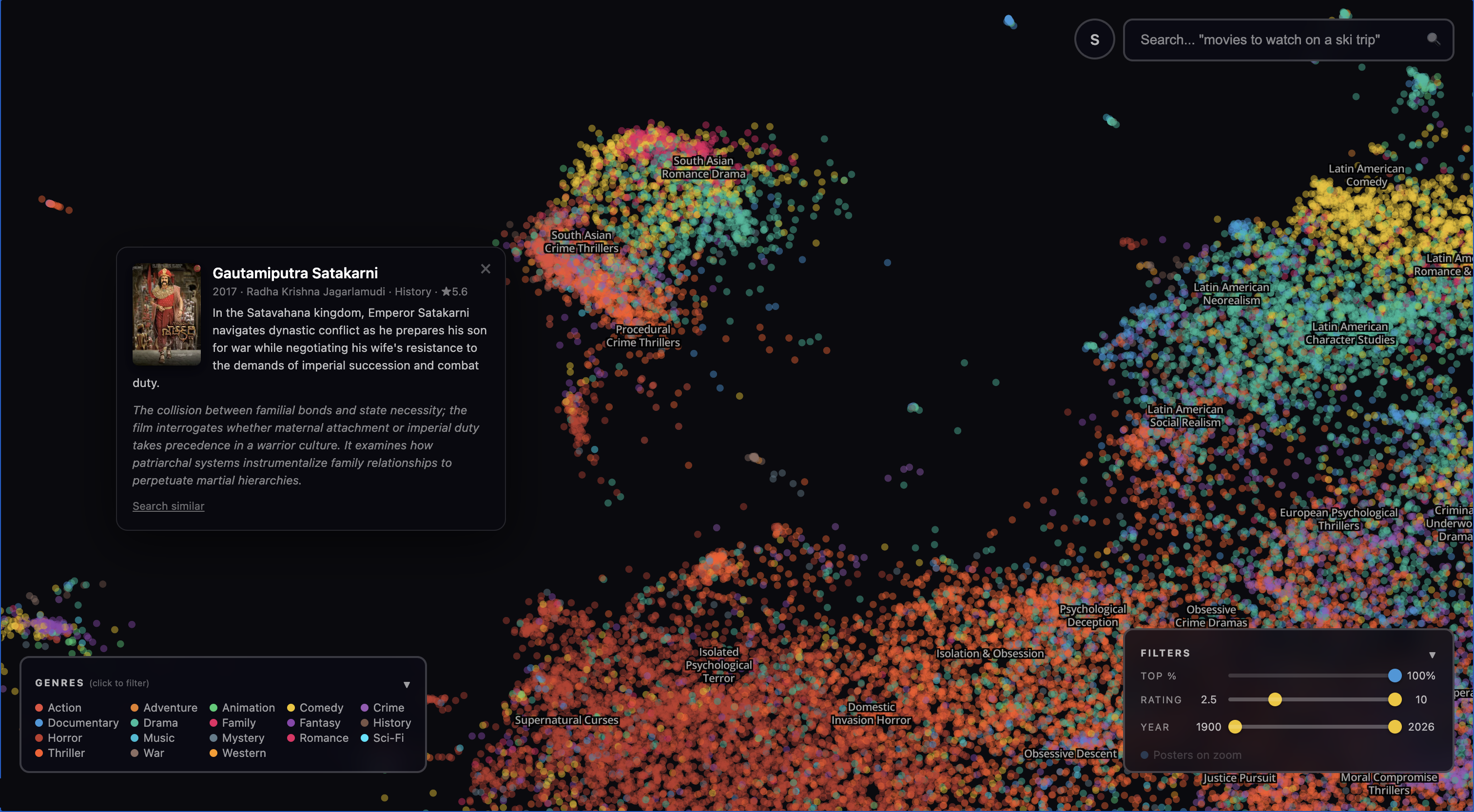
The South Asian island in the bottom right corner isn’t really an island at all, it’s more of an Australia-size continent. It has its own internal structure. There are historical films (Gautamiputra Satakarni), Bollywood romances (Dilwale Dulhania Le Jayenge etc), and Tamil action films (Viduthalai: Part I) each in their own clusters.
Discovering new films. These clusters show the embedding working at medium zoom. But the map is most useful at close zoom, where you can discover individual films you might never have found otherwise.
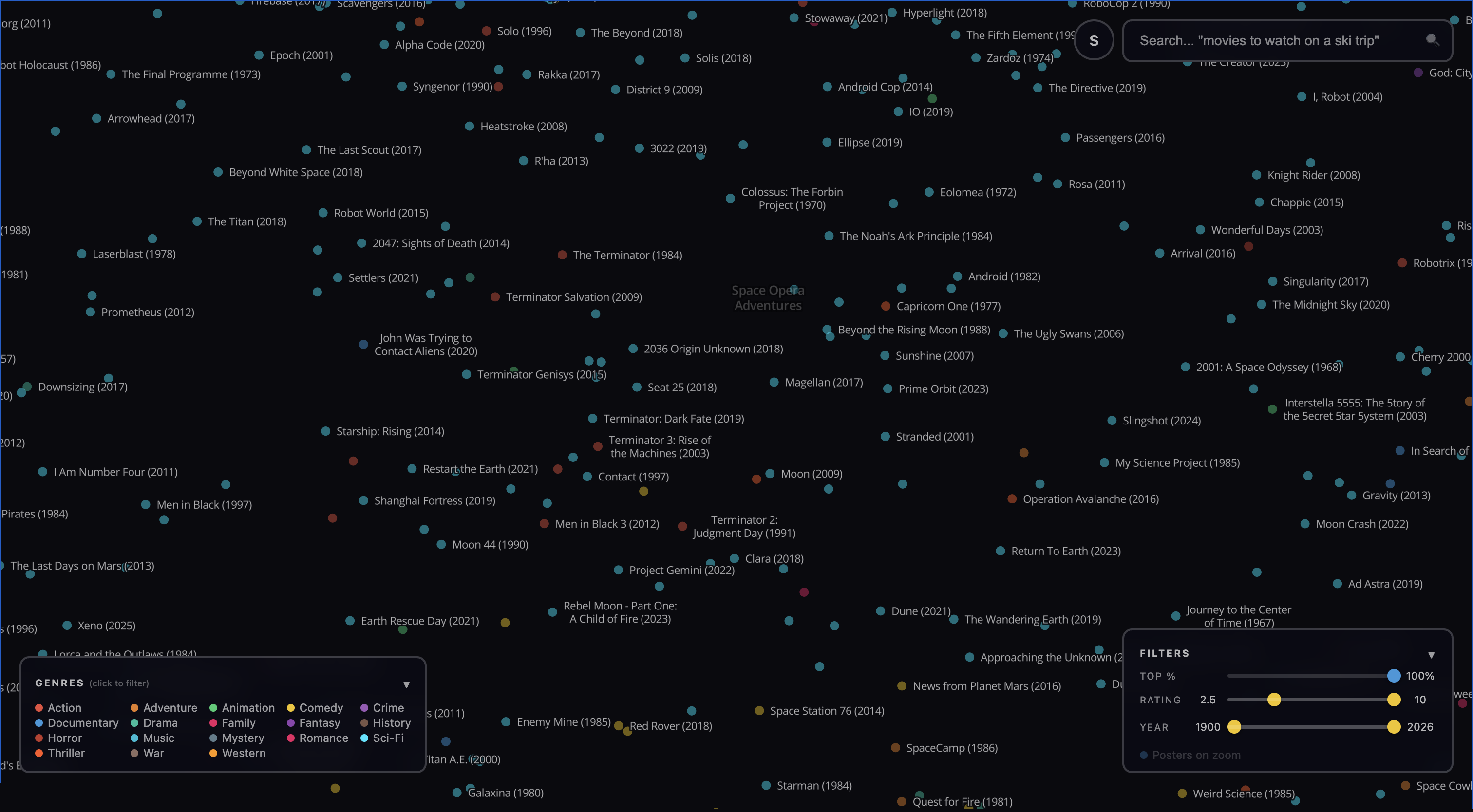
This zoomed-in view is where the embedding really shines. If we just grouped films by genre, The Terminator would be next to other 1980s sci-fi action films. But our embedding puts it next to Ex Machina, Blade Runner, A.I. Artificial Intelligence, and 2001: A Space Odyssey. These films span four decades and range from action movies to slower, more philosophical pieces. But all of them are about what it means to be human in a world where AI is real. You can also see some rarer films in this zoomed-in view: Automata (2014), Singularity (2017), and Alpha Code (2020) all sound like relevant and interesting films for someone who liked The Terminator.
It’s important to note that this map is showing you something different from “people who liked movie X also like the set of movies {Y}”, which is what many recommender systems do. Rather, it shows “the themes, mood, and ideas of movie X are shared by the set of neighbors {Y}”. This is a different and more first-principles way for users to discover new films.
Landscapes are better than feeds
Most of our information today is consumed as part of endless social media scrolling, search result scrolling, or AI chat scrolling. Scrolling is the opposite of exploring a map. It causes us to over-index on the top few elements of a Pareto distribution while missing the long tail. And while the top few elements can indeed be interesting, over a long timeframe this approach to information consumption will homogenize our information diets and cause the long tail of information – where truly unique and interesting elements live – to collapse.
I have long wished that information on the internet from movies, to books, to music, to websites, to really any other data modality were spatially organized. We humans have strong spatial “software” in the sense that we are better at remembering and manipulating information when it is associated with a specific place. Look into, for example, memory palaces and the Method of loci. Interfaces like Moviescape lean into this: they let the user examine a corpus from a bird’s eye view, organize it spatially, and then zoom into the unique regions that hold the greatest interest and appeal. Through spatial layouts like Moviescape we may be able to use AI to bring more signal to the internet rather than less.
Moviescape is live at moviescape.site. The code is on GitHub. This project was built with Tidepool.