
Moviescape: Google Maps for Cinema
Map views are the solution to doomscrolling. A feed shows you a ranked list and hides everything else. A map shows you the whole landscape and lets you wander into the corners that are interesting to you.
 Built with Tidepool
Built with TidepoolThe Library of Babel
In Borges’ story The Library of Babel, the universe is an infinite library containing every possible arrangement of letters. Every book that could be written is somewhere in this library: every novel, proof, or love letter. But since there is no catalogue the library is useless. People wander through the stacks of books for lifetimes, finding only nonsense words.
The internet often feels like exactly that library. It contains more film criticism, reviews, recommendations, and AI-generated slop than anyone could read in a lifetime, and yet I, among others, find it increasingly difficult to find a good new niche movie. Every year, somewhere around 10,000 new feature films are produced, and yet most recommendation algorithms point us towards the same top 5-10 titles. These recommendation algorithms, which promised to help us with variety and personalization, actually seem to be sharpening the power law distribution of “movies people actually watch.”
The problem is not information, as we have more of that than ever before, but rather structure. We need a map to orient ourselves. And it needs to be spatial, ideally 2D, and organized in such a way that we can use popular movies and categories to orient ourselves, but we also want to stumble across niche/unusual titles by accident. And we want to stumble across the right niche titles given the context, not a string of non-sequiturs. The “top 10” lists don’t do this. They are based on the taste of movie critics and Hollywood institutions which, at this point, are wildly out of sync with what most people actually enjoy.
Moviescape is a first attempt at that map. We took 80,000 movies, used AI to characterize their plots, themes and mood, and projected them onto a 2D map that’s zoomable, pannable, and searchable. In this post, we will walk through how this was done and how the map itself can be used to explore the world of cinema and pick out interesting films on the “long tail” of content.
Making a Navigable UMAP of the top 80k movies
Enrichment of Metadata. We got our list of movies from TMDb (The Movie Database) daily export, a Kaggle dataset with 960,000+ movies updated daily. This dataset contains titles and some metadata such as ratings, number of votes, and year produced. We sorted by vote count and took the top 80k items, giving us a dataset of the most well-known movies, plus a fairly long tail of obscure movies (I hadn’t heard of most movies beyond the 1k mark).
This was a good place to start, but in order to build a better UMAP, we needed to make our context vectors as rich as possible. To this end, we decided to first enrich the metadata with “deep fields”, which are open-ended descriptions of the plot, mood, what_its_really_about, and the_experience. These fields were chosen to produce per-movie context vectors that would group movies together not just based on surface-level similarities (title, year made, some basic plot notes), but also around mood, aesthetics, themes, and other things that people might actually care about when organizing a library of the world’s movies.
An example: we want a context vector for Fight Club that doesn’t put the movie next to movies about “fighting” or “clubs.” We want there to be something in the context vector about the unique mood of the movie; something even perhaps about the subterranean identity crisis that men undergo when trapped in a soft, consumerist society.
To this end, we asked Claude Haiku (via the Anthropic Message Batches API, at a cost of about $80) to fill in these fields for every movie in the whole dataset:
Fields:
- id, title, year, rating, vote_count, poster_url, director: pass through from input
- decade: derive from year ("1990s", "2010s", etc.)
- country: primary production country (short form: "USA", "UK", "France", etc.)
- language: full name from the code provided
- genre: exactly ONE from: {Action, Adventure, Animation, Comedy, Crime,
Documentary, Drama, Family, Fantasy, History, Horror, Music, Mystery,
Romance, Sci-Fi, Thriller, War, Western}
- subgenres: 2-3 specific subgenre terms (e.g. "neo-noir", "body horror", "mumblecore")
- cast: top 7 cast in billing order from YOUR knowledge. Empty list if unknown.
Deep fields — write for an embedding model, not an audience. Semantic precision over style:
- plot: 1-2 sentences. Concrete events, setting, social milieu, central conflict.
- mood: 1-2 sentences. Visual/sonic texture. Name the filmmaking tradition.
- what_its_really_about: 2 sentences. Thematic core — philosophical tensions, not plot.
Use analytical vocabulary an embedding model can match across films.
- the_experience: 1-2 sentences. Specific emotional/cognitive effect on viewer.
Name the feeling precisely.
Geographic fields (NEVER null — use 0.0 only in worst-case):
- setting_lat/setting_lng: primary setting location of the film.
For fantastical settings, use the most relevant real-world location.
- origin_lat/origin_lng: where the film was primarily produced (studio/filming location).
For Fight Club, the result looked like this:
{
"decade": "1990s",
"cast": ["Brad Pitt", "Edward Norton", "Helena Bonham Carter",
"Meat Loaf", "Jared Leto", "Zach Grenier", "Holt McCallany"],
"country": "USA",
"language": "English",
"genre": "Drama",
"subgenres": ["psychological thriller", "dark satire", "neo-noir"],
"plot": "A depressed office worker forms an underground fight club with
a charismatic soap salesman, escalating from bare-knuckle brawling into
anti-capitalist domestic terrorism across late-1990s urban America.",
"mood": "Grimy fluorescent lighting and subliminal flash frames create a
dissociative fever dream. Dust Brothers electronic score pulses
underneath Fincher's precise, clinical compositions.",
"what_its_really_about": "The crisis of masculinity in consumer capitalism
— how identity dissolves when defined solely by possessions and
white-collar labor. Explores whether destruction is creation's
prerequisite or its narcissistic shadow.",
"the_experience": "Mounting paranoia and anarchic glee that curdles into
genuine dread. The twist reframes everything, producing the vertiginous
sensation of having been complicit in your own deception.",
"setting_lat": 40.7128, "setting_lng": -74.006,
"origin_lat": 34.0522, "origin_lng": -118.2437
}
The deep fields are written for the embedding model, not for humans. They’re designed so that two films with shared themes end up as neighbors even if their titles and genres look nothing alike.
Obtaining per-movie context vectors. With the enriched per-movie JSONs in hand, we proceeded to concatenate the fields of each json to create a single per-movie string and then convert it into vectors with Voyage AI (voyage-3-large, 512 dimensions). The deep fields dominate the context vectors because they have the most words, but the simpler fields (title, cast, genre) are also present and searchable. Which movies end up as neighbors is mostly driven by the deep fields.
{title} ({year}, {decade}). {country}, {language}.
Directed by {director}, starring {cast}.
{genre}; {subgenres}.
{plot} {mood}
What it's really about: {what_its_really_about}
The experience: {the_experience}
The full embedding matrix is 80,000 × 512 values, stored as float16 to halve memory (from ~160MB to ~80MB). At runtime, the server loads this matrix into memory once at startup and uses a numpy dot product for search (cosine similarity against the full matrix of movie vectors - sometimes augmented with HyDE).
UMAP dimensionality reduction. The last step of the data pipeline involves projecting the 512-dimensional context vectors to 2D using UMAP. The result is an approximation of the high-dimensional space that preserves some of the global and local structure while making the overall point cloud viewable in two dimensions.
In order to make the UMAP zoomable and interactive, we decided to plot it on a full-viewport dark Mapbox map. Mapbox comes with nice zoom properties, thumbnail support, and it’s relatively easy to embed coordinates in links. So we chose to plot our UMAP as if each movie coordinate were literally a position on earth with latitude/longitude coordinates. To this end, we scaled the 2D coordinates to latitude/longitude ranges of -30° to +30° lng and -20° to +20° lat so that Mapbox can render them at a reasonable scale.
Running UMAP on 80,000 × 512 vectors takes less than 10 minutes on a laptop. After we got our 2D coordinates, we ran a two-level hierarchical k-means clustering on the points, yielding about 12 large-scale clusters and 80 sub-regions. Then we drew about 50 random samples from each of these regions and used Haiku to name each cluster based on that random sample (eg “French Art House”, “Slasher Horror”, “90s Action”). These labels appear at different zoom levels and are meant to help orient the reader.
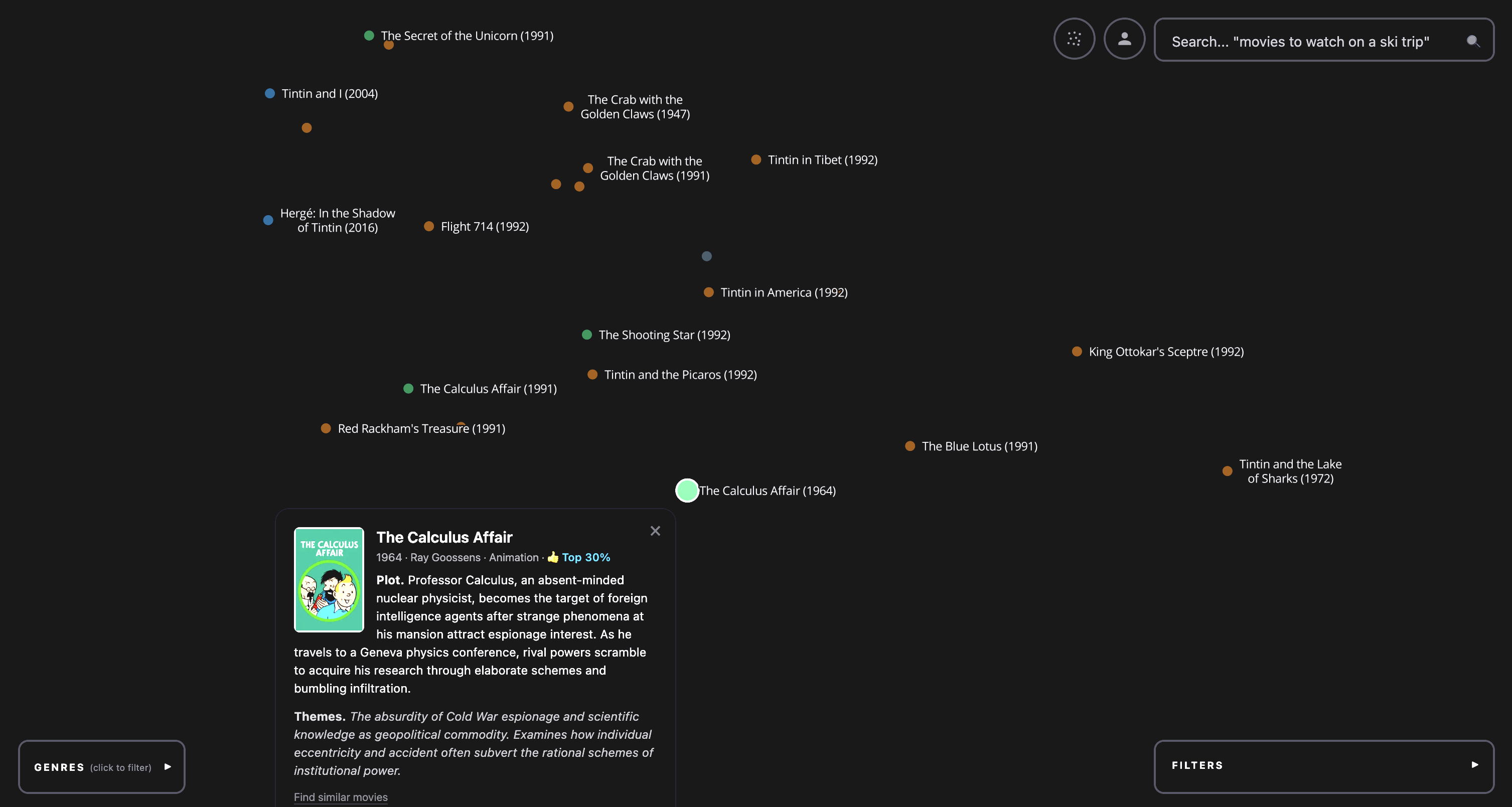
Final result. The final result is Google Maps for all movies. It is a dark map full of dots, each corresponding to a different movie. The dots are colored by genre and filterable by IMDB rating, year made, and popularity (top 10%, 50%, etc). The user can also search the corpus of movies with a search bar, and when this happens the dots are all made partially transparent except for the top 200 results, which are rendered with a glow effect. The result looks like a milky way with different densities and brightnesses of stars and is quite beautiful to pan over and explore.

The whole application (data loading, API endpoints, search, and the entire frontend) is about 2,000 lines of Python, deployed as a Tidepool pod.
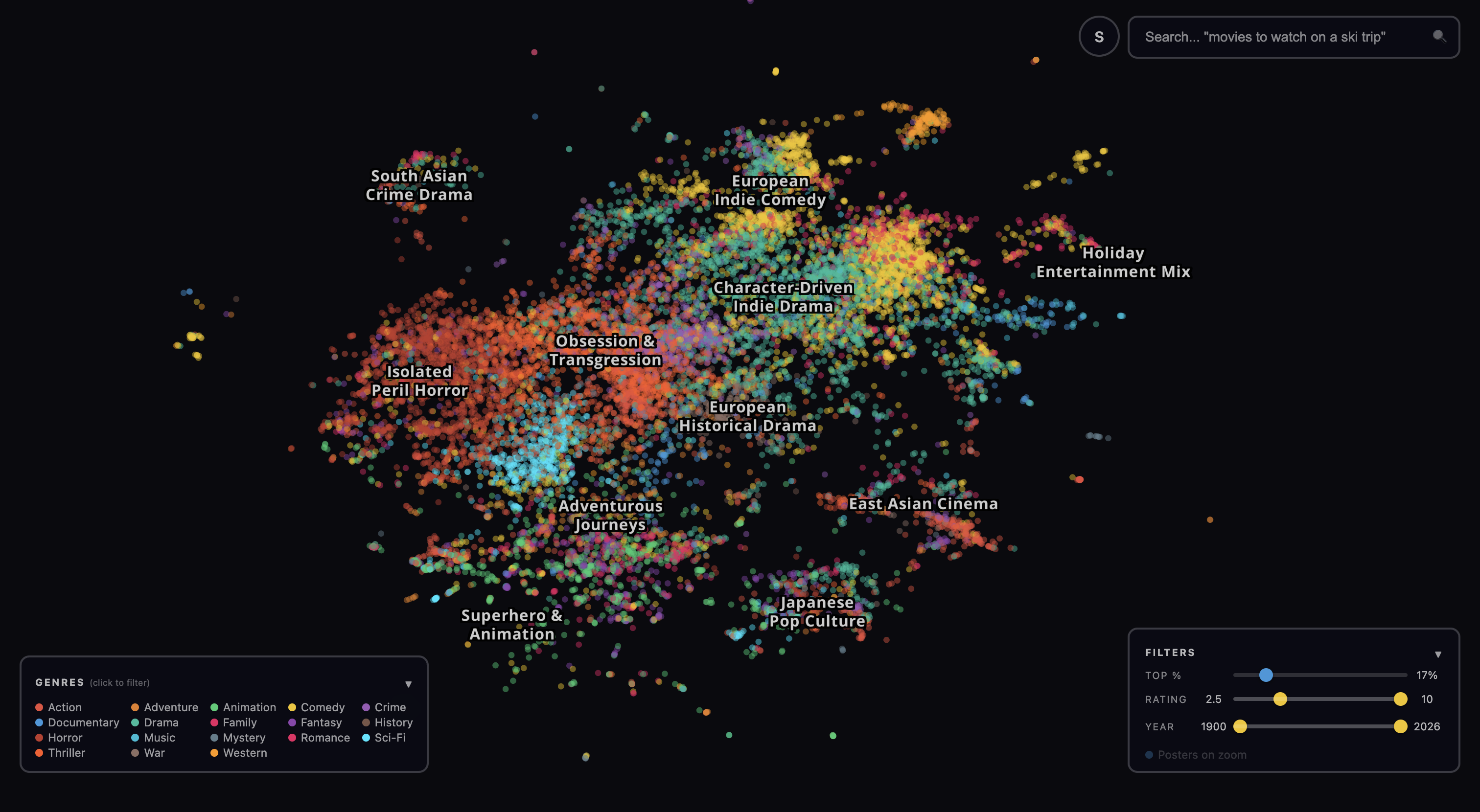
Genre clusters
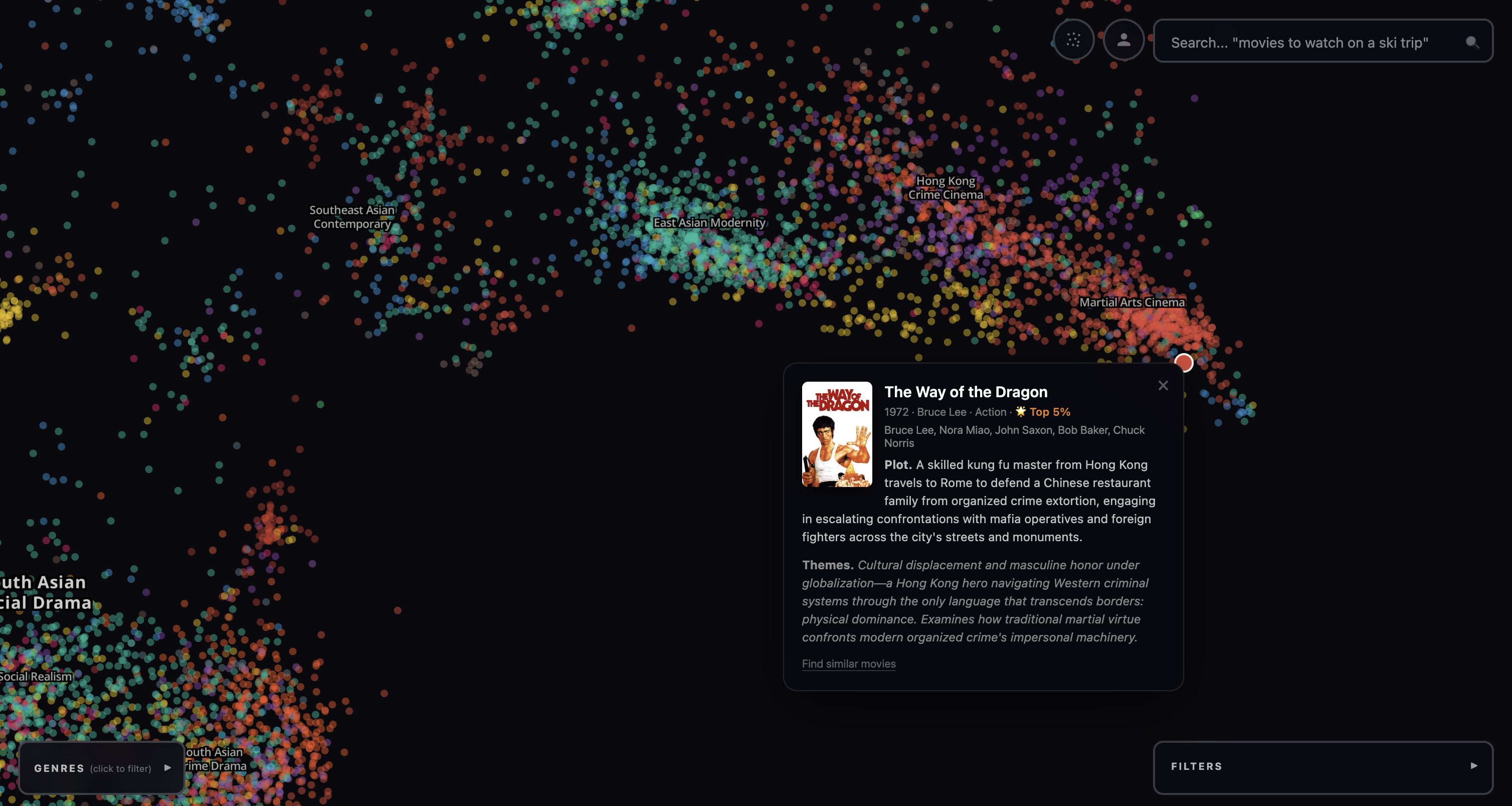
The lion’s share of movies live on a large central landmass of European Art Cinema, Character-Driven Indie Drama, and French Social Drama. Italian Cinema and Screwball & Deception sit to the northwest; Eastern European Cinema to the north; Classic Animation & Holiday floats off to the northeast. Cult B-Movies and East Asian Cinema stretch east. South Asian Social Drama forms its own island to the southeast.
Of the 80,000+ movies, the majority are dramas of one form or another. There are historical dramas, crime dramas, character studies, and family dramas. The long tail of cinema is not distributed evenly across genres; it is especially rich in character-driven stories. This is partly because dramas are the easiest kind of movie to make (no elaborate sets or special effects required). But another, deeper cause might be that indie filmmakers disproportionately care about families, friendships, and romantic relationships. In short, about our relationships with one another. If you only pay attention to blockbusters and top-1000 movies you might miss this fact.
Zooming in reveals structure that no genre taxonomy would predict. Here are four regions that show what the embedding captures.

Globe view. Moviescape also has a globe view that plots each movie at the real-world location where it is set or was filmed. This turns the thematic map into a geographic one: you can explore what movies were made or set in a given city. In the last two panes I filter for just top movies, so you can see how a person could discover “the best movies made/set in Paris.”
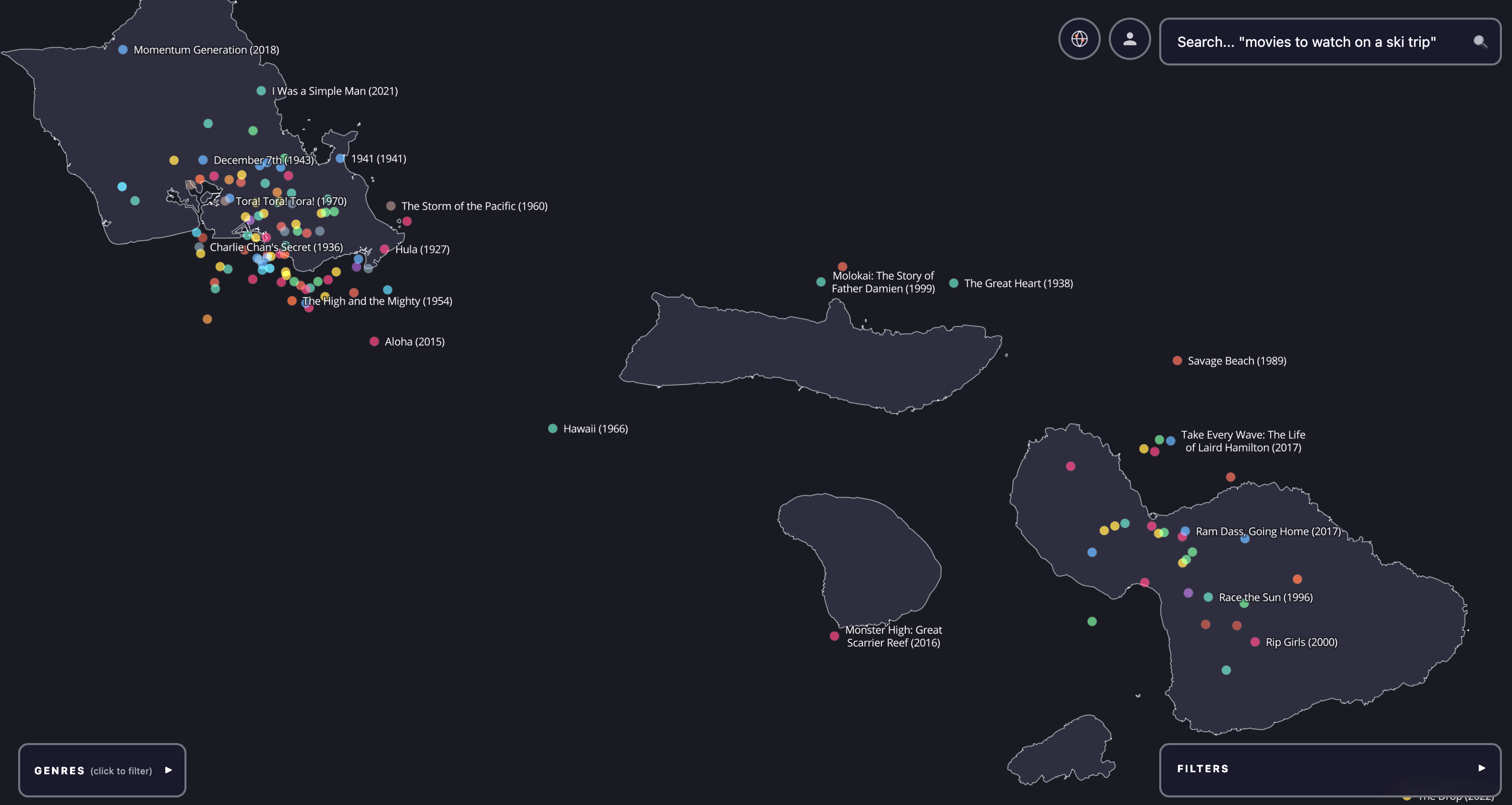
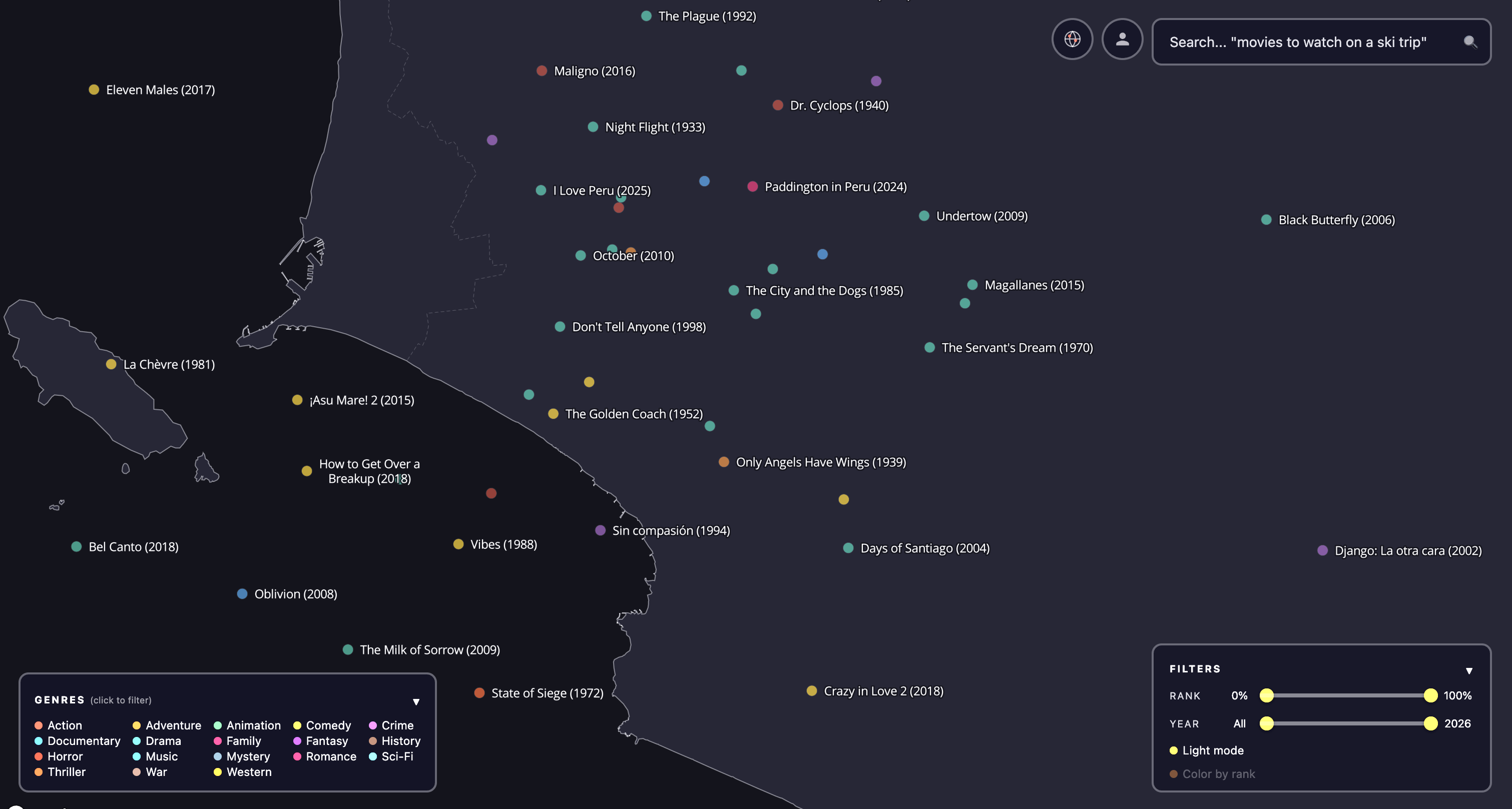
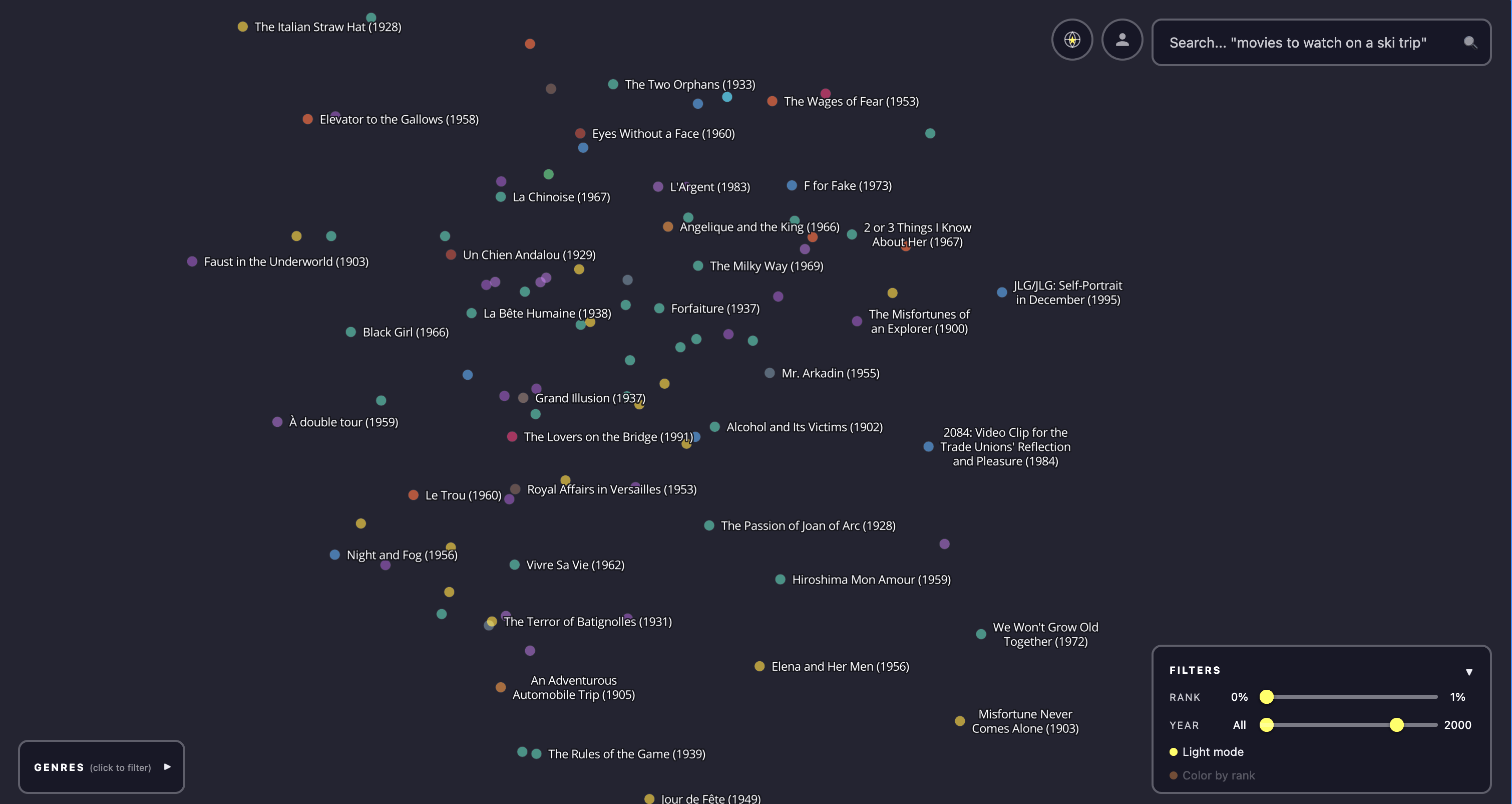
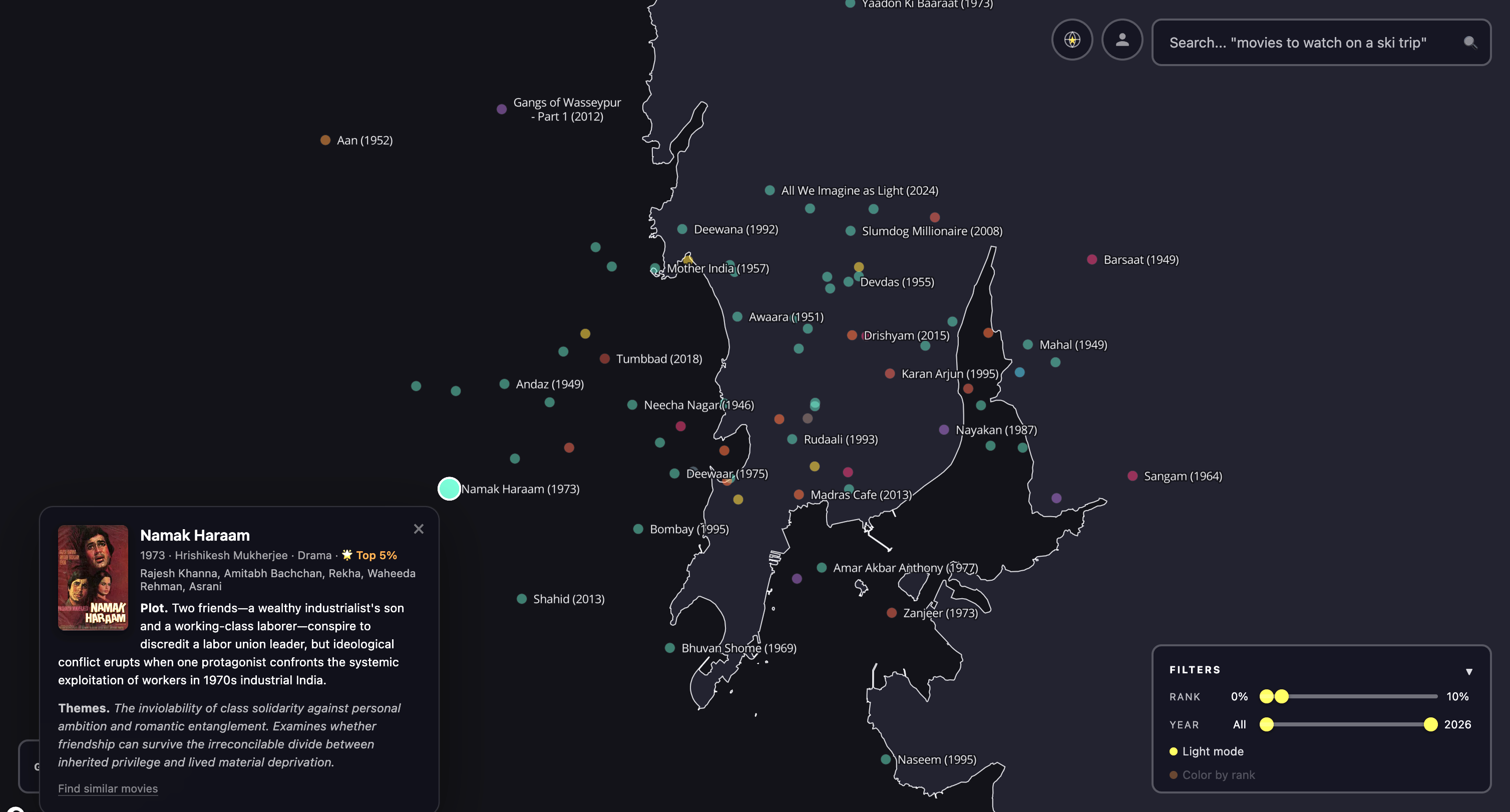
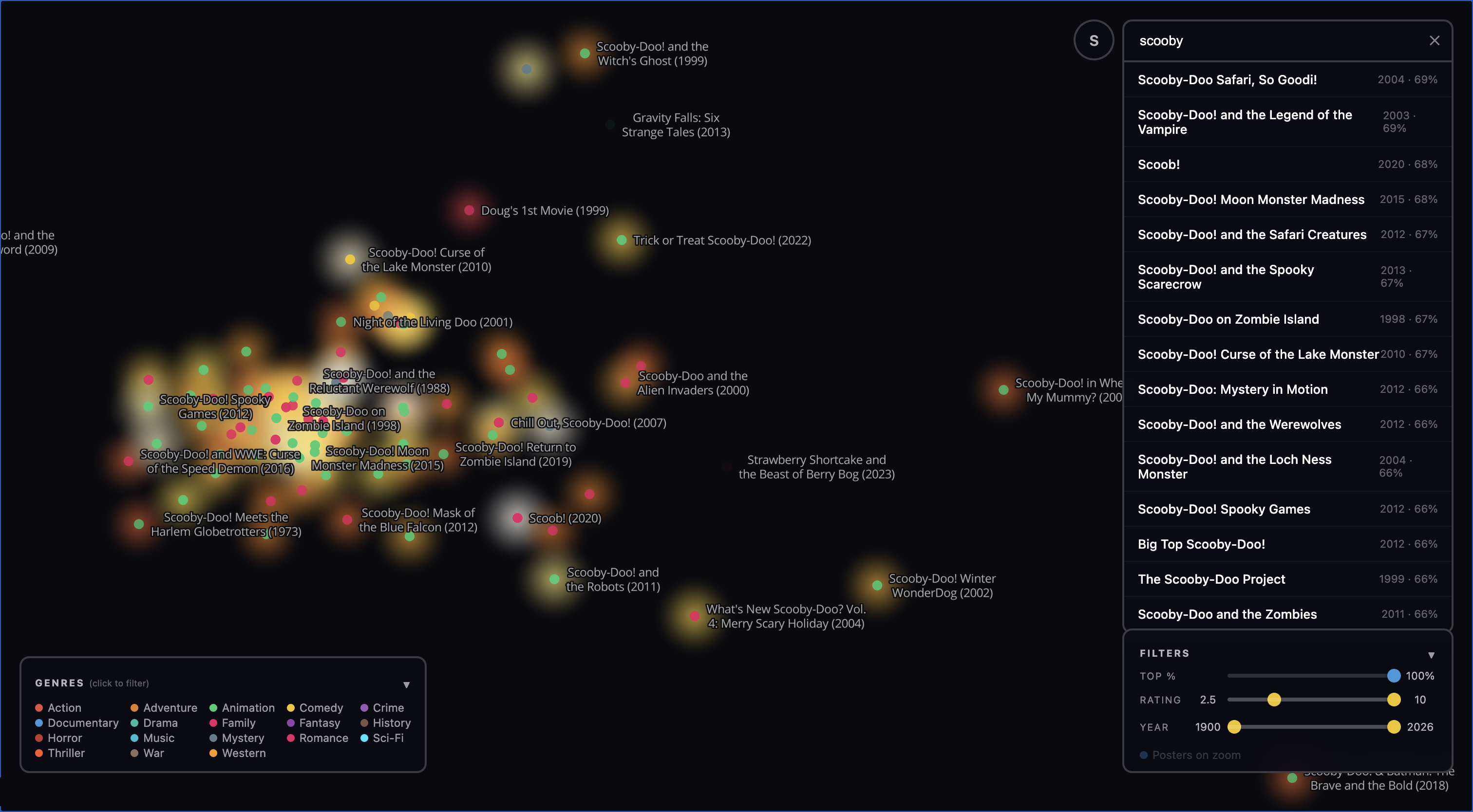
Discovering new films. The clusters above show the embedding working at medium zoom. But the map is most useful at close zoom, where you can stumble across individual films you might never have found otherwise.
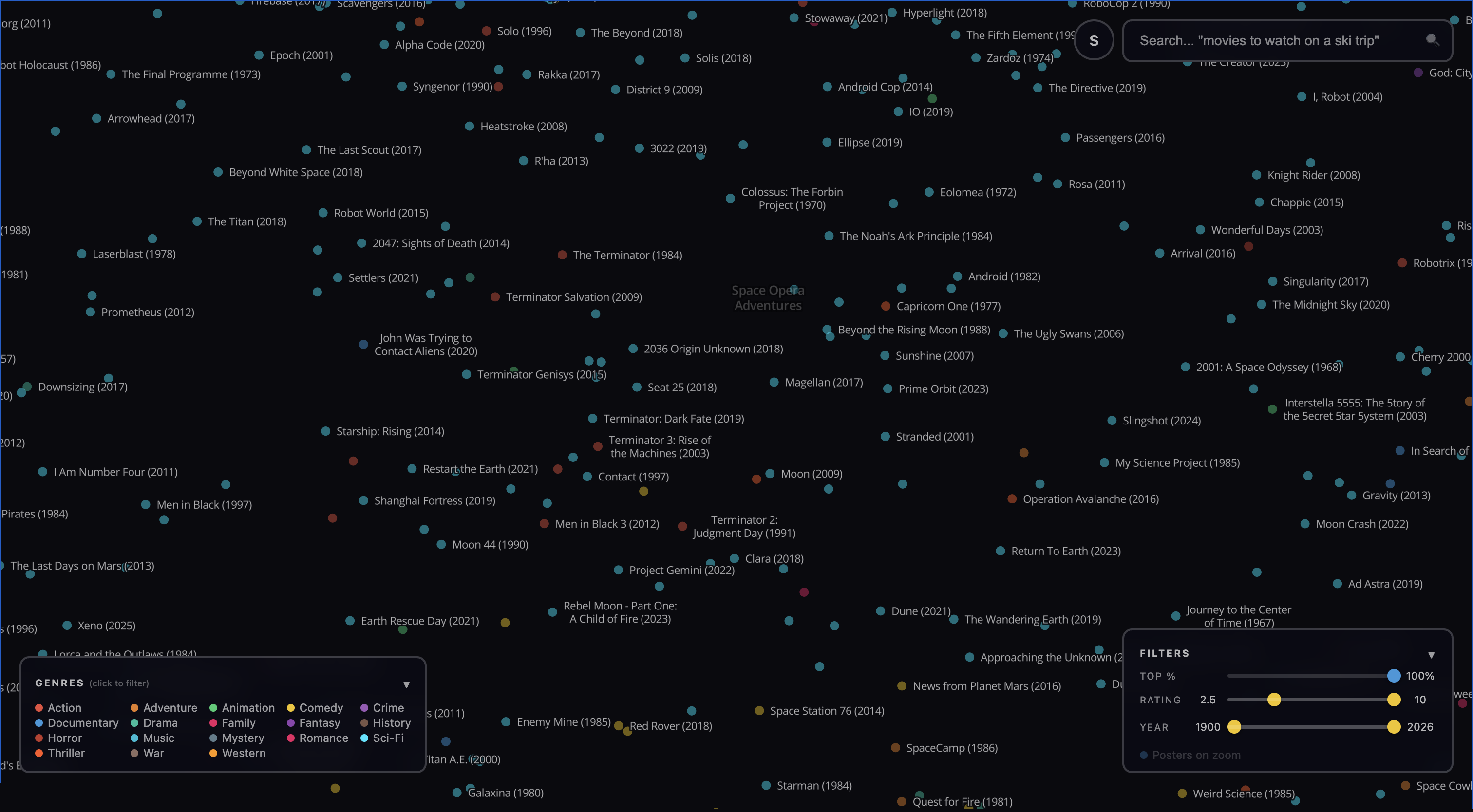
It’s important to note that this map is showing you something different from “people who liked movie X also like the set of movies {Y}”, which is what many recommender systems do. Rather, it shows “the themes, mood, and ideas of movie X are shared by the set of neighbors {Y}”. This is a different and more first-principles way for a curious person to discover new films.
Maps are better than feeds
Most of our information today is consumed as part of endless social media scrolling, search result scrolling, or AI chat scrolling. Scrolling is the opposite of exploring a map. It causes us to over-index on the top few elements of a Pareto distribution while missing the long tail. And while the top few elements can indeed be interesting, over a long timeframe this approach to information consumption will homogenize our information diets and cause the long tail of information, where truly unique and interesting elements live, to collapse.
I have long wished that information on the internet from movies, to books, to music, to websites, to really any other data modality were spatially organized. We humans have strong spatial “software” in the sense that we are better at remembering and manipulating information when it is associated with a specific place. Look into, for example, memory palaces and the Method of loci. Interfaces like Moviescape take advantage of these spatial intuitions: they let the user examine a corpus from a bird’s eye view, organize it spatially, and then zoom into the unique regions that hold the greatest interest and appeal. I am optimistic that this makes for a fundamentally better and more intuitive user experience. Moviescape is just the beginning!
Moviescape is live at moviescape.site. The code is on GitHub. This project was built with Tidepool.